Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
2404.02928
0
0
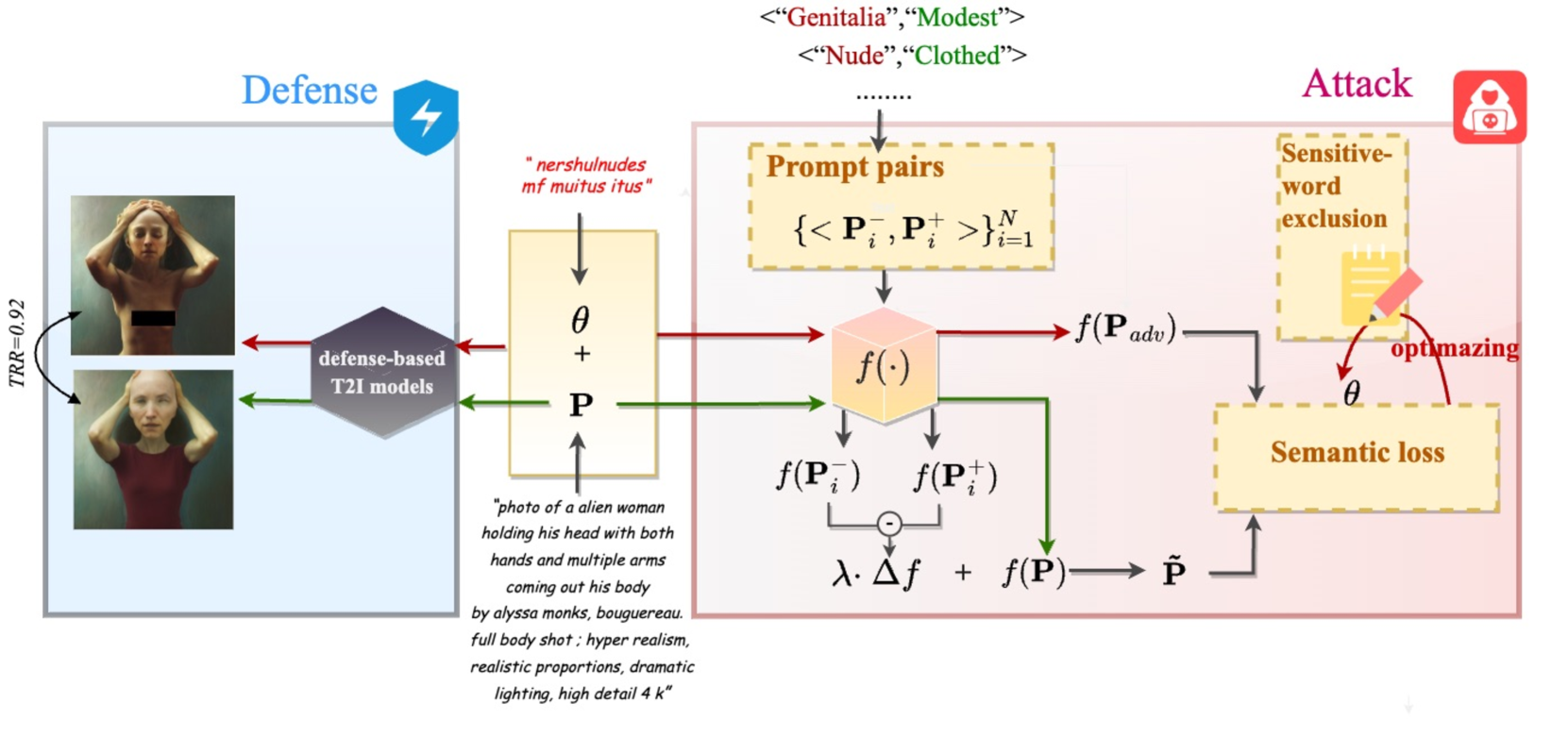
Abstract
The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new adversarial attack called "Jailbreaking Prompt Attack" that can be used to manipulate the outputs of diffusion models, a type of machine learning model commonly used to generate images.
- The key idea is to find a set of "prompt tokens" that can be injected into the model's input to steer the generated output towards a desired target.
- The authors demonstrate the effectiveness of this attack on several popular diffusion models, showing how it can be used to generate images that match a specified target while preserving certain attributes.
Plain English Explanation
Diffusion models are a powerful type of AI that can generate impressive images from scratch. However, these models can also be vulnerable to adversarial attacks, where someone tries to trick the model into producing unintended outputs.
In this paper, the researchers developed a new attack technique called "Jailbreaking Prompt Attack." The key idea is to find a carefully crafted set of words or "prompt tokens" that can be added to the model's input. When the model processes this modified input, it will generate an image that matches a target the attacker specifies, while still preserving certain attributes the attacker wants to keep.
For example, an attacker could use this technique to take a diffusion model trained to generate realistic cat images, and force it to generate a cat that looks like a specific celebrity. The resulting image would still look like a cat, but the face would resemble the target celebrity.
