Facts-and-Feelings: Capturing both Objectivity and Subjectivity in Table-to-Text Generation

0

Sign in to get full access
Overview
- This research paper explores the challenge of capturing both objective facts and subjective feelings in table-to-text generation models.
- The authors propose a novel approach called "Facts-and-Feelings" that aims to generate coherent and contextually appropriate text from tabular data, while accounting for both objective information and subjective sentiments.
- The paper presents experiments evaluating the performance of their approach on various datasets, and discusses the implications of their findings for the field of natural language generation.
Plain English Explanation
The paper looks at the problem of converting data stored in tables into written text. This is a common task in areas like data journalism, where journalists need to turn numbers and facts into easy-to-read articles.
The main challenge is that tables often contain a mix of objective information (like sales numbers) and more subjective elements (like people's opinions or emotions). Existing language models struggle to capture both the hard facts and the softer, more nuanced feelings in their text outputs.
The researchers developed a new approach called "Facts-and-Feelings" to address this. Their model tries to balance the objective data and the subjective perspectives when generating the final text. This allows the output to sound more natural and better reflect the full context of the information.
The paper presents experiments showing how this model performs compared to other methods. The results suggest the "Facts-and-Feelings" approach can produce more coherent and appropriate text that conveys both the factual details and the relevant feelings or opinions.
Overall, this work tackles an important challenge in natural language generation - the ability to seamlessly blend objective and subjective information in a way that reads as natural and meaningful to human readers. This could have valuable applications in fields like journalism, business reporting, and even personal data summaries.
Technical Explanation
The paper proposes a novel table-to-text generation model called "Facts-and-Feelings" that aims to capture both objective facts and subjective sentiments from tabular data.
The key innovation is the incorporation of a dedicated "feeling prediction" module, which learns to predict relevant emotions, opinions or other subjective attributes associated with the input data. This is combined with a more traditional fact-focused text generation component to produce the final output.
The authors evaluate their approach on several datasets, including [object Object] and [object Object]. The results show the "Facts-and-Feelings" model outperforms baseline methods on metrics like BLEU, METEOR and human evaluation, demonstrating its ability to generate more coherent and appropriate text that reflects both objective and subjective aspects of the input data.
The paper also discusses the limitations of large language models in fully capturing the nuances of table-to-text generation, as highlighted by prior work such as [object Object]. The "Facts-and-Feelings" approach aims to address some of these shortcomings by explicitly modeling the relationship between data and sentiment.
Critical Analysis
The "Facts-and-Feelings" approach presented in this paper is a promising step towards more holistic table-to-text generation that accounts for both objective information and subjective perspectives. The authors' insights on the importance of modeling sentiment in addition to facts are well-supported by their experimental results.
However, the paper does not fully explore the potential limitations or biases that may arise from the sentiment prediction component. There could be challenges in accurately capturing the nuanced, context-dependent nature of human emotions and opinions, especially when working with structured data.
Additionally, the paper focuses primarily on evaluating the model's performance through automatic metrics and human judgments. While valuable, these assessments may not fully uncover potential issues with the generated text, such as inconsistencies, factual errors, or unintended biases. Further analysis of the model's outputs and their real-world implications would be helpful.
Overall, the "Facts-and-Feelings" framework represents an important advancement in the field of table-to-text generation. But continued research is needed to address the potential pitfalls and ensure the responsible development of such systems, especially as they may be applied in high-stakes domains like journalism and decision-making.
Conclusion
This research paper introduces a novel "Facts-and-Feelings" approach to table-to-text generation that aims to capture both objective information and subjective sentiments in the generated text. The authors' experiments demonstrate the potential of this method to produce more coherent and contextually appropriate outputs compared to baseline models.
The work highlights the importance of considering subjective elements, such as opinions and emotions, alongside factual data when generating natural language from structured information. This has promising implications for applications in areas like data journalism, business reporting, and personal data summarization, where effectively communicating both objective details and subjective perspectives is crucial.
