Is Temperature Sample Efficient for Softmax Gaussian Mixture of Experts?

0
🏋️
Sign in to get full access
Overview
- This paper explores the impacts of the dense-to-sparse gate on the maximum likelihood estimation under the Gaussian Mixture of Experts (MoE) model.
- The dense-to-sparse gating MoE is an alternative to the well-known sparse MoE, which fixes the number of activated experts.
- The dense-to-sparse gating MoE uses temperature to control the softmax weight distribution and the sparsity of the MoE during training, stabilizing expert specialization.
- Previous attempts have focused on understanding the sparse MoE, but a comprehensive analysis of the dense-to-sparse gating MoE has been lacking.
Plain English Explanation
The paper looks at a type of machine learning model called a Mixture of Experts (MoE). In a MoE, there are multiple "expert" models that specialize in different parts of the problem, and a "gating" mechanism that decides which expert to use for each input.
The authors are studying a specific version of the MoE called the "dense-to-sparse gating" MoE. This model starts with all the experts being used (a "dense" configuration), and then gradually reduces the number of active experts during training (becoming "sparse"). This is different from the traditional "sparse" MoE, where the number of active experts is fixed.
The key idea behind the dense-to-sparse gating MoE is to use a temperature parameter to control how the gating mechanism decides which experts to use. By adjusting this temperature, the model can find the right balance between using many experts (dense) and only a few (sparse), which can help the experts become more specialized.
The authors show that this temperature-based gating mechanism can lead to slower convergence of the model parameters during training, compared to simpler MoE models. To address this, they propose a new "activation dense-to-sparse gate" that uses an activation function to improve the parameter estimation rates.
Technical Explanation
The paper analyzes the dense-to-sparse gating Mixture of Experts (MoE) model, which is an alternative to the well-known sparse MoE. Unlike the sparse MoE, which fixes the number of activated experts, the dense-to-sparse gating MoE uses temperature to control the softmax weight distribution and the sparsity of the MoE during training, stabilizing expert specialization.
The authors demonstrate that due to interactions between the temperature and other model parameters via partial differential equations, the convergence rates of parameter estimations in the dense-to-sparse gating MoE are slower than any polynomial rates, and could be as slow as O(1/log(n)), where n denotes the sample size. This is in contrast to the polynomial convergence rates of the sparse MoE.
To address this issue, the authors propose using a novel "activation dense-to-sparse gate", which routes the output of a linear layer to an activation function before delivering them to the softmax function. By imposing linearly independence conditions on the activation function and its derivatives, they show that the parameter estimation rates are significantly improved to polynomial rates.
The paper concludes with a simulation study that empirically validates the theoretical results.
Critical Analysis
The paper provides a comprehensive analysis of the dense-to-sparse gating Mixture of Experts (MoE) model, which is an important contribution to the understanding of this class of models. The authors highlight a key limitation of the dense-to-sparse gating MoE, namely the slower convergence rates of parameter estimations compared to the sparse MoE.
One potential area for further research could be investigating the practical implications of these slower convergence rates. In real-world applications, where sample sizes may be limited, the differences in convergence rates may have a significant impact on model performance and training efficiency.
Additionally, the proposed "activation dense-to-sparse gate" seems promising, but the authors could have explored the design space of activation functions and their properties more extensively. This could lead to further improvements in the parameter estimation rates or other desirable properties of the model.
Overall, the paper makes a valuable contribution to the understanding of dense-to-sparse gating MoE models, and the proposed solutions offer a path forward for addressing the identified limitations.
Conclusion
This paper presents a comprehensive analysis of the dense-to-sparse gating Mixture of Experts (MoE) model, which is an alternative to the well-known sparse MoE. The authors demonstrate that the dense-to-sparse gating mechanism can lead to slower convergence rates of parameter estimations, and they propose a novel "activation dense-to-sparse gate" to address this issue.
The findings in this paper advance the understanding of MoE models and their training dynamics, which is crucial for the development of more efficient and effective machine learning systems. The proposed activation-based gating mechanism offers a promising direction for future research and practical applications of dense-to-sparse gating MoE models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Is Temperature Sample Efficient for Softmax Gaussian Mixture of Experts?
Huy Nguyen, Pedram Akbarian, Nhat Ho
Dense-to-sparse gating mixture of experts (MoE) has recently become an effective alternative to a well-known sparse MoE. Rather than fixing the number of activated experts as in the latter model, which could limit the investigation of potential experts, the former model utilizes the temperature to control the softmax weight distribution and the sparsity of the MoE during training in order to stabilize the expert specialization. Nevertheless, while there are previous attempts to theoretically comprehend the sparse MoE, a comprehensive analysis of the dense-to-sparse gating MoE has remained elusive. Therefore, we aim to explore the impacts of the dense-to-sparse gate on the maximum likelihood estimation under the Gaussian MoE in this paper. We demonstrate that due to interactions between the temperature and other model parameters via some partial differential equations, the convergence rates of parameter estimations are slower than any polynomial rates, and could be as slow as $mathcal{O}(1/log(n))$, where $n$ denotes the sample size. To address this issue, we propose using a novel activation dense-to-sparse gate, which routes the output of a linear layer to an activation function before delivering them to the softmax function. By imposing linearly independence conditions on the activation function and its derivatives, we show that the parameter estimation rates are significantly improved to polynomial rates. Finally, we conduct a simulation study to empirically validate our theoretical results.
