ITEACH-Net: Inverted Teacher-studEnt seArCH Network for Emotion Recognition in Conversation
2312.15583
0
0

Abstract
There remain two critical challenges that hinder the development of ERC. Firstly, there is a lack of exploration into mining deeper insights from the data itself for conversational emotion tasks. Secondly, the systems exhibit vulnerability to random modality feature missing, which is a common occurrence in realistic settings. Focusing on these two key challenges, we propose a novel framework for incomplete multimodal learning in ERC, called Inverted Teacher-studEnt seArCH Network (ITEACH-Net). ITEACH-Net comprises two novel components: the Emotion Context Changing Encoder (ECCE) and the Inverted Teacher-Student (ITS) framework. Specifically, leveraging the tendency for emotional states to exhibit local stability within conversational contexts, ECCE captures these patterns and further perceives their evolution over time. Recognizing the varying challenges of handling incomplete versus complete data, ITS employs a teacher-student framework to decouple the respective computations. Subsequently, through Neural Architecture Search, the student model develops enhanced computational capabilities for handling incomplete data compared to the teacher model. During testing, we design a novel evaluation method, testing the model's performance under different missing rate conditions without altering the model weights. We conduct experiments on three benchmark ERC datasets, and the results demonstrate that our ITEACH-Net outperforms existing methods in incomplete multimodal ERC. We believe ITEACH-Net can inspire relevant research on the intrinsic nature of emotions within conversation scenarios and pave a more robust route for incomplete learning techniques. Codes will be made available.
Create account to get full access
Overview
- This paper presents a Multimodal Neural Architecture Search (RMNAS) framework for robust multimodal sentiment analysis.
- RMNAS automatically searches for the optimal neural network architecture to combine text and visual data for sentiment classification.
- The proposed framework aims to improve the performance and robustness of multimodal sentiment analysis models.
Plain English Explanation
Sentiment analysis is the process of understanding the emotions or attitudes expressed in text or other media. Multimodal sentiment analysis combines information from different sources, like text and images, to make more accurate predictions about people's feelings.
However, traditional multimodal models can be fragile and perform poorly when faced with noisy or incomplete data. The RMNAS framework tries to address this by automatically designing neural network architectures that are more robust to these challenges.
The key idea is to use an automated neural architecture search process to find the best way to combine text and visual features for sentiment classification. This allows the model to learn the optimal way to leverage multiple data sources, rather than relying on a pre-defined architecture.
By making the model more flexible and adaptable, the RMNAS framework aims to improve the overall performance and reliability of multimodal sentiment analysis systems. This could have important applications in areas like customer service, social media monitoring, and mental health assessment.
Technical Explanation
The RMNAS framework consists of several key components:
-
Multimodal Feature Extractor: This module takes text and visual inputs and extracts relevant features from each modality using pre-trained neural networks.
-
Neural Architecture Search: An automated neural architecture search process is used to explore different ways of combining the extracted features for sentiment classification. This includes trying out various neural network layer types, connectivity patterns, and hyperparameters.
-
Robustness Evaluation: During the search process, the candidate architectures are evaluated not only on their classification accuracy, but also on their robustness to simulated perturbations of the input data. This ensures the final model can handle noisy or incomplete inputs.
-
Multitask Learning: The framework uses a multitask learning approach, where the model is trained not only on the primary sentiment classification task, but also on auxiliary tasks like emotion recognition. This helps the model learn more generalizable and robust representations.
The authors evaluate the RMNAS framework on several benchmark multimodal sentiment analysis datasets. They show that the automatically searched architectures outperform manually designed baselines in terms of both accuracy and robustness to simulated perturbations.
Critical Analysis
The RMNAS framework represents an interesting and promising approach to improving the performance and reliability of multimodal sentiment analysis systems. By using an automated architecture search process, the model can adapt to the specific characteristics of the task and data, rather than relying on a pre-defined architecture.
