Is larger always better? Evaluating and prompting large language models for non-generative medical tasks

0
💬
Sign in to get full access
Overview
- The use of Large Language Models (LLMs) in medicine is growing, but their ability to handle both structured Electronic Health Record (EHR) data and unstructured clinical notes is not well-studied.
- This study benchmarks various models, including GPT-based LLMs, BERT-based models, and traditional clinical predictive models, for non-generative medical tasks using renowned datasets.
- The researchers assessed 14 language models (9 GPT-based and 5 BERT-based) and 7 traditional predictive models using the MIMIC dataset (ICU patient records) and the TJH dataset (early COVID-19 EHR data).
- They focused on tasks such as mortality and readmission prediction, disease hierarchy reconstruction, and biomedical sentence matching, comparing both zero-shot and finetuned performance.
Plain English Explanation
Large Language Models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. These models are increasingly being used in the field of medicine, but their ability to work with both structured electronic health record (EHR) data and unstructured clinical notes is not well understood.
This study aimed to compare the performance of various LLMs, including those based on GPT and BERT architectures, as well as traditional clinical predictive models, on a range of medical tasks. The researchers used well-known healthcare datasets, the MIMIC dataset (which contains records of ICU patients) and the TJH dataset (which has early COVID-19 EHR data), to evaluate the models.
The tasks included predicting patient mortality and readmission, reconstructing disease hierarchies, and matching biomedical sentences. The researchers looked at how the models performed both when used "out of the box" (zero-shot) and when fine-tuned on the specific medical tasks.
Technical Explanation
The study found that LLMs exhibited robust zero-shot predictive capabilities on structured EHR data when using well-designed prompting strategies, frequently outperforming traditional models. However, for unstructured medical texts, the LLMs did not outperform fine-tuned BERT models, which excelled in both supervised and unsupervised tasks.
This suggests that while LLMs can be effective for zero-shot learning on structured data, fine-tuned BERT models are more suitable for working with unstructured clinical notes. The researchers emphasize the importance of selecting models based on the specific task requirements and data characteristics to optimize the application of natural language processing (NLP) technology in healthcare.
Critical Analysis
The study provides valuable insights into the strengths and limitations of different language models for medical tasks. However, it is important to note that the research was conducted using specific datasets and may not fully capture the diversity of clinical data and use cases in real-world healthcare settings.
Additionally, the paper does not delve deeply into the potential biases or ethical considerations that may arise from the use of these powerful language models in sensitive medical domains. Further research is needed to address these important issues.
Conclusion
This study suggests that while LLMs can be effective for certain medical tasks, particularly when working with structured EHR data, fine-tuned BERT models may be more suitable for handling unstructured clinical notes. The findings highlight the importance of carefully selecting the appropriate model based on the specific requirements of the healthcare application to maximize the benefits of NLP technology in the medical field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Is larger always better? Evaluating and prompting large language models for non-generative medical tasks
Yinghao Zhu, Junyi Gao, Zixiang Wang, Weibin Liao, Xiaochen Zheng, Lifang Liang, Yasha Wang, Chengwei Pan, Ewen M. Harrison, Liantao Ma
The use of Large Language Models (LLMs) in medicine is growing, but their ability to handle both structured Electronic Health Record (EHR) data and unstructured clinical notes is not well-studied. This study benchmarks various models, including GPT-based LLMs, BERT-based models, and traditional clinical predictive models, for non-generative medical tasks utilizing renowned datasets. We assessed 14 language models (9 GPT-based and 5 BERT-based) and 7 traditional predictive models using the MIMIC dataset (ICU patient records) and the TJH dataset (early COVID-19 EHR data), focusing on tasks such as mortality and readmission prediction, disease hierarchy reconstruction, and biomedical sentence matching, comparing both zero-shot and finetuned performance. Results indicated that LLMs exhibited robust zero-shot predictive capabilities on structured EHR data when using well-designed prompting strategies, frequently surpassing traditional models. However, for unstructured medical texts, LLMs did not outperform finetuned BERT models, which excelled in both supervised and unsupervised tasks. Consequently, while LLMs are effective for zero-shot learning on structured data, finetuned BERT models are more suitable for unstructured texts, underscoring the importance of selecting models based on specific task requirements and data characteristics to optimize the application of NLP technology in healthcare.
