Is this a bad table? A Closer Look at the Evaluation of Table Generation from Text

0
Sign in to get full access
Overview
- This paper examines the challenges in evaluating table generation from text, a task where models are asked to generate tables based on given text.
- The authors propose a new evaluation strategy that goes beyond traditional metric-based approaches, aiming to provide a more holistic and nuanced assessment of table generation systems.
- The paper highlights the need for more comprehensive evaluation methods that capture both the objective and subjective aspects of table quality.
Plain English Explanation
The research paper discusses the challenges in evaluating the performance of AI models that generate tables from text. Traditionally, table generation has been assessed using numerical metrics that measure how well the generated tables match the expected output. However, the authors argue that this approach is limited and may not capture the full complexity of table quality.
To address this, the researchers propose a new evaluation strategy that goes beyond just numerical scores. Their approach aims to provide a more comprehensive assessment, considering both the objective qualities of the generated tables (such as accuracy and completeness) as well as the subjective aspects (such as readability and usefulness). [This aligns with the research in <a href="https://aimodels.fyi/papers/arxiv/facts-feelings-capturing-both-objectivity-subjectivity-table">Facts and Feelings: Capturing Both Objectivity and Subjectivity in Table Evaluation</a>.]
The key idea is to evaluate table generation not just based on how well the model reproduces the expected output, but also on how well the generated tables serve the intended purpose and meet the needs of end-users. This involves considering factors like the table's layout, formatting, and overall interpretability. [Similar to the approach in <a href="https://aimodels.fyi/papers/arxiv/generating-tables-from-parametric-knowledge-language-models">Generating Tables from Parametric Knowledge Language Models</a>.]
By taking a more holistic view of table quality, the researchers hope to provide a better understanding of the strengths and limitations of different table generation systems. This could ultimately lead to the development of more effective and user-centric table generation models. [This relates to the work on <a href="https://aimodels.fyi/papers/arxiv/tabsqlify-enhancing-reasoning-capabilities-llms-through-table">TabSQLify: Enhancing Reasoning Capabilities of LLMs Through Tables</a>.]
Technical Explanation
The paper proposes a new evaluation strategy for assessing the quality of tables generated from text. The authors argue that traditional metric-based approaches, such as measuring the exact match between the generated and expected tables, have limitations in capturing the full complexity of table quality.
To address this, the researchers introduce a multifaceted evaluation framework that considers both objective and subjective aspects of table generation. The objective evaluation focuses on measuring the accuracy, completeness, and structural consistency of the generated tables. The subjective evaluation, on the other hand, assesses factors like readability, usefulness, and overall table quality as perceived by human evaluators.
The proposed evaluation pipeline involves several steps. First, the generated tables are compared to the reference tables using various numerical metrics, such as exact match, F1 score, and table structure similarity. Next, human evaluators are asked to assess the generated tables based on a set of criteria, including clarity, coherence, and the ability to convey the intended information effectively.
The authors also discuss the importance of carefully designing the evaluation tasks and instructions to ensure that the assessments capture the most relevant aspects of table quality. They emphasize the need to consider the specific use case and target audience when evaluating table generation systems.
The paper presents experiments on several table generation datasets, demonstrating the potential of the proposed evaluation strategy to provide a more nuanced and comprehensive assessment of table generation models. The results highlight the value of combining objective and subjective evaluations to gain a deeper understanding of the strengths and limitations of different table generation approaches.
Critical Analysis
The authors make a compelling case for the need to move beyond traditional metric-based evaluation of table generation systems. Their proposed evaluation strategy, which incorporates both objective and subjective assessments, represents a significant step forward in the field.
One of the key strengths of the paper is its recognition that table quality is a multifaceted concept that cannot be adequately captured by a single numerical score. By incorporating human evaluation, the authors acknowledge the importance of understanding how end-users perceive and interact with the generated tables.
However, the paper also highlights some challenges in implementing this evaluation approach. Designing appropriate tasks and instructions for human evaluators can be complex, and ensuring consistent and reliable assessments across different evaluators may require careful study design and training.
Additionally, the paper does not delve into the potential biases or limitations of the human evaluation process. It would be valuable to explore how factors such as the evaluators' backgrounds, expectations, and preconceptions might influence their assessments of table quality.
Further research could also investigate the relationship between the objective and subjective evaluation measures, and how they might be combined to provide a more comprehensive and actionable assessment of table generation systems. [This could build on the insights from <a href="https://aimodels.fyi/papers/arxiv/ct-eval-benchmarking-chinese-text-to-table">CT-Eval: Benchmarking Chinese Text-to-Table Generation</a> and <a href="https://aimodels.fyi/papers/arxiv/freb-tqa-fine-grained-robustness-evaluation-benchmark">FREB-TQA: A Fine-grained Robustness Evaluation Benchmark for Table Question Answering</a>.]
Conclusion
This paper presents a novel evaluation strategy for assessing the quality of tables generated from text, addressing the limitations of traditional metric-based approaches. By incorporating both objective and subjective evaluations, the authors aim to provide a more comprehensive and nuanced assessment of table generation systems.