While the "Facts-and-Feelings" framework represents an important advancement, continued research is needed to fully address the potential limitations and ensure the responsible development of such systems. Ongoing exploration of sentiment modeling, output evaluation, and real-world applications will be essential in furthering the field of table-to-text generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Facts-and-Feelings: Capturing both Objectivity and Subjectivity in Table-to-Text Generation
Tathagata Dey, Pushpak Bhattacharyya
Table-to-text generation, a long-standing challenge in natural language generation, has remained unexplored through the lens of subjectivity. Subjectivity here encompasses the comprehension of information derived from the table that cannot be described solely by objective data. Given the absence of pre-existing datasets, we introduce the Ta2TS dataset with 3849 data instances. We perform the task of fine-tuning sequence-to-sequence models on the linearized tables and prompting on popular large language models. We analyze the results from a quantitative and qualitative perspective to ensure the capture of subjectivity and factual consistency. The analysis shows the fine-tuned LMs can perform close to the prompted LLMs. Both the models can capture the tabular data, generating texts with 85.15% BERTScore and 26.28% Meteor score. To the best of our knowledge, we provide the first-of-its-kind dataset on tables with multiple genres and subjectivity included and present the first comprehensive analysis and comparison of different LLM performances on this task.
Read more6/18/2024
0
Generating Tables from the Parametric Knowledge of Language Models
Yevgeni Berkovitch, Oren Glickman, Amit Somech, Tomer Wolfson
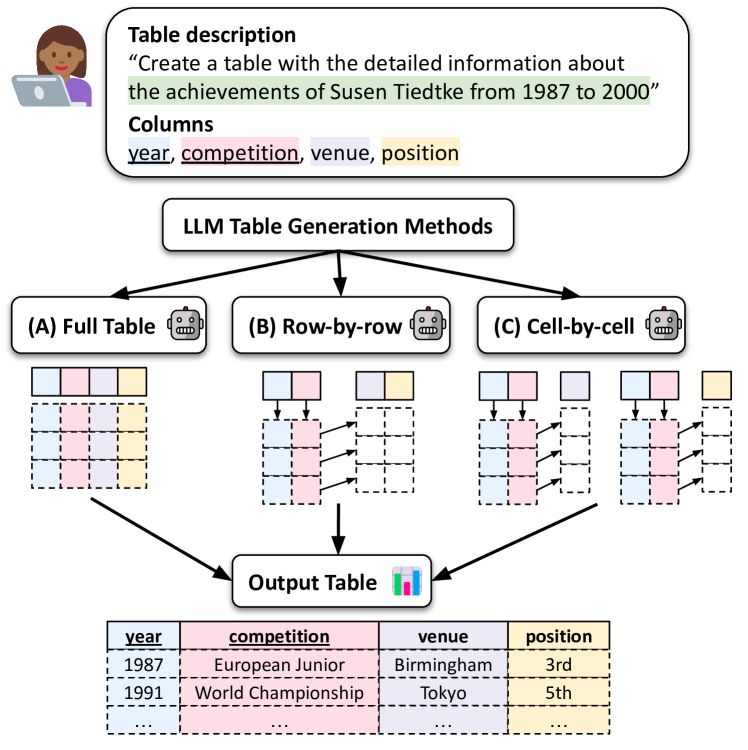
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
Read more6/18/2024
