iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection
2404.05207
0
0

Abstract
Recent progress has shown great potential of visual prompt tuning (VPT) when adapting pre-trained vision transformers to various downstream tasks. However, most existing solutions independently optimize prompts at each layer, thereby neglecting the usage of task-relevant information encoded in prompt tokens across layers. Additionally, existing prompt structures are prone to interference from task-irrelevant noise in input images, which can do harm to the sharing of task-relevant information. In this paper, we propose a novel VPT approach, textbf{iVPT}. It innovatively incorporates a cross-layer dynamic connection (CDC) for input prompt tokens from adjacent layers, enabling effective sharing of task-relevant information. Furthermore, we design a dynamic aggregation (DA) module that facilitates selective sharing of information between layers. The combination of CDC and DA enhances the flexibility of the attention process within the VPT framework. Building upon these foundations, iVPT introduces an attentive reinforcement (AR) mechanism, by automatically identifying salient image tokens, which are further enhanced by prompt tokens in an additive manner. Extensive experiments on 24 image classification and semantic segmentation benchmarks clearly demonstrate the advantage of the proposed iVPT, compared to the state-of-the-art counterparts.
Create account to get full access
Overview
- This paper introduces iVPT (Improving Visual Prompt Tuning), a method to enhance task-relevant information sharing in visual prompt tuning.
- Visual prompt tuning is a technique that fine-tunes pre-trained language models for visual tasks by learning task-specific prompts.
- The key idea of iVPT is to enable dynamic cross-layer connections between the prompt and the model's internal representations, allowing for more effective transfer of task-relevant information.
Plain English Explanation
Visual prompt tuning is a way to adapt powerful language models, like those used for text generation, to work with visual data. The idea is to learn a special "prompt" that can steer the language model to perform well on a specific visual task, without having to retrain the entire model from scratch.
The iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection paper proposes a way to make this visual prompt tuning process more effective. Instead of just learning a static prompt, iVPT allows the prompt to dynamically interact with different layers of the language model. This enables the prompt to better capture and leverage the task-relevant information within the model, leading to improved performance on the visual task.
The key insight is that different layers of a language model capture different types of information - some layers may focus more on high-level semantics, while others encode more low-level visual features. By allowing the prompt to adapt and connect to these various layers, iVPT can help the model better understand the visual task at hand and generate more accurate outputs.
This dynamic connection between the prompt and the model's internal representations is the core innovation of iVPT, and it sets it apart from more traditional visual prompt tuning approaches. The paper demonstrates the effectiveness of iVPT on a range of visual tasks, showing consistent improvements over existing methods.
Technical Explanation
The iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection paper proposes a novel architecture, called iVPT, that enhances the task-relevant information sharing in visual prompt tuning.
In visual prompt tuning, a task-specific prompt is learned and appended to the input of a pre-trained language model to fine-tune it for visual tasks. The key innovation of iVPT is the introduction of a cross-layer dynamic connection mechanism, which allows the prompt to dynamically interact with different layers of the language model.
Specifically, iVPT consists of a prompt encoder and a cross-layer connection module. The prompt encoder learns a prompt representation that captures task-relevant information. The cross-layer connection module then dynamically combines the prompt representation with the activations of different layers in the language model, enabling the prompt to selectively attend to and leverage the most relevant information for the given visual task.
The authors conduct extensive experiments on a range of visual tasks, including image classification, object detection, and segmentation. The results show that iVPT consistently outperforms traditional visual prompt tuning approaches, demonstrating the effectiveness of the proposed cross-layer dynamic connection mechanism.
Furthermore, the authors provide detailed ablation studies to analyze the contributions of the different components of iVPT, such as the prompt encoder and the cross-layer connection module. These insights can help inform the development of future visual prompt tuning techniques.
Critical Analysis
The iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection paper presents a compelling and well-designed approach to enhance visual prompt tuning. The key strength of the paper is the introduction of the cross-layer dynamic connection mechanism, which allows the prompt to effectively leverage task-relevant information from different layers of the language model.
One potential limitation of the paper is the focus on a relatively narrow set of visual tasks, such as image classification, object detection, and segmentation. It would be interesting to see how iVPT performs on a broader range of visual tasks, including more complex or multi-modal scenarios. Additionally, the paper does not provide a detailed analysis of the computational and memory overhead of the iVPT approach compared to traditional visual prompt tuning methods.
Another area for further research could be the exploration of more advanced prompt encoding techniques, beyond the simple prompt encoder used in this paper. More sophisticated prompt representations, potentially informed by the Tailored Visions: Enhancing Text-to-Image Generation with Prompts or Finding Visual Task Vectors approaches, could further improve the effectiveness of iVPT.
Additionally, it would be interesting to investigate the potential of iVPT in the context of continual learning, where the model needs to adapt to a sequence of visual tasks over time. The dynamic cross-layer connections could potentially help the model better retain and transfer task-relevant information between tasks.
Overall, the iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection paper presents a promising and innovative approach to visual prompt tuning, with the potential for further advancements in the field of multi-modal AI systems.
