TasTe: Teaching Large Language Models to Translate through Self-Reflection
2406.08434
0
0
Abstract
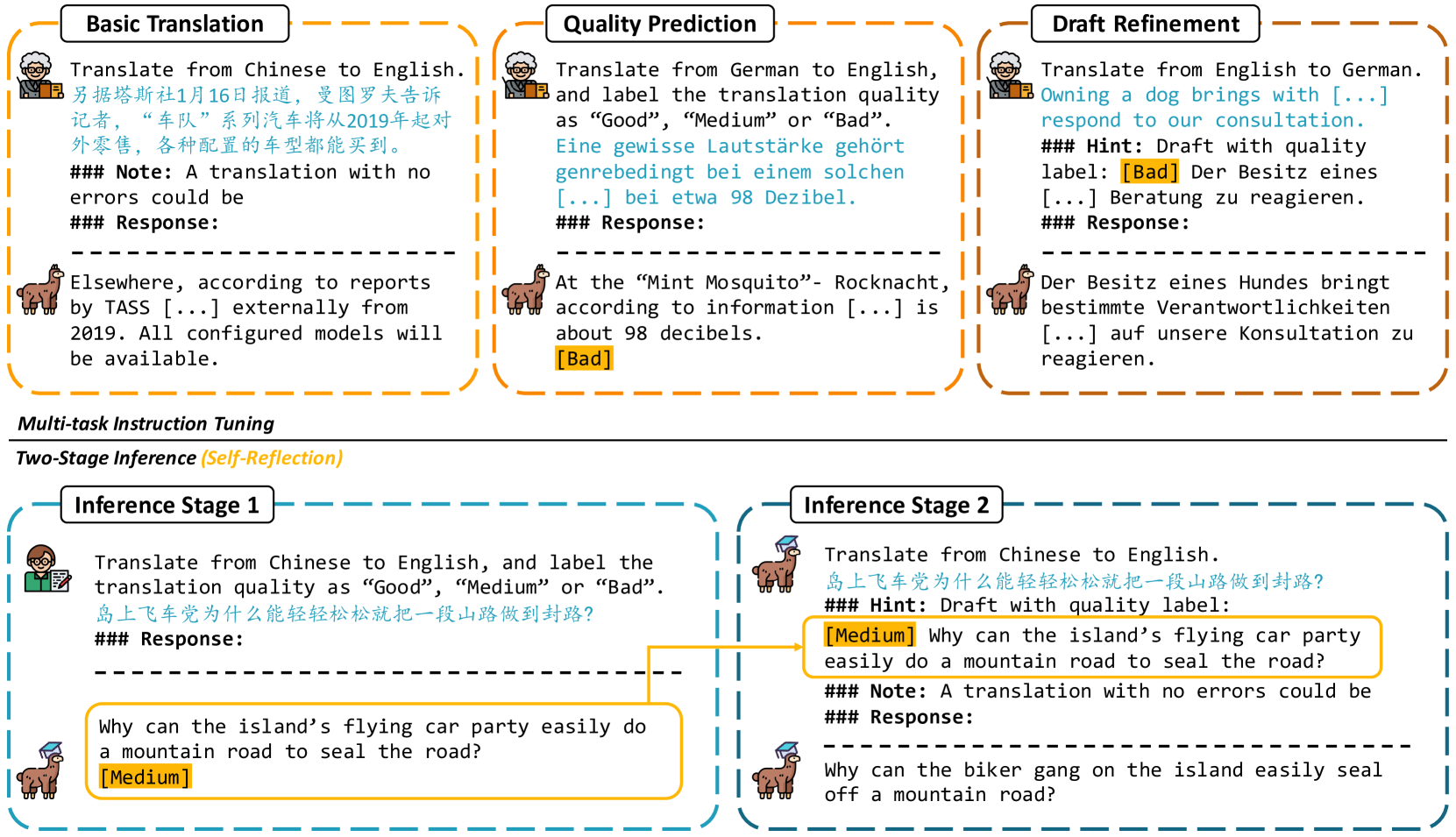
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
Create account to get full access
Overview
- This paper introduces TasTe, a novel method for teaching large language models to translate through self-reflection.
- The key idea is to enable language models to assess their own translation quality and improve through iterative self-reflection.
- The authors demonstrate that TasTe outperforms traditional translation approaches, especially for low-resource language pairs.
Plain English Explanation
The paper describes a new way to train large language models to be better at translation tasks. The key innovation is the concept of "self-reflection" - the ability for the model to assess the quality of its own translations and then use that feedback to improve over time.
The traditional approach to machine translation relies on large datasets of human-translated text to train the model. However, for many language pairs, high-quality training data is scarce, which limits the model's performance.
With TasTe, the model is trained to not only generate translations, but also to evaluate its own work. It can then use that self-assessment to refine its translation abilities, without needing as much external training data. This is especially helpful for translating between languages that don't have a lot of existing translation examples available.
The authors show through experiments that TasTe-trained models outperform standard translation approaches, particularly for language pairs with limited resources. By empowering the models to learn from their own mistakes and continuously improve, the system is able to achieve better results even in low-data scenarios.
