Is attention required for ICL? Exploring the Relationship Between Model Architecture and In-Context Learning Ability
2310.08049
0
0
📈
Abstract
What is the relationship between model architecture and the ability to perform in-context learning? In this empirical study, we take the first steps toward answering this question. We evaluate thirteen model architectures capable of causal language modeling across a suite of synthetic in-context learning tasks. These selected architectures represent a broad range of paradigms, including recurrent and convolution-based neural networks, transformers, state space model inspired, and other emerging attention alternatives. We discover that all the considered architectures can perform in-context learning under a wider range of conditions than previously documented. Additionally, we observe stark differences in statistical efficiency and consistency by varying the number of in-context examples and task difficulty. We also measure each architecture's predisposition towards in-context learning when presented with the option to memorize rather than leverage in-context examples. Finally, and somewhat surprisingly, we find that several attention alternatives are sometimes competitive with or better in-context learners than transformers. However, no single architecture demonstrates consistency across all tasks, with performance either plateauing or declining when confronted with a significantly larger number of in-context examples than those encountered during gradient-based training.
Create account to get full access
Overview
• This paper investigates the relationship between model architecture and the ability to perform in-context learning.
• The researchers evaluated 13 different model architectures capable of causal language modeling across a range of synthetic in-context learning tasks.
• The architectures tested include recurrent and convolutional neural networks, transformers, state space model inspired models, and other attention-based alternatives.
• The study found that all the considered architectures can perform in-context learning under a wider range of conditions than previously documented.
• The architectures exhibited stark differences in statistical efficiency and consistency when varying the number of in-context examples and task difficulty.
• The researchers also measured each architecture's predisposition towards in-context learning when presented with the option to memorize rather than leverage in-context examples.
• Surprisingly, several attention-based alternatives were sometimes competitive with or better in-context learners than transformers.
• However, no single architecture demonstrated consistency across all tasks, with performance either plateauing or declining when confronted with significantly more in-context examples than encountered during training.
Plain English Explanation
The paper explores how the design of AI language models affects their ability to learn new information on the fly. Imagine you're teaching a language model about a new topic by showing it a few example sentences. Can the model then use that information to understand and generate relevant text, or does it struggle to apply what it has just learned?
The researchers tested 13 different model architectures, representing a wide range of approaches, to see how well they could adapt to new information in this way. Interestingly, they found that all the models were able to learn from just a few examples, even in more challenging scenarios than previously thought possible.
However, the models varied greatly in how efficiently and consistently they could leverage the new information. Some architectures were much better than others at quickly understanding and applying the contextual clues provided. Surprisingly, some newer attention-based models even outperformed the popular transformer architecture in certain tasks.
The results suggest that the choice of model architecture can have a big impact on a language model's ability to learn and adapt on the fly. But no single architecture was the clear winner across all the tests - each had its own strengths and weaknesses when confronted with different amounts of new information to learn.
Technical Explanation
The paper evaluates 13 different model architectures for their in-context learning capabilities. The architectures tested include recurrent neural networks (RNNs), convolutional neural networks (CNNs), transformers, state space model inspired designs, and several attention-based alternatives.
The authors designed a suite of synthetic in-context learning tasks to assess each model's performance. These tasks involved providing the models with a small number of example sentences related to a particular topic or concept, then evaluating how well the models could understand and generate relevant text based on that contextual information.
A key finding was that all the considered architectures were able to perform in-context learning over a wider range of conditions than previously documented. This suggests that the ability to quickly adapt to new information is more widespread among language models than previously thought.
However, the researchers observed stark differences in the statistical efficiency and consistency of the different architectures. Some models were much better than others at leveraging just a few in-context examples, while others required many more examples to achieve similar performance. Task difficulty was also a factor, with some architectures handling more challenging scenarios better than others.
The paper also analyzed each model's "predisposition" towards in-context learning. When given the option to either memorize new information or leverage it contextually, certain architectures exhibited a stronger tendency towards the latter approach.
Notably, the researchers found that several attention-based alternatives to the transformer architecture were sometimes competitive or even superior in-context learners. This was somewhat surprising, as transformers have become the dominant architecture for many language modeling tasks.
Despite these insights, the researchers did not find a single architecture that demonstrated consistent superiority across all the in-context learning tasks. Performance often plateaued or declined when the models were presented with significantly more in-context examples than they had encountered during training.
Critical Analysis
The paper provides valuable empirical insights into how model architecture affects in-context learning capabilities. By evaluating a diverse range of architectures, the researchers were able to identify key differences in how efficiently and consistently different models can leverage new information.
One notable strength of the study is the use of synthetic tasks, which allowed the researchers to carefully control the experimental conditions and isolate the effects of factors like task difficulty and number of in-context examples. This rigorous approach helps strengthen the validity of the findings.
However, it's important to note that the synthetic nature of the tasks may limit the direct applicability of the results to real-world language modeling scenarios. The researchers acknowledge this as a potential limitation and suggest that further investigation is needed to understand how the architectures would perform on more natural, open-ended tasks.
