Fine-Tuned Machine Translation Metrics Struggle in Unseen Domains

0

Sign in to get full access
Overview
- This paper investigates the performance of fine-tuned machine translation metrics on unseen domains, finding that they struggle to accurately assess translation quality in these scenarios.
- The authors highlight the importance of having robust translation evaluation metrics that can handle diverse and changing domains, as this is critical for real-world applications.
- They propose several directions for future research to address the limitations of current fine-tuned metrics.
Plain English Explanation
Automatic metrics are used to evaluate the quality of machine translations, but this paper shows that these metrics can struggle when tested on new types of content that they haven't been trained on before.
The key issue is that translation quality can vary a lot depending on the specific domain or subject matter. Metrics that are fine-tuned on limited datasets may perform well on that data, but then fail to generalize when applied to very different content.
This is a problem because in the real world, machine translation systems need to handle all kinds of text, from news articles to legal documents to social media posts. Relying on metrics that can't adapt to new domains could lead to inaccurate assessments of translation quality and hinder the development of better systems.
The paper proposes several directions for future research to address this challenge, such as developing metrics that can better handle domain shifts or using techniques like few-shot learning to quickly adapt metrics to new scenarios.
Technical Explanation
The paper first provides an overview of different types of machine translation evaluation metrics, including reference-based metrics like BLEU and METEOR, as well as newer fine-tuned metrics.
The authors then present experiments where they test the performance of several fine-tuned metrics on "unseen" domains - content that is significantly different from the data the metrics were trained on. They find that the fine-tuned metrics struggle to accurately assess translation quality in these scenarios, often performing worse than simpler reference-based metrics.
Through further analysis, the paper identifies several key factors that contribute to the fine-tuned metrics' lack of robustness, including domain mismatch, data scarcity, and inherent biases in the training process. The authors argue that addressing these limitations is crucial for developing translation evaluation systems that can keep pace with the evolving needs of real-world applications.
Critical Analysis
The paper makes a compelling case that fine-tuned machine translation metrics, while showing promise on in-domain data, have significant limitations when it comes to handling unseen domains. This is an important finding, as it highlights a potential blind spot in the field's reliance on these advanced metrics.
That said, the paper does not explore in depth the specific reasons why the fine-tuned metrics falter in these cases. The authors attribute it to factors like domain mismatch and data scarcity, but a more detailed investigation into the underlying causes could have provided additional insights.
Additionally, while the paper proposes several directions for future research to address these limitations, it does not delve into the technical or practical challenges of implementing these solutions. For example, developing "multi-range" metrics that can handle diverse domains may require significant dataset curation and model engineering efforts.
Overall, the paper makes a valuable contribution by shining a light on an important limitation of current fine-tuned translation metrics. Continued research in this area, as suggested by the authors, could lead to more robust and adaptable evaluation tools that can keep pace with the evolving needs of machine translation systems.
Conclusion
This paper highlights a crucial limitation of fine-tuned machine translation metrics: their struggle to accurately assess translation quality in unseen domains. As machine translation systems are increasingly deployed in real-world applications with diverse content, the need for robust, domain-agnostic evaluation metrics becomes increasingly important.
The authors' findings call for further research to develop more adaptable translation evaluation approaches, such as techniques that can quickly adjust to new domains or methods that can better handle domain shifts. Addressing this challenge could lead to significant improvements in the development and deployment of high-quality machine translation systems across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-Tuned Machine Translation Metrics Struggle in Unseen Domains
Vil'em Zouhar, Shuoyang Ding, Anna Currey, Tatyana Badeka, Jenyuan Wang, Brian Thompson
We introduce a new, extensive multidimensional quality metrics (MQM) annotated dataset covering 11 language pairs in the biomedical domain. We use this dataset to investigate whether machine translation (MT) metrics which are fine-tuned on human-generated MT quality judgements are robust to domain shifts between training and inference. We find that fine-tuned metrics exhibit a substantial performance drop in the unseen domain scenario relative to metrics that rely on the surface form, as well as pre-trained metrics which are not fine-tuned on MT quality judgments.
Read more6/5/2024

0
Evaluating Automatic Metrics with Incremental Machine Translation Systems
Guojun Wu, Shay B. Cohen, Rico Sennrich
We introduce a dataset comprising commercial machine translations, gathered weekly over six years across 12 translation directions. Since human A/B testing is commonly used, we assume commercial systems improve over time, which enables us to evaluate machine translation (MT) metrics based on their preference for more recent translations. Our study confirms several previous findings in MT metrics research and demonstrates the dataset's value as a testbed for metric evaluation. We release our code at https://github.com/gjwubyron/Evo
Read more7/4/2024