However, the paper does not provide a detailed analysis of the computational cost and resource requirements of the neural architecture search process. This is an important consideration, as such search procedures can be computationally intensive, limiting their practical applicability.
Additionally, the authors only evaluate the framework on simulated perturbations of the input data. It would be valuable to see how the models perform on real-world noisy or incomplete data, which may have different characteristics than the artificially generated perturbations.
Finally, the paper does not provide much insight into the specific architectural choices made by the search process. Understanding the factors that contribute to the improved robustness could help inform the design of future multimodal sentiment analysis models.
Conclusion
The RMNAS framework presents a novel approach to improving the performance and robustness of multimodal sentiment analysis models. By automatically searching for the optimal neural network architecture to combine text and visual features, the framework can adapt to the specific characteristics of the task and data, leading to improved classification accuracy and resilience to noisy or incomplete inputs.
While the paper demonstrates promising results, further research is needed to address the computational cost of the search process and to evaluate the models on real-world noisy data. Additionally, a deeper understanding of the architectural choices made by the framework could provide valuable insights for the design of future multimodal sentiment analysis systems.
Overall, the RMNAS framework represents an important step towards more reliable and robust multimodal sentiment analysis, with potential applications in a wide range of domains, from customer service to mental health assessment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Deep Emotion Recognition in Textual Conversations: A Survey
Patr'icia Pereira, Helena Moniz, Joao Paulo Carvalho
0
0
While Emotion Recognition in Conversations (ERC) has seen a tremendous advancement in the last few years, new applications and implementation scenarios present novel challenges and opportunities. These range from leveraging the conversational context, speaker and emotion dynamics modelling, to interpreting common sense expressions, informal language and sarcasm, addressing challenges of real time ERC, recognizing emotion causes, different taxonomies across datasets, multilingual ERC to interpretability. This survey starts by introducing ERC, elaborating on the challenges and opportunities pertaining to this task. It proceeds with a description of the emotion taxonomies and a variety of ERC benchmark datasets employing such taxonomies. This is followed by descriptions of the most prominent works in ERC with explanations of the Deep Learning architectures employed. Then, it provides advisable ERC practices towards better frameworks, elaborating on methods to deal with subjectivity in annotations and modelling and methods to deal with the typically unbalanced ERC datasets. Finally, it presents systematic review tables comparing several works regarding the methods used and their performance. The survey highlights the advantage of leveraging techniques to address unbalanced data, the exploration of mixed emotions and the benefits of incorporating annotation subjectivity in the learning phase.