Technical Explanation
The paper introduces TasTe, a novel technique for training large language models to perform machine translation tasks more effectively, especially for language pairs with limited training data.
The key innovation in TasTe is the addition of a "self-reflection" component to the translation model. Traditionally, machine translation models are trained on large parallel datasets of human-translated text, which they use to learn how to map between source and target languages.
However, for many language pairs, high-quality parallel data is scarce. To address this, TasTe trains the model to not only generate translations, but also to assess the quality of its own output. This self-reflection ability allows the model to identify its own mistakes and weaknesses, and then use that information to iteratively improve its translation capabilities.
The TasTe framework consists of several key components:
-
Encoder-Decoder Translation Model: The core of the system is a transformer-based encoder-decoder architecture that maps input text in the source language to output text in the target language.
-
Quality Evaluation Model: This component takes the model's own translation output and predicts a quality score, indicating how well the translation was performed.
-
Self-Reflection Loop: The quality score is then used to update the translation model, allowing it to learn from its mistakes and refine its abilities through successive rounds of self-evaluation and improvement.
The authors demonstrate the effectiveness of TasTe through experiments on several language translation tasks, including low-resource pairs. They show that TasTe-trained models significantly outperform standard translation approaches, particularly when parallel data is limited.
Critical Analysis
The TasTe framework represents an innovative approach to improving machine translation, especially for language pairs with scarce training data. By empowering models to assess and refine their own abilities, the authors have found a way to boost performance in challenging scenarios.
However, the paper does acknowledge some potential limitations and areas for further research. For example, the self-reflection component adds additional complexity to the model, which could impact training time and computational requirements. Additionally, the authors note that the quality evaluation model may not always accurately capture nuanced aspects of translation quality.
Further research could explore ways to make the self-reflection process more efficient and robust, potentially by incorporating external quality signals or leveraging other techniques like reinforcement learning. Investigating the broader applicability of the TasTe approach to other language tasks beyond translation would also be an interesting direction.
Overall, the TasTe method represents an important step forward in enhancing the capabilities of large language models, and the principles of self-reflection and iterative improvement could have far-reaching implications for the field of natural language processing.
Conclusion
The TasTe paper presents a novel approach to improving machine translation by teaching large language models to assess and refine their own translation abilities through self-reflection. By empowering models to identify and learn from their own mistakes, the authors demonstrate significant performance gains, especially for language pairs with limited training data.
While the added complexity of the self-reflection component presents some challenges, the TasTe framework shows great promise in advancing the state-of-the-art in machine translation and potentially other language tasks. As the field of natural language processing continues to evolve, techniques like those introduced in this paper will likely play a crucial role in developing more capable and adaptable language models that can overcome the limitations of traditional approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
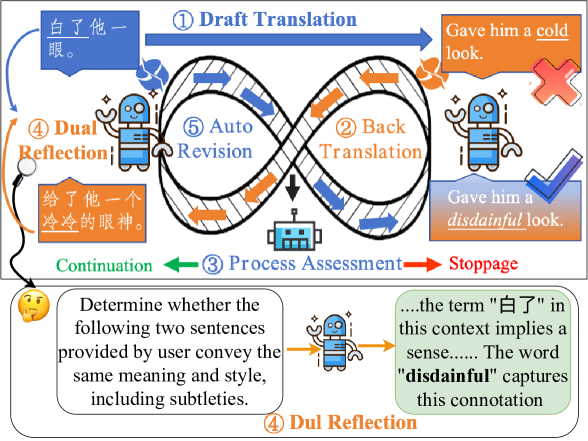
DUAL-REFLECT: Enhancing Large Language Models for Reflective Translation through Dual Learning Feedback Mechanisms
Andong Chen, Lianzhang Lou, Kehai Chen, Xuefeng Bai, Yang Xiang, Muyun Yang, Tiejun Zhao, Min Zhang
0
0
Recently, large language models (LLMs) enhanced by self-reflection have achieved promising performance on machine translation. The key idea is guiding LLMs to generate translation with human-like feedback. However, existing self-reflection methods lack effective feedback information, limiting the translation performance. To address this, we introduce a DUAL-REFLECT framework, leveraging the dual learning of translation tasks to provide effective feedback, thereby enhancing the models' self-reflective abilities and improving translation performance. The application of this method across various translation tasks has proven its effectiveness in improving translation accuracy and eliminating ambiguities, especially in translation tasks with low-resource language pairs.