The proposed framework has the potential to drive the development of more effective and user-centric table generation models, as it encourages researchers and practitioners to consider the full spectrum of table quality, from accuracy and completeness to readability and usefulness. As the field of table generation continues to evolve, this evaluation approach could become a valuable tool for advancing the state of the art and ensuring that generated tables meet the needs of end-users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Is this a bad table? A Closer Look at the Evaluation of Table Generation from Text
Pritika Ramu, Aparna Garimella, Sambaran Bandyopadhyay
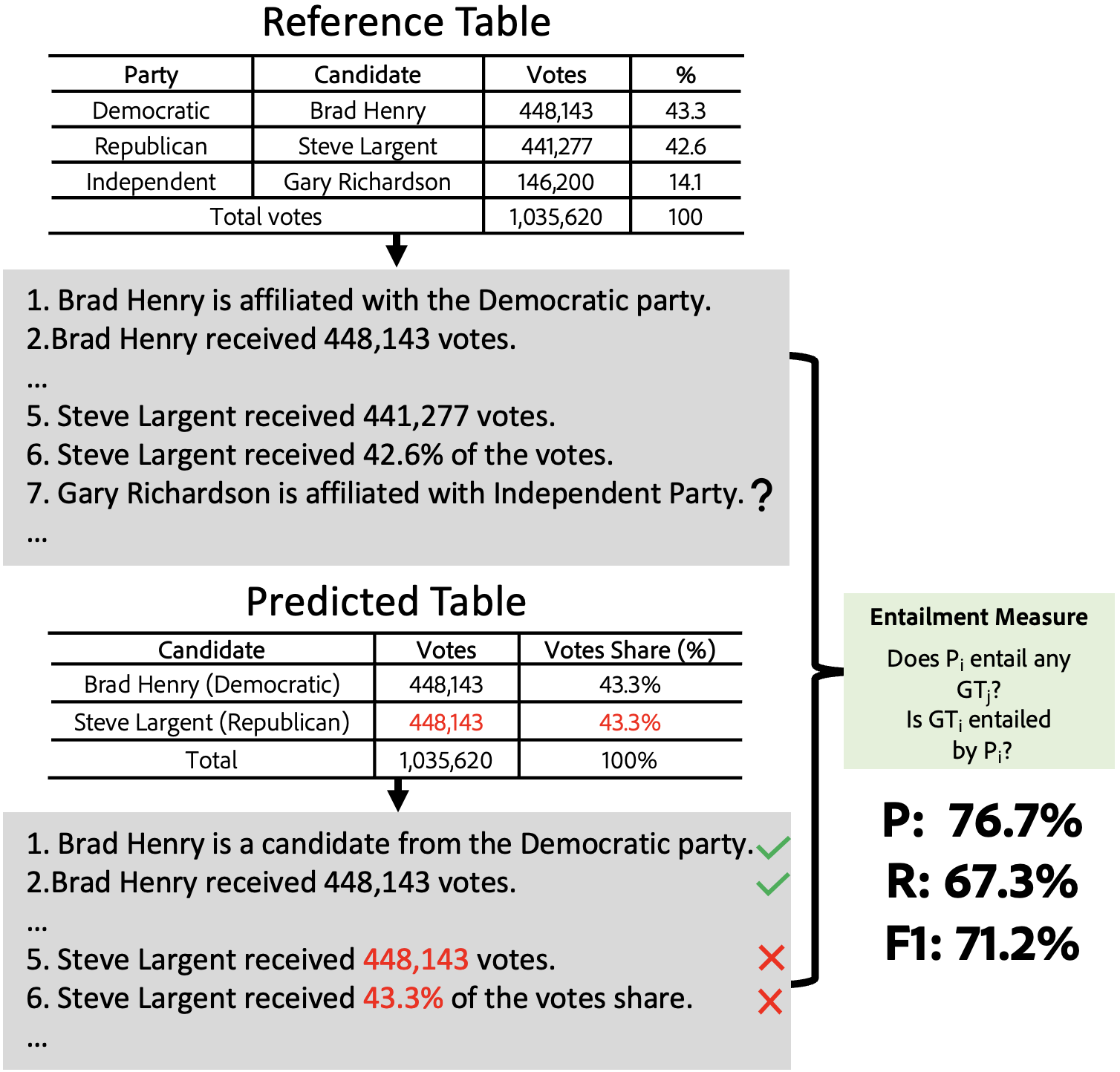
Understanding whether a generated table is of good quality is important to be able to use it in creating or editing documents using automatic methods. In this work, we underline that existing measures for table quality evaluation fail to capture the overall semantics of the tables, and sometimes unfairly penalize good tables and reward bad ones. We propose TabEval, a novel table evaluation strategy that captures table semantics by first breaking down a table into a list of natural language atomic statements and then compares them with ground truth statements using entailment-based measures. To validate our approach, we curate a dataset comprising of text descriptions for 1,250 diverse Wikipedia tables, covering a range of topics and structures, in contrast to the limited scope of existing datasets. We compare TabEval with existing metrics using unsupervised and supervised text-to-table generation methods, demonstrating its stronger correlation with human judgments of table quality across four datasets.
