Iterative Translation Refinement with Large Language Models
2306.03856
0
0
💬
Abstract
We propose iteratively prompting a large language model to self-correct a translation, with inspiration from their strong language understanding and translation capability as well as a human-like translation approach. Interestingly, multi-turn querying reduces the output's string-based metric scores, but neural metrics suggest comparable or improved quality. Human evaluations indicate better fluency and naturalness compared to initial translations and even human references, all while maintaining quality. Ablation studies underscore the importance of anchoring the refinement to the source and a reasonable seed translation for quality considerations. We also discuss the challenges in evaluation and relation to human performance and translationese.
Create account to get full access
Overview
- The researchers propose an iterative approach to refine a language model's translation output.
- Their method leverages the language understanding and translation capabilities of large language models, similar to how humans might revise a translation.
- Interestingly, multiple rounds of refinement can reduce string-based metric scores, but neural metrics suggest the quality is maintained or even improved.
- Human evaluations indicate the refined translations have better fluency and naturalness compared to initial translations and even human references.
- Anchoring the refinement to the source text and a reasonable initial translation is crucial for maintaining quality.
- The paper discusses the challenges in evaluating these models and their relationship to human translation performance.
Plain English Explanation
The researchers explored a new way to improve the quality of machine translations using large language models. [https://aimodels.fyi/papers/arxiv/guiding-large-language-models-to-post-edit]
Instead of translating text in a single pass, they had the language model go through an iterative process of "self-correction." The model would start with an initial translation and then repeatedly refine it, similar to how a human translator might revise their work.
The researchers found that this iterative approach can lead to translations that are more natural and fluent, even compared to professional human translations. [https://aimodels.fyi/papers/arxiv/novel-paradigm-boosting-translation-capabilities-large-language]
Interestingly, the refined translations did not always score as highly on traditional string-based metrics. However, more advanced neural metrics suggested the quality was maintained or even improved. [https://aimodels.fyi/papers/arxiv/towards-large-language-model-driven-reference-less]
The key to making this work was anchoring the refinement process to both the original source text and a reasonable starting translation. This helped the model stay on track and produce high-quality results. [https://aimodels.fyi/papers/arxiv/eliciting-translation-ability-large-language-models-via]
Overall, this research explores a new way to harness the impressive language abilities of large models to enhance machine translation, potentially bringing us closer to human-level performance. [https://aimodels.fyi/papers/arxiv/fine-tuning-large-language-models-to-translate]
Technical Explanation
The researchers propose an iterative approach to refine the output of a large language model for translation tasks. They draw inspiration from the strong language understanding and translation capabilities of these models, as well as the human-like process of revising a translation.
In their method, the model starts with an initial translation and then goes through multiple rounds of refinement, where it can modify the translation based on the source text. Interestingly, the researchers found that this iterative process can lead to translations that score lower on traditional string-based metrics, but perform better on more advanced neural metrics that capture aspects of fluency and naturalness.
Human evaluations confirm this, indicating that the refined translations have improved fluency and naturalness compared to the initial translations and even human references. The researchers highlight the importance of anchoring the refinement process to both the source text and a reasonable seed translation, as this helps maintain the overall quality of the output.
The paper also discusses the challenges in evaluating these models, including the limitations of existing metrics and the relationship between machine and human translation performance. They suggest that the refinement process may help reduce "translationese" - the unnatural artifacts that can sometimes appear in machine translations.
Critical Analysis
The researchers present a novel and interesting approach to leveraging large language models for translation tasks. By allowing the model to iteratively refine its own output, they are able to produce translations that are more fluent and natural, which is an important aspect of high-quality translation.
However, the reliance on neural metrics to assess quality is a potential limitation, as these metrics may not fully capture all aspects of translation quality. The researchers acknowledge this and suggest that a combination of automated and human evaluation is needed to fully understand the capabilities of their approach.
Additionally, the paper does not provide a detailed analysis of the types of errors or issues that the iterative refinement process is able to address. Understanding the specific ways in which this approach improves upon initial translations could help inform future research and development in this area.
It would also be interesting to see how this approach compares to other state-of-the-art translation techniques, such as fine-tuning large language models on translation tasks or using specialized translation architectures. [https://aimodels.fyi/papers/arxiv/fine-tuning-large-language-models-to-translate]
Overall, the researchers have presented a promising direction for enhancing machine translation capabilities, and their work highlights the potential of large language models to tackle complex language tasks in novel ways.
Conclusion
The researchers have proposed an innovative approach to improving machine translation by having large language models iteratively refine their own output. This process leverages the models' strong language understanding and translation abilities, similar to how a human translator might revise a translation.