Read more7/29/2024
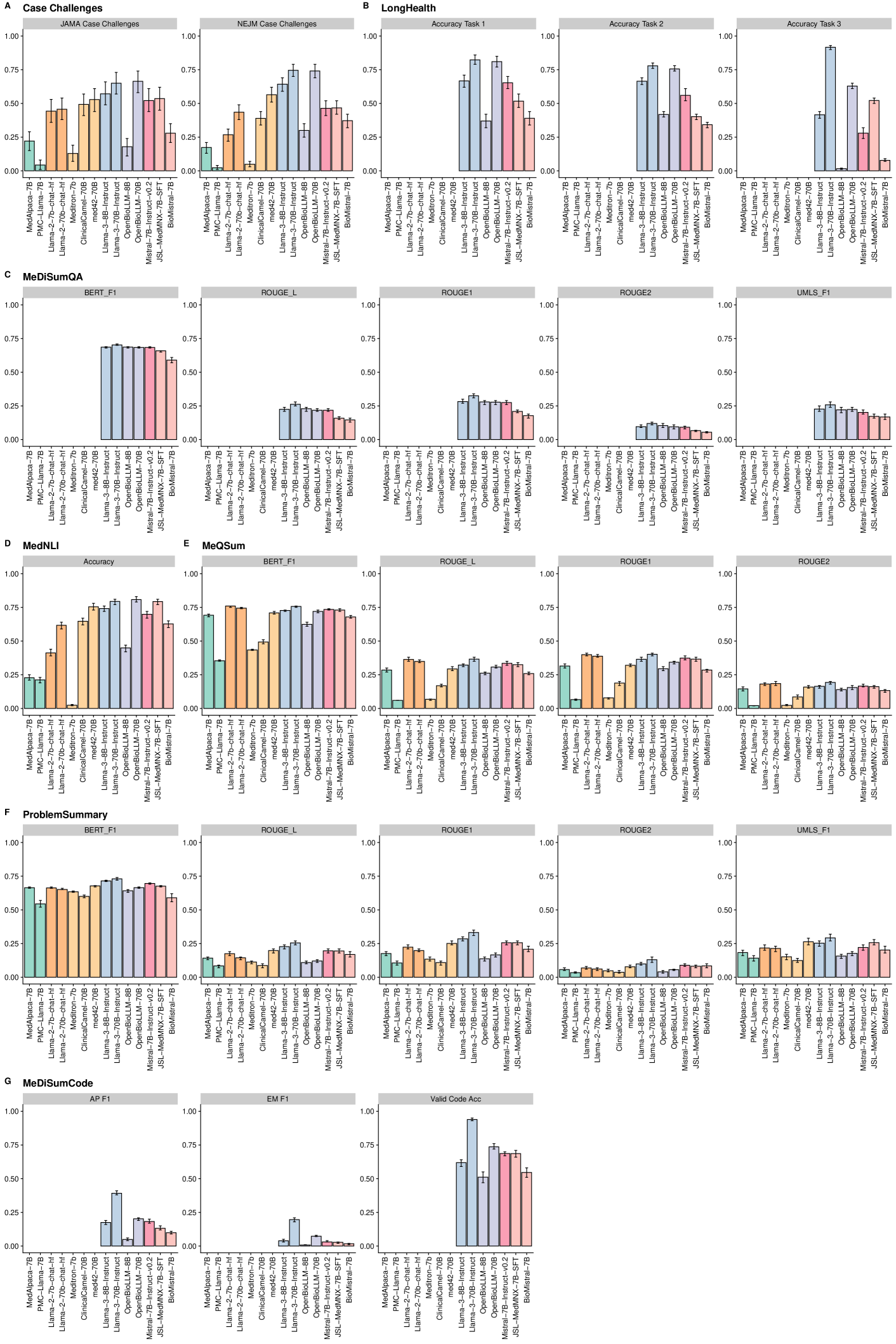
0
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, Keno K. Bressem
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
Read more8/27/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
Read more6/18/2024

0
A Survey on Medical Large Language Models: Technology, Application, Trustworthiness, and Future Directions
Lei Liu, Xiaoyan Yang, Junchi Lei, Xiaoyang Liu, Yue Shen, Zhiqiang Zhang, Peng Wei, Jinjie Gu, Zhixuan Chu, Zhan Qin, Kui Ren
Large language models (LLMs), such as GPT series models, have received substantial attention due to their impressive capabilities for generating and understanding human-level language. More recently, LLMs have emerged as an innovative and powerful adjunct in the medical field, transforming traditional practices and heralding a new era of enhanced healthcare services. This survey provides a comprehensive overview of Medical Large Language Models (Med-LLMs), outlining their evolution from general to the medical-specific domain (i.e, Technology and Application), as well as their transformative impact on healthcare (e.g., Trustworthiness and Safety). Concretely, starting from the fundamental history and technology of LLMs, we first delve into the progressive adaptation and refinements of general LLM models in the medical domain, especially emphasizing the advanced algorithms that boost the LLMs' performance in handling complicated medical environments, including clinical reasoning, knowledge graph, retrieval-augmented generation, human alignment, and multi-modal learning. Secondly, we explore the extensive applications of Med-LLMs across domains such as clinical decision support, report generation, and medical education, illustrating their potential to streamline healthcare services and augment patient outcomes. Finally, recognizing the imperative and responsible innovation, we discuss the challenges of ensuring fairness, accountability, privacy, and robustness in Med-LLMs applications. Finally, we conduct a concise discussion for anticipating possible future trajectories of Med-LLMs, identifying avenues for the prudent expansion of Med-LLMs. By consolidating above-mentioned insights, this review seeks to provide a comprehensive investigation of the potential strengths and limitations of Med-LLMs for professionals and researchers, ensuring a responsible landscape in the healthcare setting.
Read more6/7/2024