Product Description and QA Assisted Self-Supervised Opinion Summarization
2404.05243
0
0
Abstract
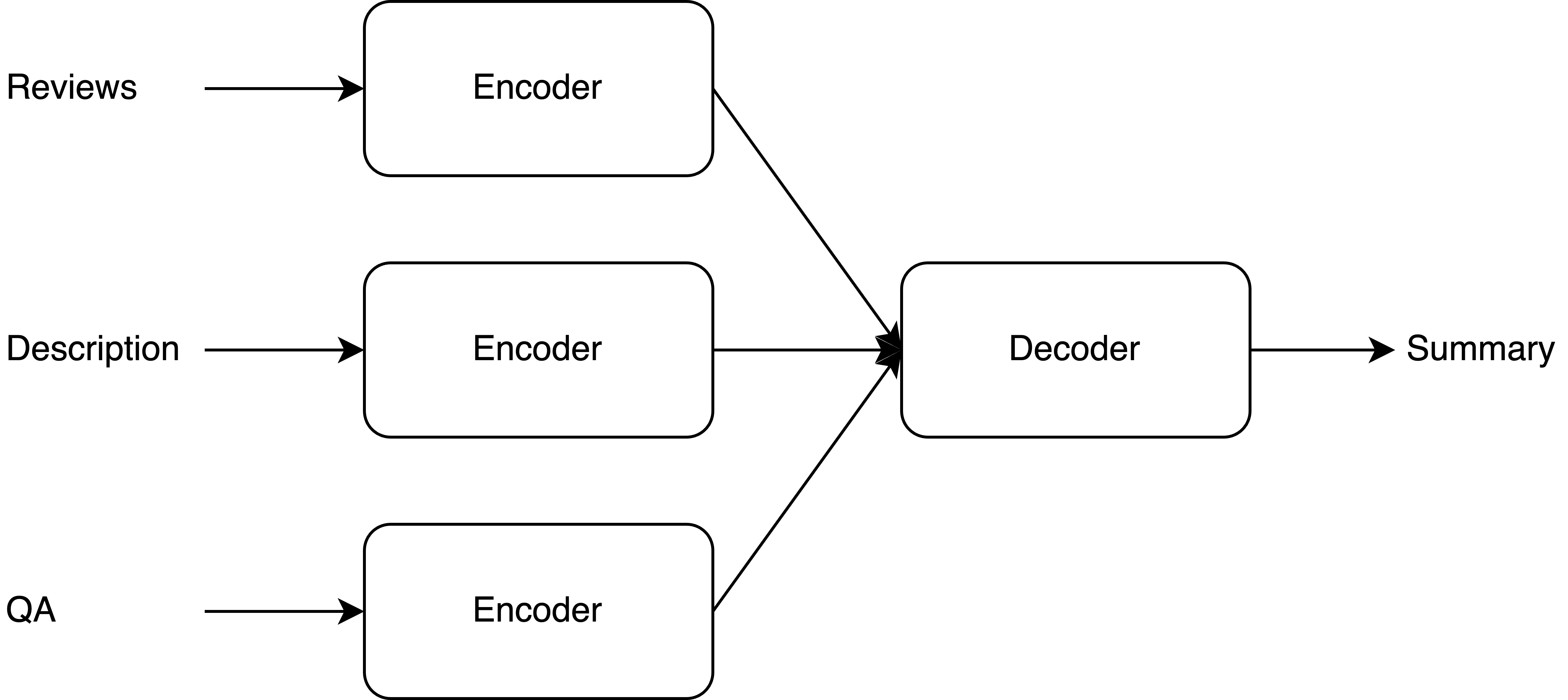
In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores a self-supervised approach to summarize opinions expressed in product reviews
- Leverages the product description and question-answering (QA) to guide the summarization process
- Aims to generate concise and informative opinion summaries without human-labeled data
Plain English Explanation
This research paper proposes a novel approach to summarize opinions expressed in product reviews. Rather than relying on manually labeled data, the method uses the product description and a question-answering system to automatically guide the summarization process.
The key idea is to leverage the inherent structure and information within the product description and user questions to better understand the important aspects and sentiments expressed in the reviews. By using this self-supervised approach, the researchers aim to generate concise and informative opinion summaries without the need for extensive human labeling.
This could be particularly useful for e-commerce platforms, where quickly distilling the key opinions from a large volume of reviews is crucial for helping customers make informed purchasing decisions. The automated comparison of product features and opinions can also benefit both customers and sellers.
Technical Explanation
The proposed approach, called Product Description and QA Assisted Self-Supervised Opinion Summarization (PQAS), consists of several key components:
-
Product Description Encoder: This module encodes the product description into a semantic representation that can capture the important aspects and attributes of the product.
-
Question-Answering (QA) System: A QA model is used to answer questions about the product based on the review text. This helps identify the most salient information that users are interested in.
-
Opinion Summarization Model: This is the core component that generates the final opinion summary. It takes the product description encoding and the QA outputs as input, and learns to produce a concise summary of the key opinions expressed in the reviews.
The training of the opinion summarization model is done in a self-supervised manner, without the need for manually labeled review summaries. The product description and QA system provide the necessary guidance and supervision for the model to learn to extract and summarize the important opinions.