0
Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data
Dehai Min, Nan Hu, Rihui Jin, Nuo Lin, Jiaoyan Chen, Yongrui Chen, Yu Li, Guilin Qi, Yun Li, Nijun Li, Qianren Wang
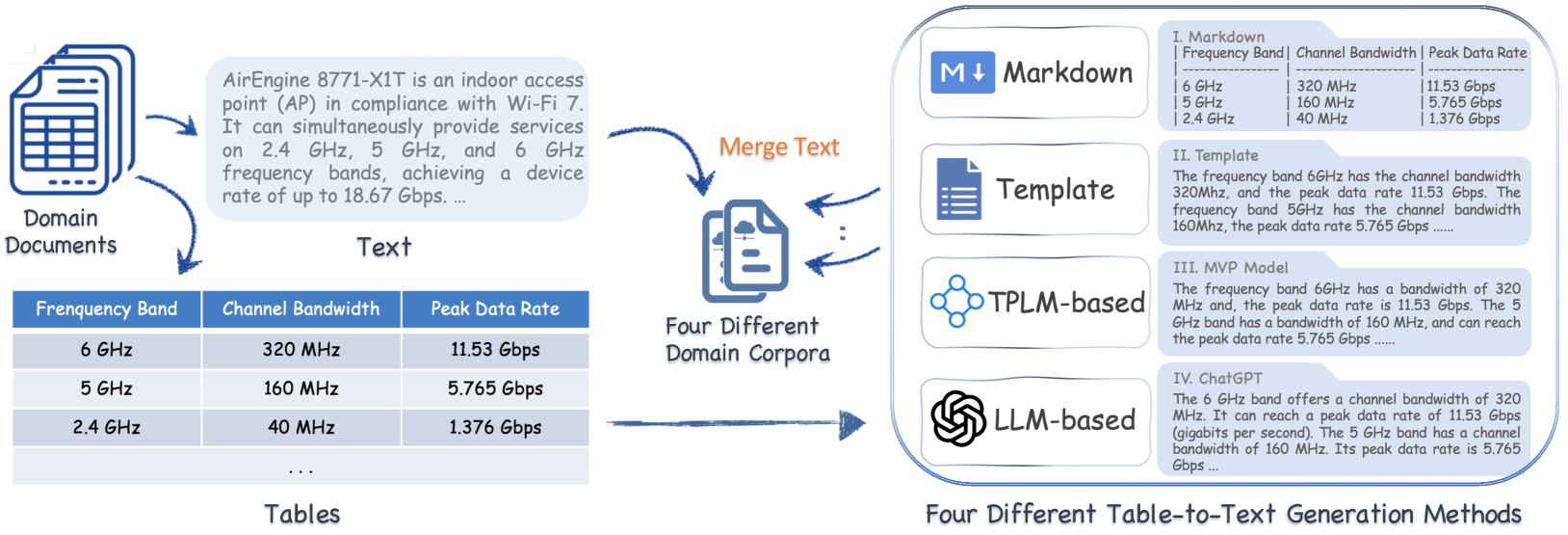
Augmenting Large Language Models (LLMs) for Question Answering (QA) with domain specific data has attracted wide attention. However, domain data often exists in a hybrid format, including text and semi-structured tables, posing challenges for the seamless integration of information. Table-to-Text Generation is a promising solution by facilitating the transformation of hybrid data into a uniformly text-formatted corpus. Although this technique has been widely studied by the NLP community, there is currently no comparative analysis on how corpora generated by different table-to-text methods affect the performance of QA systems. In this paper, we address this research gap in two steps. First, we innovatively integrate table-to-text generation into the framework of enhancing LLM-based QA systems with domain hybrid data. Then, we utilize this framework in real-world industrial data to conduct extensive experiments on two types of QA systems (DSFT and RAG frameworks) with four representative methods: Markdown format, Template serialization, TPLM-based method, and LLM-based method. Based on the experimental results, we draw some empirical findings and explore the underlying reasons behind the success of some methods. We hope the findings of this work will provide a valuable reference for the academic and industrial communities in developing robust QA systems.
Read more4/10/2024
💬
0
HeLM: Highlighted Evidence augmented Language Model for Enhanced Table-to-Text Generation
Junyi Bian, Xiaolei Qin, Wuhe Zou, Mengzuo Huang, Congyi Luo, Ke Zhang, Weidong Zhang
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
Read more4/30/2024