An Investigation of Warning Erroneous Chat Translations in Cross-lingual Communication

0

Sign in to get full access
Overview
- This paper investigates the problem of erroneous translations in cross-lingual chat communication.
- The researchers explore techniques to detect and warn users about potentially inaccurate translations.
- They evaluate their methods on real-world chat data and provide insights for improving translation quality in cross-lingual conversations.
Plain English Explanation
When people chat online with someone who speaks a different language, the chat messages are often automatically translated. However, these translations can sometimes be incorrect or misleading. This paper looks at ways to identify and warn users about potentially faulty translations in cross-lingual chat conversations.
The researchers developed methods to analyze the chat messages and detect when the translations might be unreliable. For example, their system can spot unusual language patterns or inconsistencies that suggest the translation is likely inaccurate. When the system detects a potential translation error, it provides a warning to the chat participants so they can be aware of the issue.
By testing their techniques on real chat data, the researchers were able to evaluate how well their approach works in practice. Their findings offer insights that could help improve the quality of translations in cross-lingual communication and ensure people understand each other correctly, even when using automatic translation tools.
Technical Explanation
The paper presents a system for detecting erroneous translations in cross-lingual chat conversations. The authors first define a set of linguistic features that can indicate potential translation problems, such as unusual word choices, grammatical errors, and inconsistencies across messages.
They then train machine learning models to classify chat messages as either correctly or incorrectly translated based on these features. When the system detects a potentially faulty translation, it triggers a warning to the chat participants to alert them of the issue.
The researchers evaluate their approach on a dataset of real-world chat logs covering multiple language pairs. Their results show that the system can identify erroneous translations with reasonable accuracy, outperforming several baseline methods.
Critical Analysis
The paper provides a valuable contribution to the challenge of ensuring high-quality translations in cross-lingual communication. However, the authors acknowledge that their approach has some limitations. For example, the linguistic features they use may not capture all types of translation errors, and the performance of the models could be affected by factors like domain-specific language or informal chat styles.
Additionally, the paper does not explore the user experience implications of displaying translation warnings to chat participants. It would be important to understand how such warnings are perceived and whether they effectively help users identify and resolve communication issues.
Further research could investigate more advanced techniques for translation error detection, such as leveraging contextual information or incorporating feedback from users. Exploring ways to seamlessly integrate translation quality assurance into the chat experience would also be a valuable direction for future work.
Conclusion
This paper presents a novel approach for detecting and warning users about erroneous translations in cross-lingual chat conversations. By analyzing linguistic features of the chat messages, the system can identify potentially inaccurate translations and alert the participants. The researchers' evaluation on real-world data demonstrates the potential of their technique to improve the quality of communication in multilingual settings.
While the paper has some limitations, it offers important insights and a foundation for further advancing the state of the art in translation quality assurance for interactive applications. Addressing the challenges of ensuring accurate and reliable translations remains a crucial task for enabling effective cross-cultural exchange and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Investigation of Warning Erroneous Chat Translations in Cross-lingual Communication
Yunmeng Li, Jun Suzuki, Makoto Morishita, Kaori Abe, Kentaro Inui
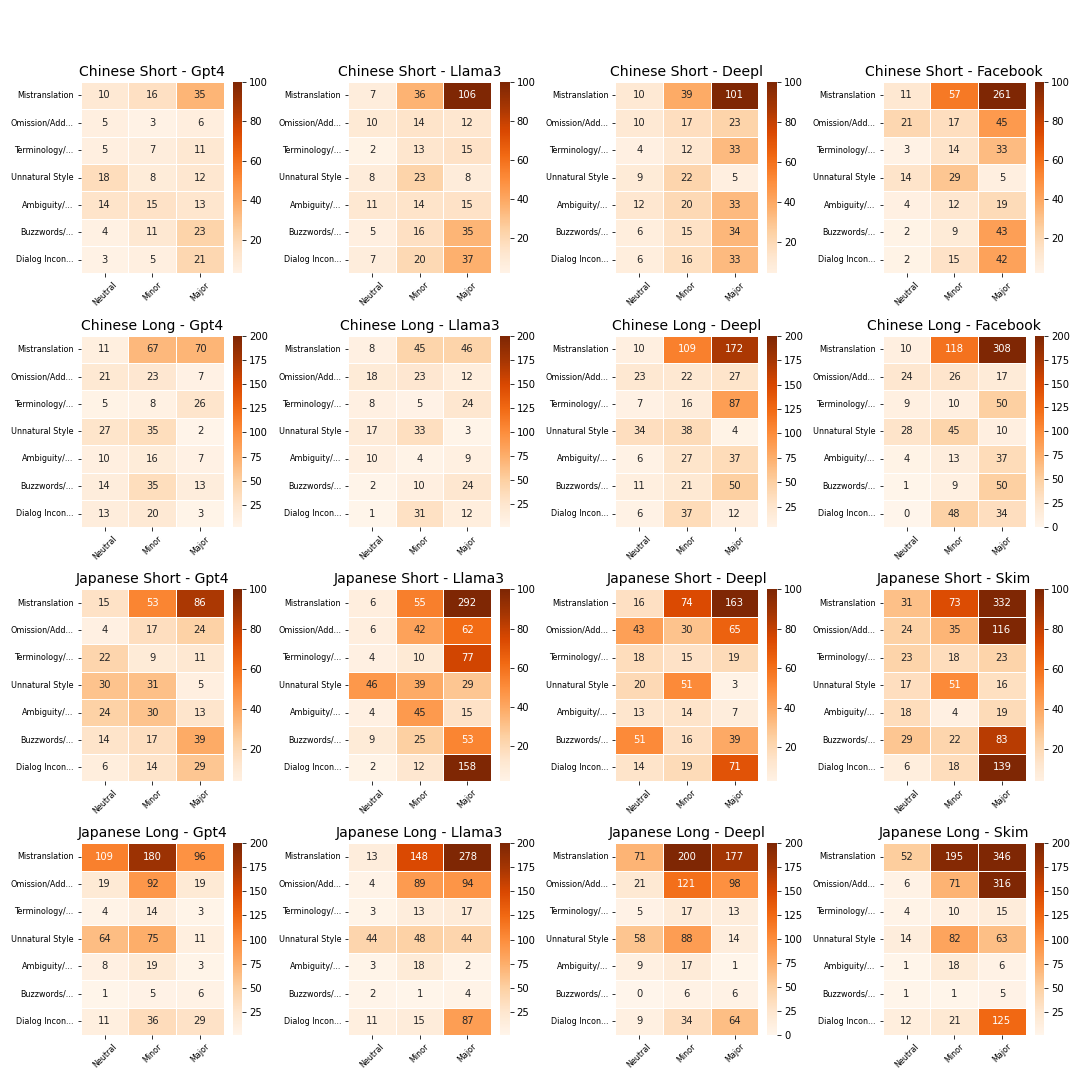
The complexities of chats pose significant challenges for machine translation models. Recognizing the need for a precise evaluation metric to address the issues of chat translation, this study introduces Multidimensional Quality Metrics for Chat Translation (MQM-Chat). Through the experiments of five models using MQM-Chat, we observed that all models generated certain fundamental errors, while each of them has different shortcomings, such as omission, overly correcting ambiguous source content, and buzzword issues, resulting in the loss of stylized information. Our findings underscore the effectiveness of MQM-Chat in evaluating chat translation, emphasizing the importance of stylized content and dialogue consistency for future studies.
Read more8/29/2024
0
MQM-Chat: Multidimensional Quality Metrics for Chat Translation
Yunmeng Li, Jun Suzuki, Makoto Morishita, Kaori Abe, Kentaro Inui
The complexities of chats pose significant challenges for machine translation models. Recognizing the need for a precise evaluation metric to address the issues of chat translation, this study introduces Multidimensional Quality Metrics for Chat Translation (MQM-Chat). Through the experiments of five models using MQM-Chat, we observed that all models generated certain fundamental errors, while each of them has different shortcomings, such as omission, overly correcting ambiguous source content, and buzzword issues, resulting in the loss of stylized information. Our findings underscore the effectiveness of MQM-Chat in evaluating chat translation, emphasizing the importance of stylized content and dialogue consistency for future studies.
Read more8/30/2024

