Is Aggregation the Only Choice? Federated Learning via Layer-wise Model Recombination

0
📈
Sign in to get full access
Overview
- Federated Learning (FL) enables global model training across clients without compromising their raw data
- However, due to uneven data distribution among clients, existing Federated Averaging (FedAvg)-based methods suffer from low inference performance
- Different data distributions lead to various optimization directions of local models, resulting in a low-generalized global model
- To address this, the paper proposes a novel FL paradigm called FedMR (Federated Model Recombination)
Plain English Explanation
The paper discusses a problem with a popular Federated Learning approach called FedAvg. In Federated Learning, machine learning models are trained across multiple devices or clients without the raw data ever leaving those devices. This is useful for protecting user privacy.
However, the data on these devices is often unevenly distributed, meaning some devices have very different data than others. This causes the local models trained on each device to point in different directions during the optimization process. When these local models are averaged together to create a global model, the result is a model that doesn't perform well on most of the devices.
To address this, the researchers propose a new approach called FedMR (Federated Model Recombination). Instead of averaging the local models, FedMR shuffles the layers of the local models to create new "recombined" models. These recombined models are then sent back to the devices for further training.
The key insight is that a well-performing model is often located in a "flat" area of the optimization landscape, rather than a "sharp" area. By recombining the local models, there is a higher chance that the recombined models will end up in these flat, generalized areas. This leads to better overall performance on the devices, without compromising privacy.
Technical Explanation
The paper proposes a novel Federated Learning paradigm called FedMR (Federated Model Recombination) to address the issue of low inference performance in existing FedAvg-based methods due to uneven data distribution among clients.
Unlike conventional FedAvg, in FedMR, the cloud server recombines the collected local models by shuffling each layer to generate multiple recombined models, rather than aggregating them into a single global model. These recombined models are then sent back to the clients for further training.
The key insight is that a well-generalized solution is located in a "flat" area of the optimization landscape, rather than a "sharp" area. Since the flat area is larger than the sharp area, when local models are located in different areas, the recombined models have a higher probability of landing in a flat area. When all recombined models are located in the same flat area, they are optimized towards the same direction, leading to better overall performance.
The paper provides a theoretical analysis of the convergence of the model recombination process. Experimental results show that FedMR can significantly improve inference accuracy compared to state-of-the-art FL methods, without compromising client privacy.
Critical Analysis
The paper presents a novel and interesting approach to address the performance issues of existing Federated Learning methods due to data heterogeneity. The idea of recombining local models rather than averaging them is a creative solution that leverages insights from the geometry of the optimization landscape.
However, the paper does not discuss some potential limitations or areas for further research:
-
Computational Overhead: The process of recombining local models and generating multiple recombined models for each client may introduce additional computational overhead, which could offset the performance gains in certain scenarios.
-
Convergence Guarantees: While the paper provides a theoretical analysis of the convergence of the model recombination process, the practical convergence behavior may be more complex, especially in real-world scenarios with highly heterogeneous data.
-
Generalization to Different Architectures: The paper focuses on the FedMR approach for a specific model architecture. It would be valuable to understand how well the method can generalize to other model architectures and tasks.
-
Practical Deployment Challenges: The paper does not address potential challenges in the practical deployment of FedMR, such as communication overhead, client availability, or the impact of client-level model update strategies.
Addressing these aspects in future research could further strengthen the FedMR approach and provide a more comprehensive understanding of its capabilities and limitations.
Conclusion
The paper proposes a novel Federated Learning paradigm called FedMR (Federated Model Recombination) to address the problem of low inference performance in existing FedAvg-based methods due to uneven data distribution among clients.
FedMR takes a different approach from conventional FedAvg by recombining the collected local models, rather than averaging them. This approach aims to guide the recombined models towards a "flat" area of the optimization landscape, where the well-generalized solution is more likely to be located.
The paper provides a theoretical analysis of the convergence of the model recombination process and shows that FedMR can significantly improve inference accuracy compared to state-of-the-art Federated Learning methods, without compromising client privacy.