Another area for potential further research is the exploration of model hyperparameters and training regimes. The paper focuses on the architectural differences, but it's possible that certain hyperparameter settings or training approaches could help mitigate the observed performance disparities between the models.
Additionally, while the paper provides intriguing findings about the potential of attention-based alternatives to transformers, more work is needed to fully understand the strengths and weaknesses of these emerging architectures. Deeper analysis of the attention mechanisms and their role in in-context learning could yield valuable insights.
Overall, this study represents an important step in understanding the relationship between model architecture and in-context learning abilities. The researchers have laid the groundwork for further exploration and refinement of language modeling approaches to enhance their adaptability and real-world performance.
Conclusion
This paper takes a crucial step towards understanding how the design of language models can impact their ability to quickly learn and adapt to new information. By evaluating a diverse range of architectures on synthetic in-context learning tasks, the researchers have uncovered significant differences in the statistical efficiency and consistency of various modeling approaches.
The finding that all the considered architectures can perform in-context learning under a wider range of conditions than previously documented is particularly notable, as it suggests that the capacity for rapid adaptation may be more widespread among language models than previously thought.
Furthermore, the discovery that attention-based alternatives can sometimes outperform transformers, the current dominant architecture, opens up exciting possibilities for the future of language modeling. Continued research in this direction could lead to the development of even more flexible and adaptable models, better equipped to handle the complexities of real-world language use.
While the synthetic nature of the tasks limits the direct applicability of the findings, this study lays a solid foundation for further exploration. By delving deeper into the relationship between architecture and in-context learning, and considering the role of hyperparameters and training regimes, researchers can work towards language models that can more seamlessly integrate new information and knowledge on the fly.
Ultimately, this research represents an important step forward in our understanding of how the design choices we make in language modeling can profoundly impact a model's ability to learn and adapt. As we continue to push the boundaries of what these systems can achieve, studies like this will be crucial in guiding us towards more flexible, capable, and adaptable language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Why Larger Language Models Do In-context Learning Differently?
Zhenmei Shi, Junyi Wei, Zhuoyan Xu, Yingyu Liang
0
0
Large language models (LLM) have emerged as a powerful tool for AI, with the key ability of in-context learning (ICL), where they can perform well on unseen tasks based on a brief series of task examples without necessitating any adjustments to the model parameters. One recent interesting mysterious observation is that models of different scales may have different ICL behaviors: larger models tend to be more sensitive to noise in the test context. This work studies this observation theoretically aiming to improve the understanding of LLM and ICL. We analyze two stylized settings: (1) linear regression with one-layer single-head linear transformers and (2) parity classification with two-layer multiple attention heads transformers (non-linear data and non-linear model). In both settings, we give closed-form optimal solutions and find that smaller models emphasize important hidden features while larger ones cover more hidden features; thus, smaller models are more robust to noise while larger ones are more easily distracted, leading to different ICL behaviors. This sheds light on where transformers pay attention to and how that affects ICL. Preliminary experimental results on large base and chat models provide positive support for our analysis.