Conclusion
The iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection paper introduces a novel method, called iVPT, that enhances the task-relevant information sharing in visual prompt tuning. By enabling dynamic cross-layer connections between the prompt and the language model's internal representations, iVPT allows for more effective transfer of task-relevant information, leading to improved performance on a range of visual tasks.
The key innovation of iVPT is the cross-layer dynamic connection mechanism, which sets it apart from traditional visual prompt tuning approaches. This mechanism enables the prompt to selectively attend to and leverage the most relevant information from different layers of the language model, leading to more accurate outputs.
The paper's extensive experimental results demonstrate the effectiveness of iVPT, with consistent improvements over existing visual prompt tuning methods. While the paper focuses on a relatively narrow set of visual tasks, the dynamic cross-layer connections introduced by iVPT have the potential to be beneficial in a wider range of multi-modal AI applications, including continual learning scenarios.
Overall, the iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection paper presents an important contribution to the field of visual prompt tuning, with promising implications for the development of more capable and adaptable multi-modal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Revisiting the Power of Prompt for Visual Tuning
Yuzhu Wang, Lechao Cheng, Chaowei Fang, Dingwen Zhang, Manni Duan, Meng Wang
0
0
Visual prompt tuning (VPT) is a promising solution incorporating learnable prompt tokens to customize pre-trained models for downstream tasks. However, VPT and its variants often encounter challenges like prompt initialization, prompt length, and subpar performance in self-supervised pretraining, hindering successful contextual adaptation. This study commences by exploring the correlation evolvement between prompts and patch tokens during proficient training. Inspired by the observation that the prompt tokens tend to share high mutual information with patch tokens, we propose initializing prompts with downstream token prototypes. The strategic initialization, a stand-in for the previous initialization, substantially improves performance in fine-tuning. To refine further, we optimize token construction with a streamlined pipeline that maintains excellent performance with almost no increase in computational expenses compared to VPT. Exhaustive experiments show our proposed approach outperforms existing methods by a remarkable margin. For instance, it surpasses full fine-tuning in 19 out of 24 tasks, using less than 0.4% of learnable parameters on the FGVC and VTAB-1K benchmarks. Notably, our method significantly advances the adaptation for self-supervised pretraining, achieving impressive task performance gains of at least 10% to 30%. Besides, the experimental results demonstrate the proposed SPT is robust to prompt lengths and scales well with model capacity and training data size. We finally provide an insightful exploration into the amount of target data facilitating the adaptation of pre-trained models to downstream tasks. The code is available at https://github.com/WangYZ1608/Self-Prompt-Tuning.
5/28/2024
🧪
Do We Really Need a Large Number of Visual Prompts?
Youngeun Kim, Yuhang Li, Abhishek Moitra, Ruokai Yin, Priyadarshini Panda
0
0
Due to increasing interest in adapting models on resource-constrained edges, parameter-efficient transfer learning has been widely explored. Among various methods, Visual Prompt Tuning (VPT), prepending learnable prompts to input space, shows competitive fine-tuning performance compared to training of full network parameters. However, VPT increases the number of input tokens, resulting in additional computational overhead. In this paper, we analyze the impact of the number of prompts on fine-tuning performance and self-attention operation in a vision transformer architecture. Through theoretical and empirical analysis we show that adding more prompts does not lead to linear performance improvement. Further, we propose a Prompt Condensation (PC) technique that aims to prevent performance degradation from using a small number of prompts. We validate our methods on FGVC and VTAB-1k tasks and show that our approach reduces the number of prompts by ~70% while maintaining accuracy.
5/14/2024

TAI++: Text as Image for Multi-Label Image Classification by Co-Learning Transferable Prompt
Xiangyu Wu, Qing-Yuan Jiang, Yang Yang, Yi-Feng Wu, Qing-Guo Chen, Jianfeng Lu
0
0
The recent introduction of prompt tuning based on pre-trained vision-language models has dramatically improved the performance of multi-label image classification. However, some existing strategies that have been explored still have drawbacks, i.e., either exploiting massive labeled visual data at a high cost or using text data only for text prompt tuning and thus failing to learn the diversity of visual knowledge. Hence, the application scenarios of these methods are limited. In this paper, we propose a pseudo-visual prompt~(PVP) module for implicit visual prompt tuning to address this problem. Specifically, we first learn the pseudo-visual prompt for each category, mining diverse visual knowledge by the well-aligned space of pre-trained vision-language models. Then, a co-learning strategy with a dual-adapter module is designed to transfer visual knowledge from pseudo-visual prompt to text prompt, enhancing their visual representation abilities. Experimental results on VOC2007, MS-COCO, and NUSWIDE datasets demonstrate that our method can surpass state-of-the-art~(SOTA) methods across various settings for multi-label image classification tasks. The code is available at https://github.com/njustkmg/PVP.