While the paper presents a promising approach, further research is needed to address potential limitations, such as computational overhead, convergence guarantees, and the generalization to different model architectures and real-world deployment scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Is Aggregation the Only Choice? Federated Learning via Layer-wise Model Recombination
Ming Hu, Zhihao Yue, Xiaofei Xie, Cheng Chen, Yihao Huang, Xian Wei, Xiang Lian, Yang Liu, Mingsong Chen
Although Federated Learning (FL) enables global model training across clients without compromising their raw data, due to the unevenly distributed data among clients, existing Federated Averaging (FedAvg)-based methods suffer from the problem of low inference performance. Specifically, different data distributions among clients lead to various optimization directions of local models. Aggregating local models usually results in a low-generalized global model, which performs worse on most of the clients. To address the above issue, inspired by the observation from a geometric perspective that a well-generalized solution is located in a flat area rather than a sharp area, we propose a novel and heuristic FL paradigm named FedMR (Federated Model Recombination). The goal of FedMR is to guide the recombined models to be trained towards a flat area. Unlike conventional FedAvg-based methods, in FedMR, the cloud server recombines collected local models by shuffling each layer of them to generate multiple recombined models for local training on clients rather than an aggregated global model. Since the area of the flat area is larger than the sharp area, when local models are located in different areas, recombined models have a higher probability of locating in a flat area. When all recombined models are located in the same flat area, they are optimized towards the same direction. We theoretically analyze the convergence of model recombination. Experimental results show that, compared with state-of-the-art FL methods, FedMR can significantly improve the inference accuracy without exposing the privacy of each client.
Read more7/8/2024
🛠️
0
FedCross: Towards Accurate Federated Learning via Multi-Model Cross-Aggregation
Ming Hu, Peiheng Zhou, Zhihao Yue, Zhiwei Ling, Yihao Huang, Anran Li, Yang Liu, Xiang Lian, Mingsong Chen
As a promising distributed machine learning paradigm, Federated Learning (FL) has attracted increasing attention to deal with data silo problems without compromising user privacy. By adopting the classic one-to-multi training scheme (i.e., FedAvg), where the cloud server dispatches one single global model to multiple involved clients, conventional FL methods can achieve collaborative model training without data sharing. However, since only one global model cannot always accommodate all the incompatible convergence directions of local models, existing FL approaches greatly suffer from inferior classification accuracy. To address this issue, we present an efficient FL framework named FedCross, which uses a novel multi-to-multi FL training scheme based on our proposed multi-model cross-aggregation approach. Unlike traditional FL methods, in each round of FL training, FedCross uses multiple middleware models to conduct weighted fusion individually. Since the middleware models used by FedCross can quickly converge into the same flat valley in terms of loss landscapes, the generated global model can achieve a well-generalization. Experimental results on various well-known datasets show that, compared with state-of-the-art FL methods, FedCross can significantly improve FL accuracy within both IID and non-IID scenarios without causing additional communication overhead.
Read more7/8/2024
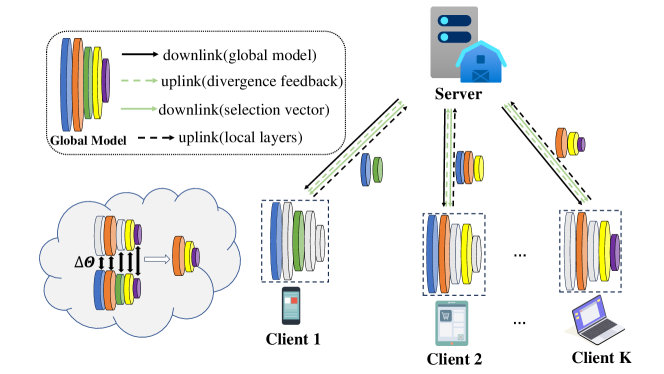
0
Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
Liwei Wang, Jun Li, Wen Chen, Qingqing Wu, Ming Ding
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
Read more4/15/2024
🔮
0
Locally Adaptive Federated Learning
Sohom Mukherjee, Nicolas Loizou, Sebastian U. Stich
Federated learning is a paradigm of distributed machine learning in which multiple clients coordinate with a central server to learn a model, without sharing their own training data. Standard federated optimization methods such as Federated Averaging (FedAvg) ensure balance among the clients by using the same stepsize for local updates on all clients. However, this means that all clients need to respect the global geometry of the function which could yield slow convergence. In this work, we propose locally adaptive federated learning algorithms, that leverage the local geometric information for each client function. We show that such locally adaptive methods with uncoordinated stepsizes across all clients can be particularly efficient in interpolated (overparameterized) settings, and analyze their convergence in the presence of heterogeneous data for convex and strongly convex settings. We validate our theoretical claims by performing illustrative experiments for both i.i.d. non-i.i.d. cases. Our proposed algorithms match the optimization performance of tuned FedAvg in the convex setting, outperform FedAvg as well as state-of-the-art adaptive federated algorithms like FedAMS for non-convex experiments, and come with superior generalization performance.
Read more5/15/2024