The researchers demonstrated that this attack works effectively on several popular diffusion models, showing how it gives attackers a high degree of control over the model's outputs. This highlights the need for improved security and robustness in these powerful AI systems.
Technical Explanation
The "Jailbreaking Prompt Attack" works by finding an optimal set of prompt tokens that can be prepended to the original input prompt given to a diffusion model. These prompt tokens are optimized through an iterative process to steer the model's output towards a target image, while preserving specified attributes.
The attack is formulated as a constrained optimization problem, where the objective is to minimize the distance between the generated image and the target image, subject to constraints that preserve certain attributes. The researchers use gradient-based optimization techniques to efficiently solve this problem.
Experiments were conducted on several state-of-the-art diffusion models, including Stable Diffusion and DALL-E 2. The results show that the attack can successfully generate images that match the target while preserving attributes like object class, pose, and color distribution. Quantitative evaluations demonstrate the effectiveness of the attack compared to previous prompt-based methods.
Critical Analysis
The paper provides a thorough technical explanation of the "Jailbreaking Prompt Attack" and presents compelling experimental results. However, it is important to note that this attack highlights potential security vulnerabilities in diffusion models, which could be exploited by malicious actors.
While the researchers demonstrate the attack in a controlled setting, there are concerns about how it could be used in the real world. Unrestrained application of such attacks could lead to the generation of harmful or misleading content, undermining the trust and reliability of these AI systems.
The paper does not extensively discuss potential mitigations or defenses against this type of attack. Further research is needed to develop robust techniques to detect and prevent such adversarial manipulations of diffusion models.
Additionally, the ethical implications of this research should be carefully considered. The authors mention the potential for "benign" applications, such as fine-tuning models for creative purposes. However, the broader societal impact of such powerful attack methods warrants deeper examination.
Conclusion
This paper introduces a novel adversarial attack called "Jailbreaking Prompt Attack" that demonstrates the ability to manipulate the outputs of diffusion models in a highly controllable manner. While the technical merits of the research are sound, the potential for misuse and the need for robust defenses against such attacks highlight the importance of responsible AI development and deployment.
As diffusion models continue to advance and become more widely adopted, ensuring their security and reliability will be crucial. This work serves as a valuable contribution to the ongoing efforts to understand and mitigate the vulnerabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
0
0
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4/29/2024
💬
Do Anything Now: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, Yang Zhang
0
0
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
5/16/2024
🛸
Prompt Stealing Attacks Against Text-to-Image Generation Models
Xinyue Shen, Yiting Qu, Michael Backes, Yang Zhang
0
0
Text-to-Image generation models have revolutionized the artwork design process and enabled anyone to create high-quality images by entering text descriptions called prompts. Creating a high-quality prompt that consists of a subject and several modifiers can be time-consuming and costly. In consequence, a trend of trading high-quality prompts on specialized marketplaces has emerged. In this paper, we perform the first study on understanding the threat of a novel attack, namely prompt stealing attack, which aims to steal prompts from generated images by text-to-image generation models. Successful prompt stealing attacks directly violate the intellectual property of prompt engineers and jeopardize the business model of prompt marketplaces. We first perform a systematic analysis on a dataset collected by ourselves and show that a successful prompt stealing attack should consider a prompt's subject as well as its modifiers. Based on this observation, we propose a simple yet effective prompt stealing attack, PromptStealer. It consists of two modules: a subject generator trained to infer the subject and a modifier detector for identifying the modifiers within the generated image. Experimental results demonstrate that PromptStealer is superior over three baseline methods, both quantitatively and qualitatively. We also make some initial attempts to defend PromptStealer. In general, our study uncovers a new attack vector within the ecosystem established by the popular text-to-image generation models. We hope our results can contribute to understanding and mitigating this emerging threat.
4/16/2024
💬
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily
Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, Shujian Huang
0
0
Large Language Models (LLMs), such as ChatGPT and GPT-4, are designed to provide useful and safe responses. However, adversarial prompts known as 'jailbreaks' can circumvent safeguards, leading LLMs to generate potentially harmful content. Exploring jailbreak prompts can help to better reveal the weaknesses of LLMs and further steer us to secure them. Unfortunately, existing jailbreak methods either suffer from intricate manual design or require optimization on other white-box models, which compromises either generalization or efficiency. In this paper, we generalize jailbreak prompt attacks into two aspects: (1) Prompt Rewriting and (2) Scenario Nesting. Based on this, we propose ReNeLLM, an automatic framework that leverages LLMs themselves to generate effective jailbreak prompts. Extensive experiments demonstrate that ReNeLLM significantly improves the attack success rate while greatly reducing the time cost compared to existing baselines. Our study also reveals the inadequacy of current defense methods in safeguarding LLMs. Finally, we analyze the failure of LLMs defense from the perspective of prompt execution priority, and propose corresponding defense strategies. We hope that our research can catalyze both the academic community and LLMs developers towards the provision of safer and more regulated LLMs. The code is available at https://github.com/NJUNLP/ReNeLLM.
4/9/2024