Read more6/24/2024

0
CT-Eval: Benchmarking Chinese Text-to-Table Performance in Large Language Models
Haoxiang Shi, Jiaan Wang, Jiarong Xu, Cen Wang, Tetsuya Sakai
Text-to-Table aims to generate structured tables to convey the key information from unstructured documents. Existing text-to-table datasets are typically oriented English, limiting the research in non-English languages. Meanwhile, the emergence of large language models (LLMs) has shown great success as general task solvers in multi-lingual settings (e.g., ChatGPT), theoretically enabling text-to-table in other languages. In this paper, we propose a Chinese text-to-table dataset, CT-Eval, to benchmark LLMs on this task. Our preliminary analysis of English text-to-table datasets highlights two key factors for dataset construction: data diversity and data hallucination. Inspired by this, the CT-Eval dataset selects a popular Chinese multidisciplinary online encyclopedia as the source and covers 28 domains to ensure data diversity. To minimize data hallucination, we first train an LLM to judge and filter out the task samples with hallucination, then employ human annotators to clean the hallucinations in the validation and testing sets. After this process, CT-Eval contains 88.6K task samples. Using CT-Eval, we evaluate the performance of open-source and closed-source LLMs. Our results reveal that zero-shot LLMs (including GPT-4) still have a significant performance gap compared with human judgment. Furthermore, after fine-tuning, open-source LLMs can significantly improve their text-to-table ability, outperforming GPT-4 by a large margin. In short, CT-Eval not only helps researchers evaluate and quickly understand the Chinese text-to-table ability of existing LLMs but also serves as a valuable resource to significantly improve the text-to-table performance of LLMs.
Read more5/21/2024
0
Generating Tables from the Parametric Knowledge of Language Models
Yevgeni Berkovitch, Oren Glickman, Amit Somech, Tomer Wolfson
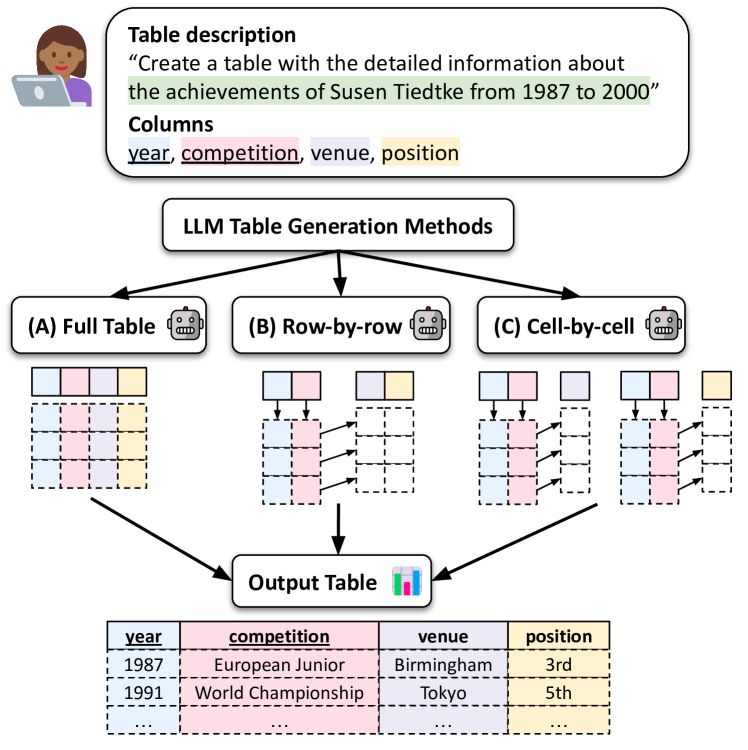
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
Read more6/18/2024

0
Facts-and-Feelings: Capturing both Objectivity and Subjectivity in Table-to-Text Generation
Tathagata Dey, Pushpak Bhattacharyya
Table-to-text generation, a long-standing challenge in natural language generation, has remained unexplored through the lens of subjectivity. Subjectivity here encompasses the comprehension of information derived from the table that cannot be described solely by objective data. Given the absence of pre-existing datasets, we introduce the Ta2TS dataset with 3849 data instances. We perform the task of fine-tuning sequence-to-sequence models on the linearized tables and prompting on popular large language models. We analyze the results from a quantitative and qualitative perspective to ensure the capture of subjectivity and factual consistency. The analysis shows the fine-tuned LMs can perform close to the prompted LLMs. Both the models can capture the tabular data, generating texts with 85.15% BERTScore and 26.28% Meteor score. To the best of our knowledge, we provide the first-of-its-kind dataset on tables with multiple genres and subjectivity included and present the first comprehensive analysis and comparison of different LLM performances on this task.
Read more6/18/2024