0
The Multi-Range Theory of Translation Quality Measurement: MQM scoring models and Statistical Quality Control
Arle Lommel, Serge Gladkoff, Alan Melby, Sue Ellen Wright, Ingemar Strandvik, Katerina Gasova, Angelika Vaasa, Andy Benzo, Romina Marazzato Sparano, Monica Foresi, Johani Innis, Lifeng Han, Goran Nenadic
The year 2024 marks the 10th anniversary of the Multidimensional Quality Metrics (MQM) framework for analytic translation quality evaluation. The MQM error typology has been widely used by practitioners in the translation and localization industry and has served as the basis for many derivative projects. The annual Conference on Machine Translation (WMT) shared tasks on both human and automatic translation quality evaluations used the MQM error typology. The metric stands on two pillars: error typology and the scoring model. The scoring model calculates the quality score from annotation data, detailing how to convert error type and severity counts into numeric scores to determine if the content meets specifications. Previously, only the raw scoring model had been published. This April, the MQM Council published the Linear Calibrated Scoring Model, officially presented herein, along with the Non-Linear Scoring Model, which had not been published before. This paper details the latest MQM developments and presents a universal approach to translation quality measurement across three sample size ranges. It also explains why Statistical Quality Control should be used for very small sample sizes, starting from a single sentence.
Read more6/11/2024

0
Fine-Tuned Machine Translation Metrics Struggle in Unseen Domains
Vil'em Zouhar, Shuoyang Ding, Anna Currey, Tatyana Badeka, Jenyuan Wang, Brian Thompson
We introduce a new, extensive multidimensional quality metrics (MQM) annotated dataset covering 11 language pairs in the biomedical domain. We use this dataset to investigate whether machine translation (MT) metrics which are fine-tuned on human-generated MT quality judgements are robust to domain shifts between training and inference. We find that fine-tuned metrics exhibit a substantial performance drop in the unseen domain scenario relative to metrics that rely on the surface form, as well as pre-trained metrics which are not fine-tuned on MT quality judgments.
Read more6/5/2024