JADS: A Framework for Self-supervised Joint Aspect Discovery and Summarization

0

Sign in to get full access
Overview
- This paper presents a framework called JADS (Joint Aspect Discovery and Summarization) that aims to automatically discover aspects and generate summaries from product reviews in a self-supervised manner.
- The key innovation is the ability to jointly learn aspect extraction and review summarization, leveraging the interaction between these two tasks to improve performance on both.
- JADS is designed to work without any labeled data, making it more widely applicable than previous supervised approaches.
Plain English Explanation
The paper introduces a new framework called JADS (Joint Aspect Discovery and Summarization) that can automatically identify the key aspects or features discussed in product reviews and then generate summaries of those reviews. The novel aspect of JADS is that it learns to do both of these tasks simultaneously in a self-supervised way, without requiring any manually labeled training data.
Previous approaches have tackled aspect extraction and review summarization as separate problems, but the JADS framework recognizes that these two tasks are actually closely related. By learning them jointly, the model is able to leverage the connection between aspects and summaries to improve its performance on both. For example, knowing the important aspects discussed in a review can help the summarization component focus on the most relevant information.
Since JADS doesn't need any labeled training data, it's more widely applicable than prior supervised methods that rely on having a large corpus of pre-annotated reviews. This makes it a more practical solution for real-world product review analysis, where obtaining high-quality labeled data can be challenging and expensive.
Technical Explanation
The core of the JADS framework is a neural network model that is trained in a self-supervised manner to jointly discover product aspects and generate relevant review summaries. The model takes in a product review text as input and learns to:
- Identify the key aspects or features discussed in the review (e.g. "battery life", "camera quality", "customer service") [link to 'Amplifying Aspect Sentence Awareness: A Novel Approach to Aspect-Level Sentiment Analysis']
- Produce a concise summary that captures the most salient information about those aspects [link to 'Label-free Topic-Focused Summarization Using Query']
The self-supervised training process involves having the model reconstruct the original review text from its predicted aspects and summary, incentivizing it to learn representations that capture the important content. No manually labeled data is required.
The authors demonstrate that this joint learning approach outperforms previous unsupervised and weakly-supervised methods for both aspect extraction and review summarization on benchmark datasets. They also show that the aspects discovered by JADS can be effectively used to guide the summarization process, leading to more informative and coherent summaries [link to 'Unsupervised Extractive Dialogue Summarization in Hyperdimensional Space', link to 'Product Description QA-Assisted Self-Supervised Opinion'].
Critical Analysis
The JADS framework represents an innovative and promising approach to tackle the challenging problems of aspect extraction and review summarization in a unified, self-supervised manner. The authors provide strong empirical results demonstrating the effectiveness of their approach compared to prior work.
One potential limitation is that the self-supervised training process may not capture all the nuances and complexities of human-written review summaries. The generated summaries, while informative, may lack the fluency and conciseness of summaries written by people. Further research could explore ways to better model human summarization behavior.
Additionally, the paper does not provide much insight into the types of aspects that JADS is able to discover, or how the quality of the extracted aspects impacts the summarization performance. A deeper analysis of the discovered aspects and their suitability for summarization would strengthen the overall contribution.
Overall, the JADS framework is a compelling step forward in automating key tasks for product review analysis. The self-supervised joint learning approach is an interesting direction that could inspire further innovations in this space.
Conclusion
The JADS framework introduces a novel self-supervised approach to jointly discover product aspects and generate relevant summaries from user reviews. By learning these two closely related tasks together, JADS is able to outperform prior unsupervised and weakly-supervised methods on both aspect extraction and review summarization.
The ability to perform these analyses without any labeled training data makes JADS a practical and widely applicable solution for real-world product review analytics. While there are some limitations to the quality of the generated summaries, the framework represents an important advancement in automating key information extraction and summarization tasks.
Overall, the JADS paper contributes a compelling new direction for tackling product review analysis, with potential implications for a range of applications that rely on extracting insights from large volumes of unstructured user-generated content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
JADS: A Framework for Self-supervised Joint Aspect Discovery and Summarization
Xiaobo Guo, Jay Desai, Srinivasan H. Sengamedu
To generate summaries that include multiple aspects or topics for text documents, most approaches use clustering or topic modeling to group relevant sentences and then generate a summary for each group. These approaches struggle to optimize the summarization and clustering algorithms jointly. On the other hand, aspect-based summarization requires known aspects. Our solution integrates topic discovery and summarization into a single step. Given text data, our Joint Aspect Discovery and Summarization algorithm (JADS) discovers aspects from the input and generates a summary of the topics, in one step. We propose a self-supervised framework that creates a labeled dataset by first mixing sentences from multiple documents (e.g., CNN/DailyMail articles) as the input and then uses the article summaries from the mixture as the labels. The JADS model outperforms the two-step baselines. With pretraining, the model achieves better performance and stability. Furthermore, embeddings derived from JADS exhibit superior clustering capabilities. Our proposed method achieves higher semantic alignment with ground truth and is factual.
Read more5/30/2024

0
MODABS: Multi-Objective Learning for Dynamic Aspect-Based Summarization
Xiaobo Guo, Soroush Vosoughi
The rapid proliferation of online content necessitates effective summarization methods, among which dynamic aspect-based summarization stands out. Unlike its traditional counterpart, which assumes a fixed set of known aspects, this approach adapts to the varied aspects of the input text. We introduce a novel multi-objective learning framework employing a Longformer-Encoder-Decoder for this task. The framework optimizes aspect number prediction, minimizes disparity between generated and reference summaries for each aspect, and maximizes dissimilarity across aspect-specific summaries. Extensive experiments show our method significantly outperforms baselines on three diverse datasets, largely due to the effective alignment of generated and reference aspect counts without sacrificing single-aspect summarization quality.
Read more6/19/2024