5/14/2024
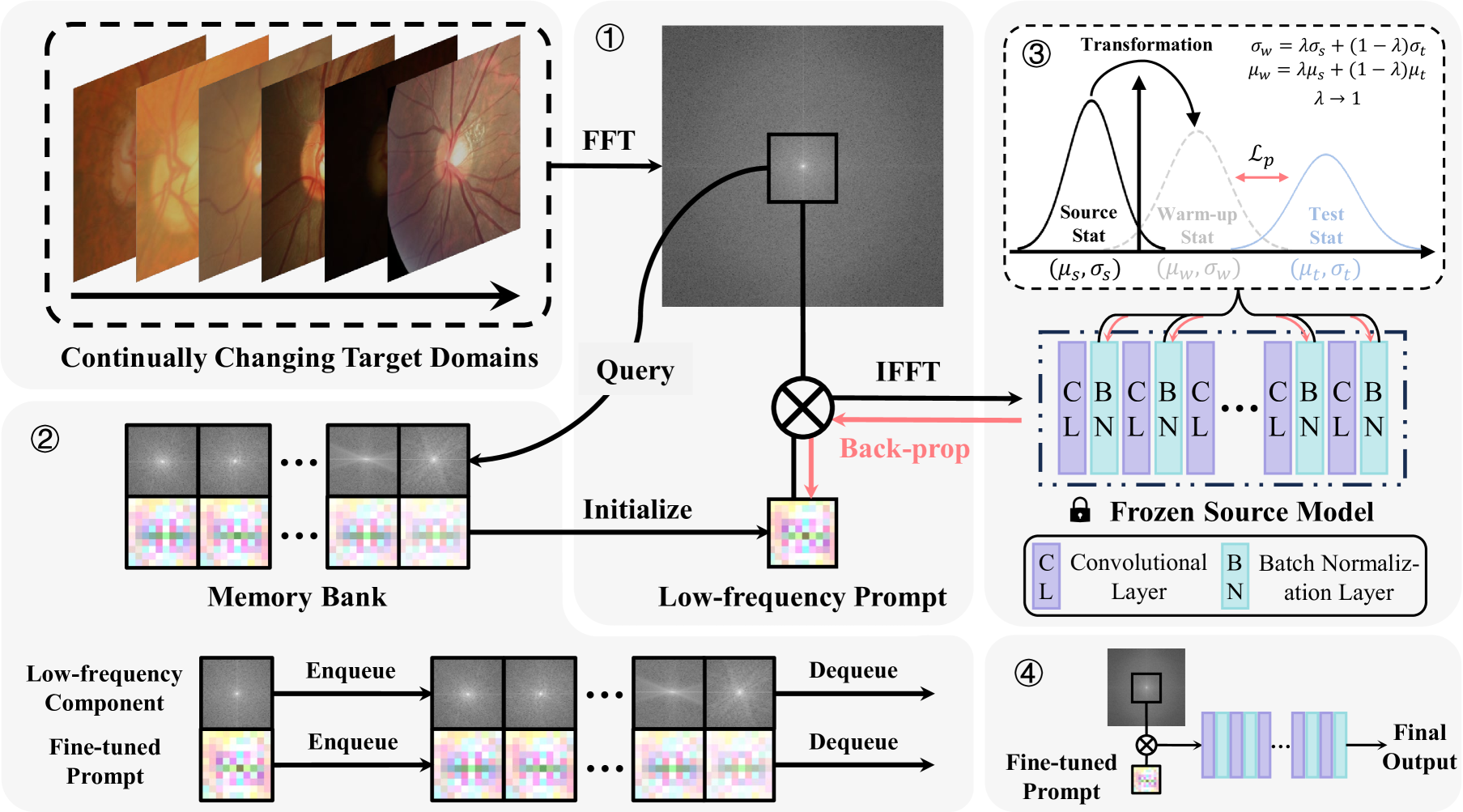
Each Test Image Deserves A Specific Prompt: Continual Test-Time Adaptation for 2D Medical Image Segmentation
Ziyang Chen, Yongsheng Pan, Yiwen Ye, Mengkang Lu, Yong Xia
0
0
Distribution shift widely exists in medical images acquired from different medical centres and poses a significant obstacle to deploying the pre-trained semantic segmentation model in real-world applications. Test-time adaptation has proven its effectiveness in tackling the cross-domain distribution shift during inference. However, most existing methods achieve adaptation by updating the pre-trained models, rendering them susceptible to error accumulation and catastrophic forgetting when encountering a series of distribution shifts (i.e., under the continual test-time adaptation setup). To overcome these challenges caused by updating the models, in this paper, we freeze the pre-trained model and propose the Visual Prompt-based Test-Time Adaptation (VPTTA) method to train a specific prompt for each test image to align the statistics in the batch normalization layers. Specifically, we present the low-frequency prompt, which is lightweight with only a few parameters and can be effectively trained in a single iteration. To enhance prompt initialization, we equip VPTTA with a memory bank to benefit the current prompt from previous ones. Additionally, we design a warm-up mechanism, which mixes source and target statistics to construct warm-up statistics, thereby facilitating the training process. Extensive experiments demonstrate the superiority of our VPTTA over other state-of-the-art methods on two medical image segmentation benchmark tasks. The code and weights of pre-trained source models are available at https://github.com/Chen-Ziyang/VPTTA.
5/28/2024