5/31/2024
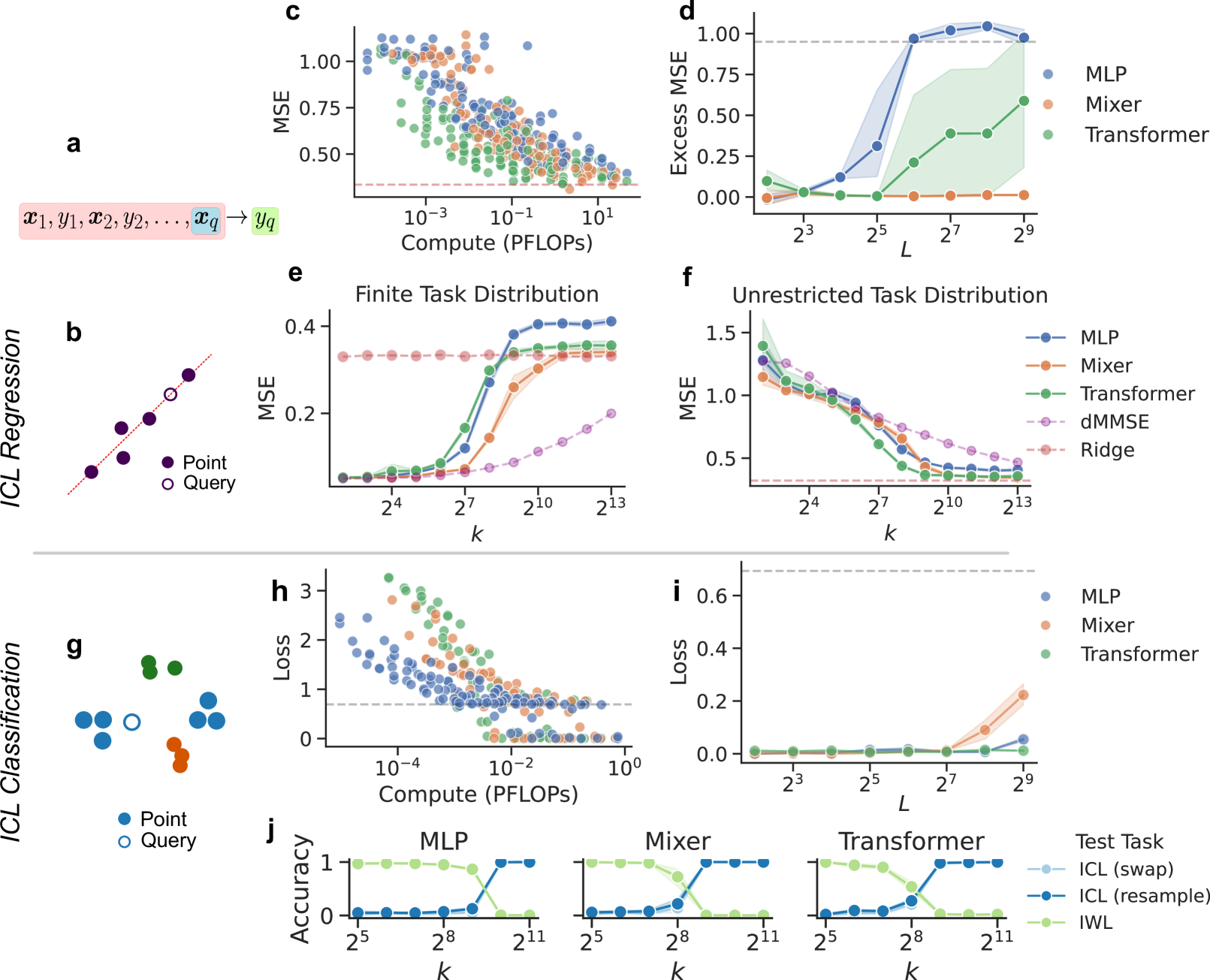
MLPs Learn In-Context
William L. Tong, Cengiz Pehlevan
0
0
In-context learning (ICL), the remarkable ability to solve a task from only input exemplars, has commonly been assumed to be a unique hallmark of Transformer models. In this study, we demonstrate that multi-layer perceptrons (MLPs) can also learn in-context. Moreover, we find that MLPs, and the closely related MLP-Mixer models, learn in-context competitively with Transformers given the same compute budget. We further show that MLPs outperform Transformers on a subset of ICL tasks designed to test relational reasoning. These results suggest that in-context learning is not exclusive to Transformers and highlight the potential of exploring this phenomenon beyond attention-based architectures. In addition, MLPs' surprising success on relational tasks challenges prior assumptions about simple connectionist models. Altogether, our results endorse the broad trend that ``less inductive bias is better and contribute to the growing interest in all-MLP alternatives to task-specific architectures.
5/27/2024
How Far Can In-Context Alignment Go? Exploring the State of In-Context Alignment
Heyan Huang, Yinghao Li, Huashan Sun, Yu Bai, Yang Gao
0
0
Recent studies have demonstrated that In-Context Learning (ICL), through the use of specific demonstrations, can align Large Language Models (LLMs) with human preferences known as In-Context Alignment (ICA), indicating that models can comprehend human instructions without requiring parameter adjustments. However, the exploration of the mechanism and applicability of ICA remains limited. In this paper, we begin by dividing the context text used in ICA into three categories: format, system prompt, and example. Through ablation experiments, we investigate the effectiveness of each part in enabling ICA to function effectively. We then examine how variants in these parts impact the model's alignment performance. Our findings indicate that the example part is crucial for enhancing the model's alignment capabilities, with changes in examples significantly affecting alignment performance. We also conduct a comprehensive evaluation of ICA's zero-shot capabilities in various alignment tasks. The results indicate that compared to parameter fine-tuning methods, ICA demonstrates superior performance in knowledge-based tasks and tool-use tasks. However, it still exhibits certain limitations in areas such as multi-turn dialogues and instruction following.
6/18/2024

Asymptotic theory of in-context learning by linear attention
Yue M. Lu, Mary I. Letey, Jacob A. Zavatone-Veth, Anindita Maiti, Cengiz Pehlevan
0
0
Transformers have a remarkable ability to learn and execute tasks based on examples provided within the input itself, without explicit prior training. It has been argued that this capability, known as in-context learning (ICL), is a cornerstone of Transformers' success, yet questions about the necessary sample complexity, pretraining task diversity, and context length for successful ICL remain unresolved. Here, we provide a precise answer to these questions in an exactly solvable model of ICL of a linear regression task by linear attention. We derive sharp asymptotics for the learning curve in a phenomenologically-rich scaling regime where the token dimension is taken to infinity; the context length and pretraining task diversity scale proportionally with the token dimension; and the number of pretraining examples scales quadratically. We demonstrate a double-descent learning curve with increasing pretraining examples, and uncover a phase transition in the model's behavior between low and high task diversity regimes: In the low diversity regime, the model tends toward memorization of training tasks, whereas in the high diversity regime, it achieves genuine in-context learning and generalization beyond the scope of pretrained tasks. These theoretical insights are empirically validated through experiments with both linear attention and full nonlinear Transformer architectures.
5/21/2024