0
AspirinSum: an Aspect-based utility-preserved de-identification Summarization framework
Ya-Lun Li
Due to the rapid advancement of Large Language Model (LLM), the whole community eagerly consumes any available text data in order to train the LLM. Currently, large portion of the available text data are collected from internet, which has been thought as a cheap source of the training data. However, when people try to extend the LLM's capability to the personal related domain, such as healthcare or education, the lack of public dataset in these domains make the adaption of the LLM in such domains much slower. The reason of lacking public available dataset in such domains is because they usually contain personal sensitive information. In order to comply with privacy law, the data in such domains need to be de-identified before any kind of dissemination. It had been much research tried to address this problem for the image or tabular data. However, there was limited research on the efficient and general de-identification method for text data. Most of the method based on human annotation or predefined category list. It usually can not be easily adapted to specific domains. The goal of this proposal is to develop a text de-identification framework, which can be easily adapted to the specific domain, leverage the existing expert knowledge without further human annotation. We propose an aspect-based utility-preserved de-identification summarization framework, AspirinSum, by learning to align expert's aspect from existing comment data, it can efficiently summarize the personal sensitive document by extracting personal sensitive aspect related sub-sentence and de-identify it by substituting it with similar aspect sub-sentence. We envision that the de-identified text can then be used in data publishing, eventually publishing our de-identified dataset for downstream task use.
Read more6/21/2024
0
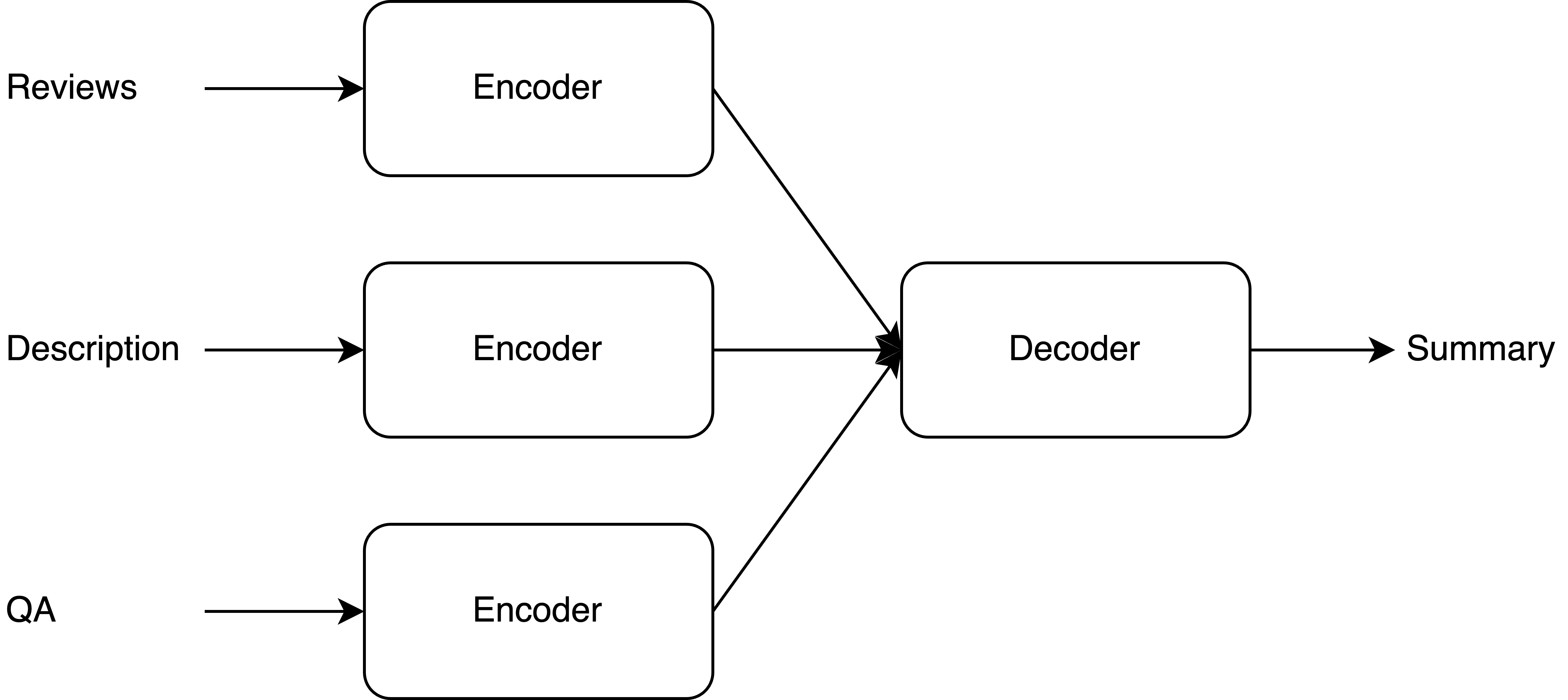
Product Description and QA Assisted Self-Supervised Opinion Summarization
Tejpalsingh Siledar, Rupasai Rangaraju, Sankara Sri Raghava Ravindra Muddu, Suman Banerjee, Amey Patil, Sudhanshu Shekhar Singh, Muthusamy Chelliah, Nikesh Garera, Swaprava Nath, Pushpak Bhattacharyya
In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
Read more4/9/2024