0
Guardians of the Machine Translation Meta-Evaluation: Sentinel Metrics Fall In!
Stefano Perrella, Lorenzo Proietti, Alessandro Scir`e, Edoardo Barba, Roberto Navigli
Annually, at the Conference of Machine Translation (WMT), the Metrics Shared Task organizers conduct the meta-evaluation of Machine Translation (MT) metrics, ranking them according to their correlation with human judgments. Their results guide researchers toward enhancing the next generation of metrics and MT systems. With the recent introduction of neural metrics, the field has witnessed notable advancements. Nevertheless, the inherent opacity of these metrics has posed substantial challenges to the meta-evaluation process. This work highlights two issues with the meta-evaluation framework currently employed in WMT, and assesses their impact on the metrics rankings. To do this, we introduce the concept of sentinel metrics, which are designed explicitly to scrutinize the meta-evaluation process's accuracy, robustness, and fairness. By employing sentinel metrics, we aim to validate our findings, and shed light on and monitor the potential biases or inconsistencies in the rankings. We discover that the present meta-evaluation framework favors two categories of metrics: i) those explicitly trained to mimic human quality assessments, and ii) continuous metrics. Finally, we raise concerns regarding the evaluation capabilities of state-of-the-art metrics, emphasizing that they might be basing their assessments on spurious correlations found in their training data.
Read more8/27/2024
0
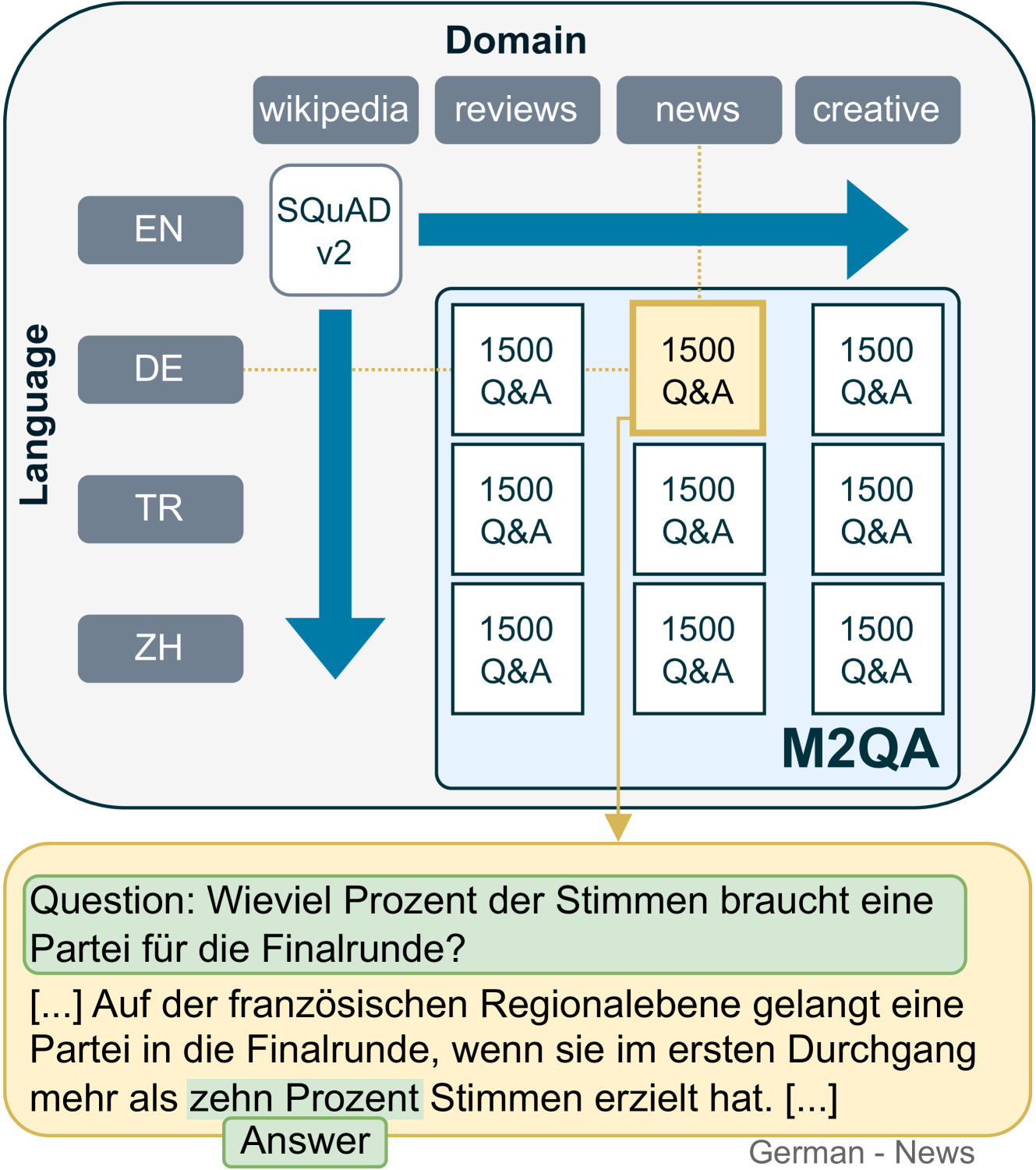
M2QA: Multi-domain Multilingual Question Answering
Leon Englander, Hannah Sterz, Clifton Poth, Jonas Pfeiffer, Ilia Kuznetsov, Iryna Gurevych
Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
Read more7/2/2024