The researchers evaluate their approach on several real-world product review datasets and show that it outperforms baseline summarization methods in terms of both automatic metrics and human evaluation.
Critical Analysis
The self-supervised approach proposed in this paper is an interesting and practical solution to the challenge of opinion summarization, which typically requires extensive human labeling. By leveraging the product description and QA system, the method can learn to generate summaries without relying on manual annotations.
However, the paper does not discuss the potential limitations of this approach. For example, the quality of the summaries may depend heavily on the accuracy and coverage of the QA system, which could be a bottleneck. Additionally, the method may struggle to capture nuanced or context-specific opinions that are not directly addressed by the product description or user questions.
Further research could explore ways to make the summarization model more robust to these potential issues, such as incorporating additional signals or using more advanced language understanding techniques. Evaluating the approach on a wider range of product categories and review data could also provide valuable insights into its generalizability.
Conclusion
This research presents an innovative self-supervised approach to opinion summarization that leverages product descriptions and question-answering to guide the summarization process. By avoiding the need for manual labeling, the method has the potential to scale and be applied to a wide range of e-commerce scenarios, helping customers make more informed purchasing decisions and enabling efficient comparison of product features and opinions.
While the initial results are promising, further research is needed to address potential limitations and ensure the robustness of the approach across diverse product domains. Nonetheless, this work represents an important step forward in the field of opinion summarization and could have significant implications for e-commerce and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!Unsupervised Extractive Dialogue Summarization in Hyperdimensional Space
Seongmin Park, Kyungho Kim, Jaejin Seo, Jihwa Lee
0
0
We present HyperSum, an extractive summarization framework that captures both the efficiency of traditional lexical summarization and the accuracy of contemporary neural approaches. HyperSum exploits the pseudo-orthogonality that emerges when randomly initializing vectors at extremely high dimensions (blessing of dimensionality) to construct representative and efficient sentence embeddings. Simply clustering the obtained embeddings and extracting their medoids yields competitive summaries. HyperSum often outperforms state-of-the-art summarizers -- in terms of both summary accuracy and faithfulness -- while being 10 to 100 times faster. We open-source HyperSum as a strong baseline for unsupervised extractive summarization.
5/17/2024
👀
Incremental Extractive Opinion Summarization Using Cover Trees
Somnath Basu Roy Chowdhury, Nicholas Monath, Avinava Dubey, Manzil Zaheer, Andrew McCallum, Amr Ahmed, Snigdha Chaturvedi
0
0
Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accumulate over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank (Radev et al., 2004; Chowdhury et al., 2022). CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 36x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.
4/15/2024
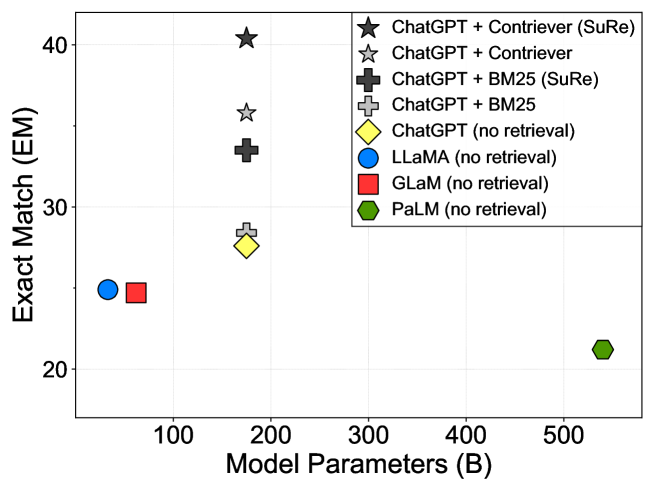
SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Jaehyung Kim, Jaehyun Nam, Sangwoo Mo, Jongjin Park, Sang-Woo Lee, Minjoon Seo, Jung-Woo Ha, Jinwoo Shin
0
0
Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
4/23/2024
🤿
Enhancing Video Summarization with Context Awareness
Hai-Dang Huynh-Lam, Ngoc-Phuong Ho-Thi, Minh-Triet Tran, Trung-Nghia Le
0
0
Video summarization is a crucial research area that aims to efficiently browse and retrieve relevant information from the vast amount of video content available today. With the exponential growth of multimedia data, the ability to extract meaningful representations from videos has become essential. Video summarization techniques automatically generate concise summaries by selecting keyframes, shots, or segments that capture the video's essence. This process improves the efficiency and accuracy of various applications, including video surveillance, education, entertainment, and social media. Despite the importance of video summarization, there is a lack of diverse and representative datasets, hindering comprehensive evaluation and benchmarking of algorithms. Existing evaluation metrics also fail to fully capture the complexities of video summarization, limiting accurate algorithm assessment and hindering the field's progress. To overcome data scarcity challenges and improve evaluation, we propose an unsupervised approach that leverages video data structure and information for generating informative summaries. By moving away from fixed annotations, our framework can produce representative summaries effectively. Moreover, we introduce an innovative evaluation pipeline tailored specifically for video summarization. Human participants are involved in the evaluation, comparing our generated summaries to ground truth summaries and assessing their informativeness. This human-centric approach provides valuable insights into the effectiveness of our proposed techniques. Experimental results demonstrate that our training-free framework outperforms existing unsupervised approaches and achieves competitive results compared to state-of-the-art supervised methods.
4/9/2024