6/24/2024
💬
Supporting Self-Reflection at Scale with Large Language Models: Insights from Randomized Field Experiments in Classrooms
Harsh Kumar, Ruiwei Xiao, Benjamin Lawson, Ilya Musabirov, Jiakai Shi, Xinyuan Wang, Huayin Luo, Joseph Jay Williams, Anna Rafferty, John Stamper, Michael Liut
0
0
Self-reflection on learning experiences constitutes a fundamental cognitive process, essential for the consolidation of knowledge and the enhancement of learning efficacy. However, traditional methods to facilitate reflection often face challenges in personalization, immediacy of feedback, engagement, and scalability. Integration of Large Language Models (LLMs) into the reflection process could mitigate these limitations. In this paper, we conducted two randomized field experiments in undergraduate computer science courses to investigate the potential of LLMs to help students engage in post-lesson reflection. In the first experiment (N=145), students completed a take-home assignment with the support of an LLM assistant; half of these students were then provided access to an LLM designed to facilitate self-reflection. The results indicated that the students assigned to LLM-guided reflection reported increased self-confidence and performed better on a subsequent exam two weeks later than their peers in the control condition. In the second experiment (N=112), we evaluated the impact of LLM-guided self-reflection against other scalable reflection methods, such as questionnaire-based activities and review of key lecture slides, after assignment. Our findings suggest that the students in the questionnaire and LLM-based reflection groups performed equally well and better than those who were only exposed to lecture slides, according to their scores on a proctored exam two weeks later on the same subject matter. These results underscore the utility of LLM-guided reflection and questionnaire-based activities in improving learning outcomes. Our work highlights that focusing solely on the accuracy of LLMs can overlook their potential to enhance metacognitive skills through practices such as self-reflection. We discuss the implications of our research for the Edtech community.
6/13/2024
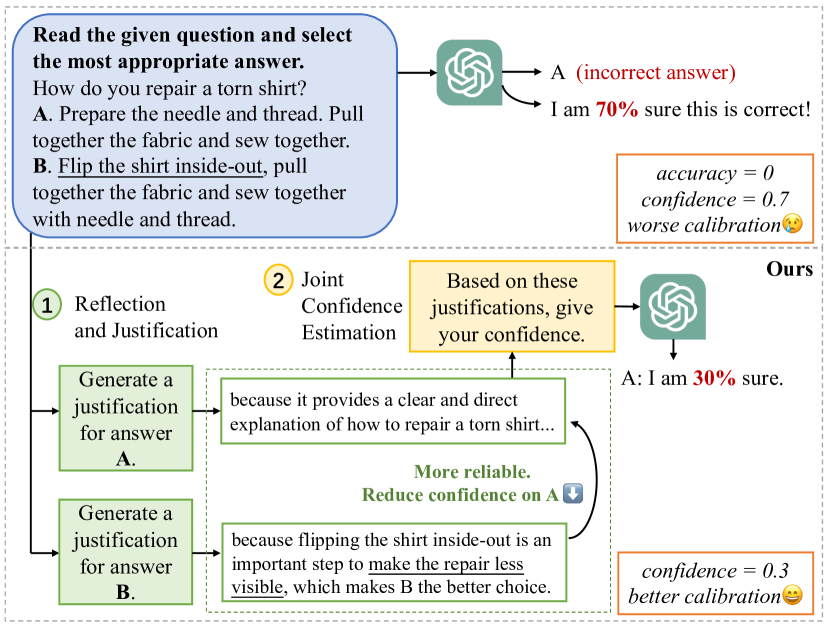
Think Twice Before Trusting: Self-Detection for Large Language Models through Comprehensive Answer Reflection
Moxin Li, Wenjie Wang, Fuli Feng, Fengbin Zhu, Qifan Wang, Tat-Seng Chua
0
0
Self-detection for Large Language Model (LLM) seeks to evaluate the LLM output trustability by leveraging LLM's own capabilities, alleviating the output hallucination issue. However, existing self-detection approaches only retrospectively evaluate answers generated by LLM, typically leading to the over-trust in incorrectly generated answers. To tackle this limitation, we propose a novel self-detection paradigm that considers the comprehensive answer space beyond LLM-generated answers. It thoroughly compares the trustability of multiple candidate answers to mitigate the over-trust in LLM-generated incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each candidate answer, and then aggregates the justifications for comprehensive target answer evaluation. This framework can be seamlessly integrated with existing approaches for superior self-detection. Extensive experiments on six datasets spanning three tasks demonstrate the effectiveness of the proposed framework.
6/5/2024
💬
METAREFLECTION: Learning Instructions for Language Agents using Past Reflections
Priyanshu Gupta, Shashank Kirtania, Ananya Singha, Sumit Gulwani, Arjun Radhakrishna, Sherry Shi, Gustavo Soares
0
0
Despite the popularity of Large Language Models (LLMs), crafting specific prompts for LLMs to perform particular tasks remains challenging. Users often engage in multiple conversational turns with an LLM-based agent to accomplish their intended task. Recent studies have demonstrated that linguistic feedback, in the form of self-reflections generated by the model, can work as reinforcement during these conversations, thus enabling quicker convergence to the desired outcome. Motivated by these findings, we introduce METAREFLECTION, a novel technique that learns general prompt instructions for a specific domain from individual self-reflections gathered during a training phase. We evaluate our technique in two domains: Infrastructure as Code (IAC) vulnerability detection and question-answering (QA) using REACT and COT. Our results demonstrate a notable improvement, with METARELECTION outperforming GPT-4 by 16.82% (IAC), 31.33% (COT), and 15.42% (REACT), underscoring the potential of METAREFLECTION as a viable method for enhancing the efficiency of LLMs.
5/24/2024