5/24/2024
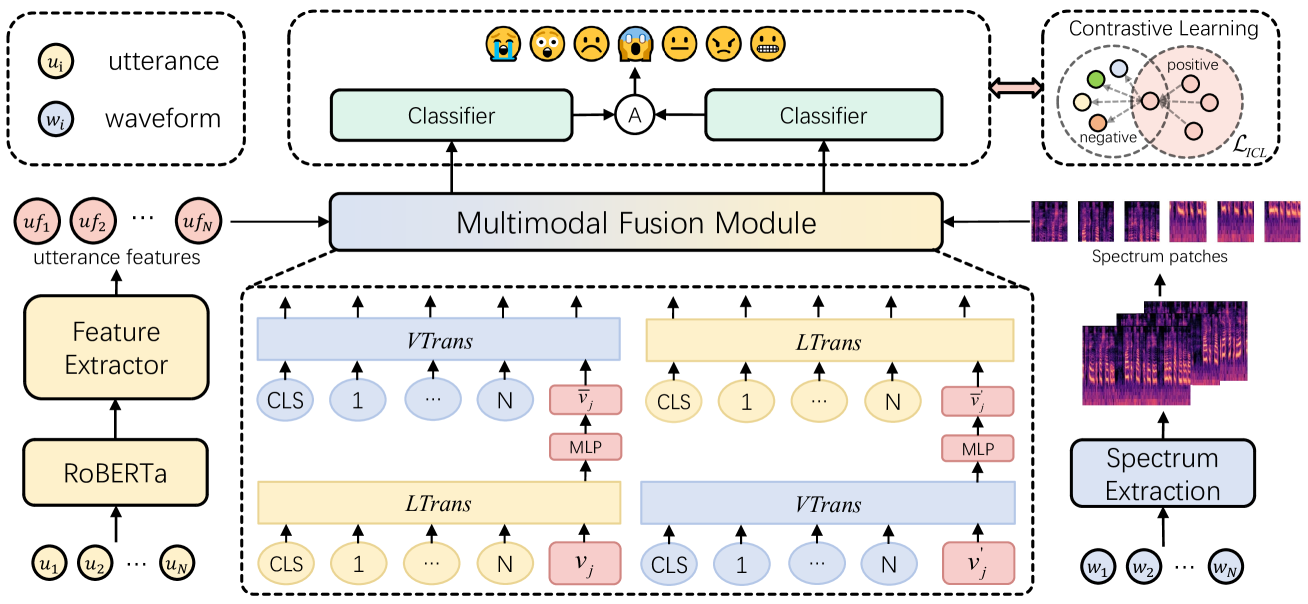
Enhancing Emotion Recognition in Conversation through Emotional Cross-Modal Fusion and Inter-class Contrastive Learning
Haoxiang Shi, Xulong Zhang, Ning Cheng, Yong Zhang, Jun Yu, Jing Xiao, Jianzong Wang
0
0
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual information. Previous ERC methods relied on simple connections for cross-modal fusion and ignored the information differences between modalities, resulting in the model being unable to focus on modality-specific emotional information. At the same time, the shared information between modalities was not processed to generate emotions. Information redundancy problem. To overcome these limitations, we propose a cross-modal fusion emotion prediction network based on vector connections. The network mainly includes two stages: the multi-modal feature fusion stage based on connection vectors and the emotion classification stage based on fused features. Furthermore, we design a supervised inter-class contrastive learning module based on emotion labels. Experimental results confirm the effectiveness of the proposed method, demonstrating excellent performance on the IEMOCAP and MELD datasets.
5/29/2024

Emotion-Anchored Contrastive Learning Framework for Emotion Recognition in Conversation
Fangxu Yu, Junjie Guo, Zhen Wu, Xinyu Dai
0
0
Emotion Recognition in Conversation (ERC) involves detecting the underlying emotion behind each utterance within a conversation. Effectively generating representations for utterances remains a significant challenge in this task. Recent works propose various models to address this issue, but they still struggle with differentiating similar emotions such as excitement and happiness. To alleviate this problem, We propose an Emotion-Anchored Contrastive Learning (EACL) framework that can generate more distinguishable utterance representations for similar emotions. To achieve this, we utilize label encodings as anchors to guide the learning of utterance representations and design an auxiliary loss to ensure the effective separation of anchors for similar emotions. Moreover, an additional adaptation process is proposed to adapt anchors to serve as effective classifiers to improve classification performance. Across extensive experiments, our proposed EACL achieves state-of-the-art emotion recognition performance and exhibits superior performance on similar emotions. Our code is available at https://github.com/Yu-Fangxu/EACL.
4/1/2024

IITK at SemEval-2024 Task 10: Who is the speaker? Improving Emotion Recognition and Flip Reasoning in Conversations via Speaker Embeddings
Shubham Patel, Divyaksh Shukla, Ashutosh Modi
0
0
This paper presents our approach for the SemEval-2024 Task 10: Emotion Discovery and Reasoning its Flip in Conversations. For the Emotion Recognition in Conversations (ERC) task, we utilize a masked-memory network along with speaker participation. We propose a transformer-based speaker-centric model for the Emotion Flip Reasoning (EFR) task. We also introduce Probable Trigger Zone, a region of the conversation that is more likely to contain the utterances causing the emotion to flip. For sub-task 3, the proposed approach achieves a 5.9 (F1 score) improvement over the task baseline. The ablation study results highlight the significance of various design choices in the proposed method.
4/9/2024