Interestingly, the refined translations scored lower on traditional string-based metrics but performed better on more advanced neural metrics, as well as in human evaluations of fluency and naturalness. This suggests that the iterative refinement process can produce translations that are more natural and human-like, while maintaining overall quality.
The researchers emphasize the importance of anchoring the refinement to both the source text and a reasonable initial translation, which helps the model stay on track and avoid introducing errors. Their work highlights the potential of large language models to tackle complex language tasks in novel ways, and opens up new avenues for enhancing machine translation capabilities.
As the field of natural language processing continues to advance, approaches like the one presented in this paper may bring us closer to human-level translation performance and help bridge the gap between machine and human translation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
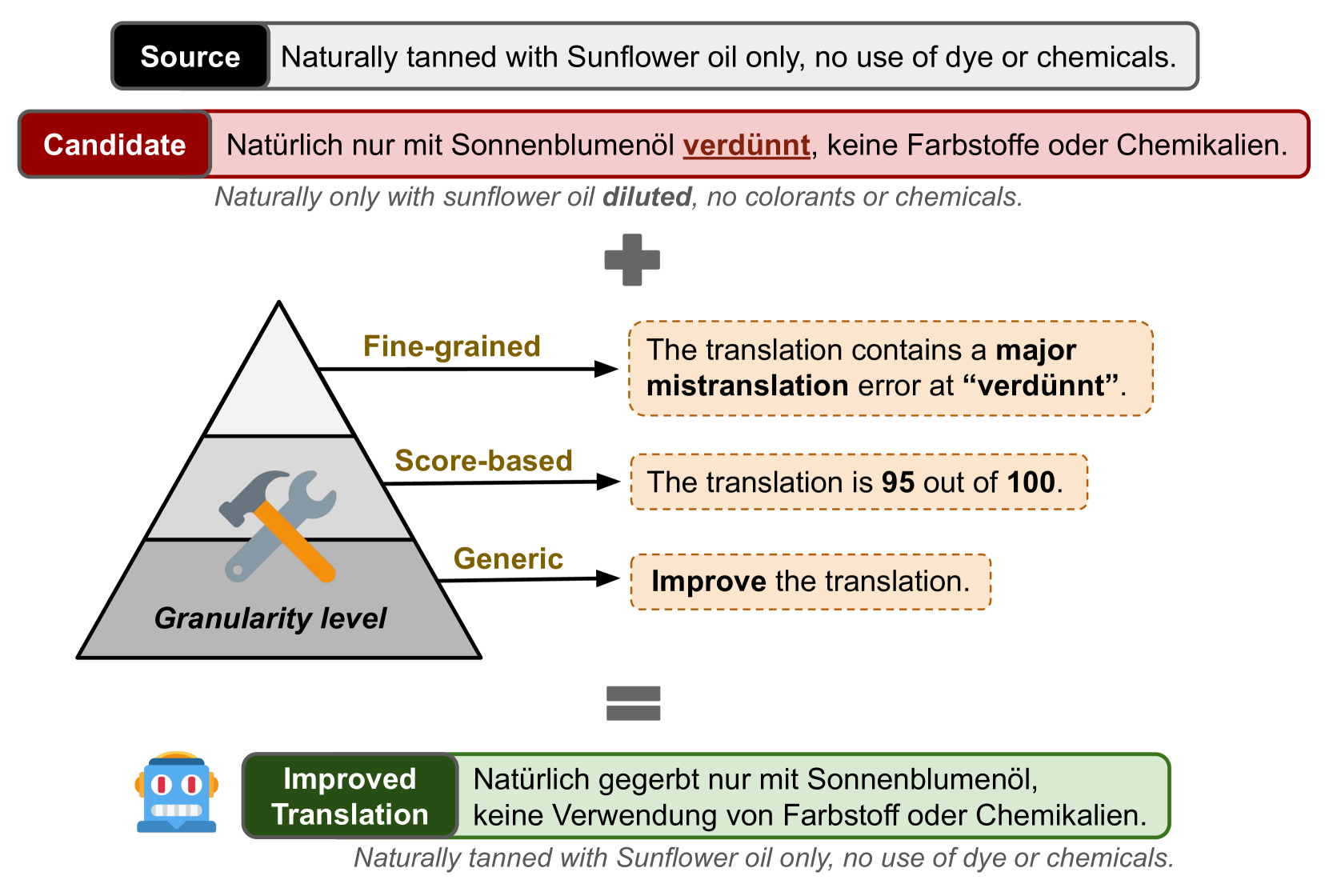
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
0
0
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
4/12/2024

GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024
💬
Lost in the Source Language: How Large Language Models Evaluate the Quality of Machine Translation
Xu Huang, Zhirui Zhang, Xiang Geng, Yichao Du, Jiajun Chen, Shujian Huang
0
0
This study investigates how Large Language Models (LLMs) leverage source and reference data in machine translation evaluation task, aiming to better understand the mechanisms behind their remarkable performance in this task. We design the controlled experiments across various input modes and model types, and employ both coarse-grained and fine-grained prompts to discern the utility of source versus reference information. We find that reference information significantly enhances the evaluation accuracy, while surprisingly, source information sometimes is counterproductive, indicating LLMs' inability to fully leverage the cross-lingual capability when evaluating translations. Further analysis of the fine-grained evaluation and fine-tuning experiments show similar results. These findings also suggest a potential research direction for LLMs that fully exploits the cross-lingual capability of LLMs to achieve better performance in machine translation evaluation tasks.