Read more6/26/2024
🔎
0
A General Theory for Softmax Gating Multinomial Logistic Mixture of Experts
Huy Nguyen, Pedram Akbarian, TrungTin Nguyen, Nhat Ho
Mixture-of-experts (MoE) model incorporates the power of multiple submodels via gating functions to achieve greater performance in numerous regression and classification applications. From a theoretical perspective, while there have been previous attempts to comprehend the behavior of that model under the regression settings through the convergence analysis of maximum likelihood estimation in the Gaussian MoE model, such analysis under the setting of a classification problem has remained missing in the literature. We close this gap by establishing the convergence rates of density estimation and parameter estimation in the softmax gating multinomial logistic MoE model. Notably, when part of the expert parameters vanish, these rates are shown to be slower than polynomial rates owing to an inherent interaction between the softmax gating and expert functions via partial differential equations. To address this issue, we propose using a novel class of modified softmax gating functions which transform the input before delivering them to the gating functions. As a result, the previous interaction disappears and the parameter estimation rates are significantly improved.
Read more6/26/2024
🧠
0
On Least Square Estimation in Softmax Gating Mixture of Experts
Huy Nguyen, Nhat Ho, Alessandro Rinaldo
Mixture of experts (MoE) model is a statistical machine learning design that aggregates multiple expert networks using a softmax gating function in order to form a more intricate and expressive model. Despite being commonly used in several applications owing to their scalability, the mathematical and statistical properties of MoE models are complex and difficult to analyze. As a result, previous theoretical works have primarily focused on probabilistic MoE models by imposing the impractical assumption that the data are generated from a Gaussian MoE model. In this work, we investigate the performance of the least squares estimators (LSE) under a deterministic MoE model where the data are sampled according to a regression model, a setting that has remained largely unexplored. We establish a condition called strong identifiability to characterize the convergence behavior of various types of expert functions. We demonstrate that the rates for estimating strongly identifiable experts, namely the widely used feed-forward networks with activation functions $mathrm{sigmoid}(cdot)$ and $tanh(cdot)$, are substantially faster than those of polynomial experts, which we show to exhibit a surprising slow estimation rate. Our findings have important practical implications for expert selection.
Read more6/26/2024
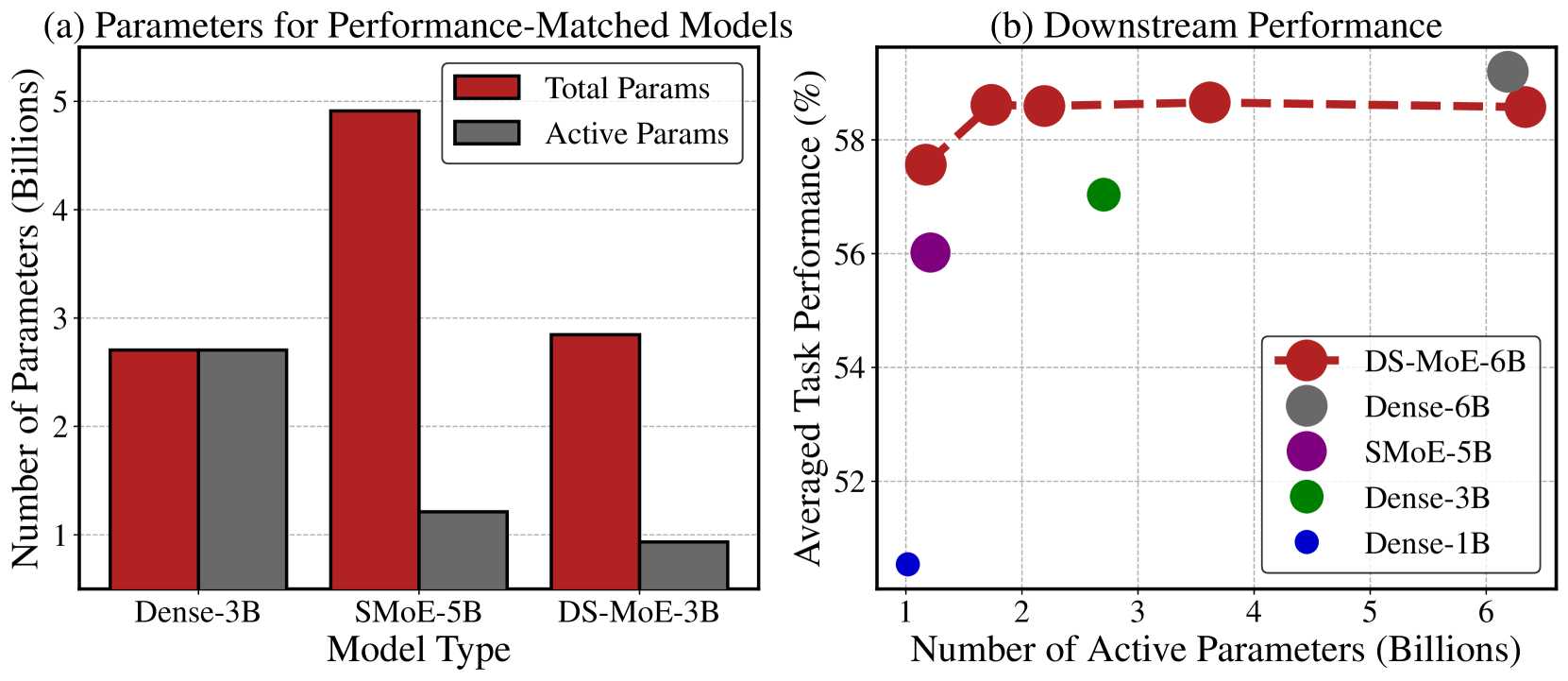
0
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Read more4/9/2024