6/7/2024
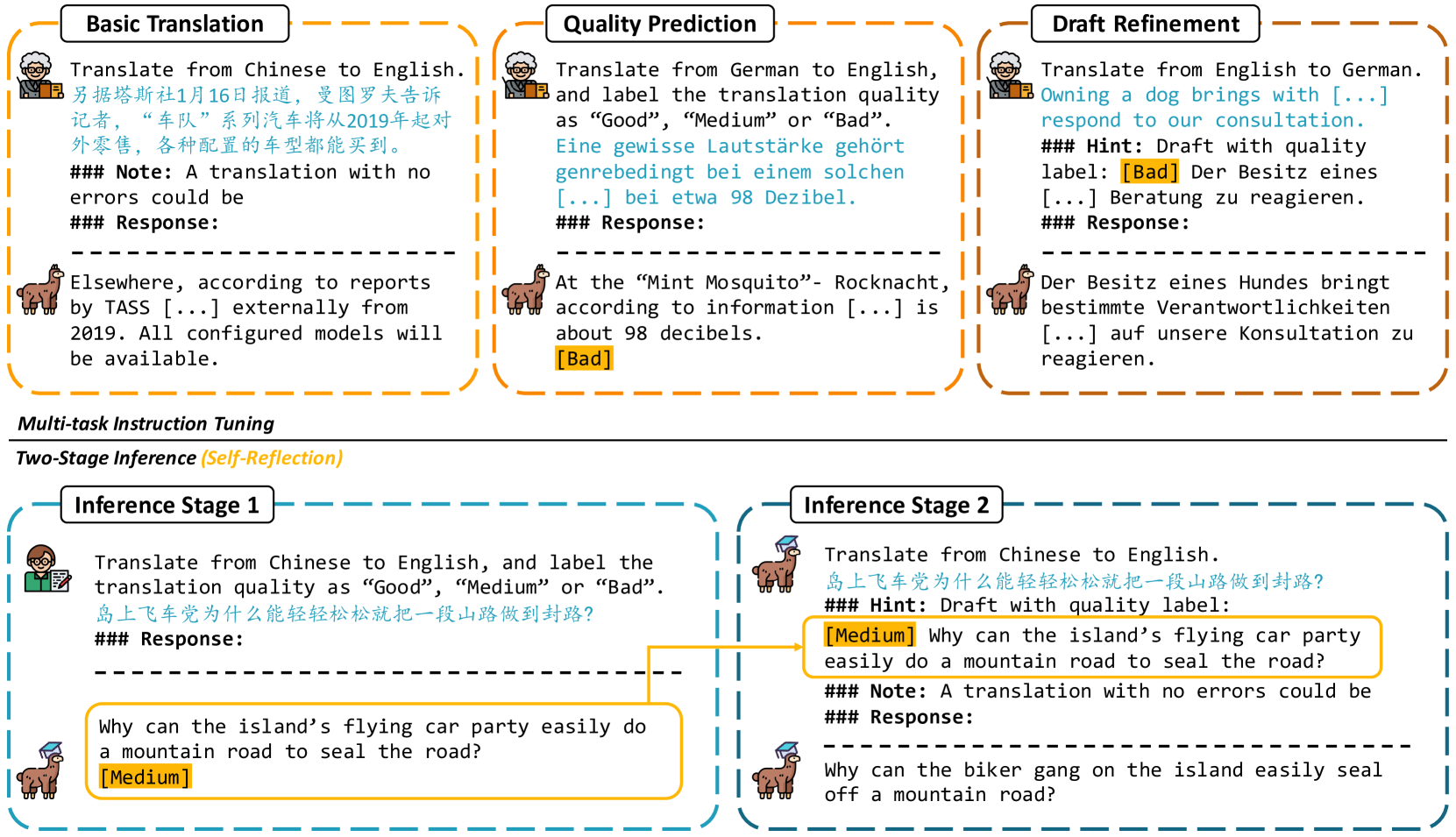
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
0
0
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
6/13/2024