AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
2404.16873
0
2
🤔
Abstract
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large Language Models (LLMs) have achieved remarkable successes, but are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content.
- Manual red-teaming to find adversarial prompts is inefficient and time-consuming.
- Automatic adversarial prompt generation often leads to semantically meaningless attacks that can be easily detected.
- This paper presents a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, ~800 times faster than existing optimization-based approaches.
Plain English Explanation
Large language models (LLMs) are AI systems that can understand and generate human-like text. These models have shown impressive capabilities, but they can also be tricked into producing harmful or inappropriate content. Researchers have found that by adding certain phrases or "prompts" to the input, they can cause the LLM to generate undesirable output, a process known as "jailbreaking."
Finding these adversarial prompts manually is a tedious and inefficient process. Automated methods for generating adversarial prompts have been developed, but they often produce prompts that don't make sense and can be easily detected by the LLM's safety systems.
This paper introduces a new approach that uses a separate LLM, called the AdvPrompter, to quickly generate human-readable adversarial prompts. The AdvPrompter is trained using a novel algorithm that doesn't require access to the target LLM's internal workings. It can generate prompts that trick the target LLM into producing harmful output, without changing the meaning of the original input.
The researchers show that this approach outperforms existing optimization-based methods, generating adversarial prompts about 800 times faster. They also demonstrate that by training LLMs on datasets of synthetic prompts generated by the AdvPrompter, the models can become more robust to jailbreaking attacks while maintaining their performance on other tasks.
Technical Explanation
This paper presents a novel method for generating human-readable adversarial prompts to "jailbreak" Large Language Models (LLMs), causing them to produce inappropriate or harmful output. The researchers train a separate LLM, called the AdvPrompter, to generate these adversarial prompts quickly and efficiently.
The AdvPrompter is trained using a two-step process: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter's predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. This approach does not require access to the gradients of the target LLM, making it more broadly applicable.
The trained AdvPrompter can generate suffixes that veil the input instruction without changing its meaning, luring the target LLM to give a harmful response. Experimental results on popular open-source LLMs and closed-source black-box APIs show that this method outperforms state-of-the-art approaches on the AdvBench dataset.
Furthermore, the researchers demonstrate that by fine-tuning LLMs on a synthetic dataset generated by the AdvPrompter, the models can become more robust to jailbreaking attacks while maintaining high performance on tasks like the MMLU benchmark.
Critical Analysis
The paper presents a promising approach for quickly generating human-readable adversarial prompts to "jailbreak" LLMs. However, the researchers acknowledge that their method may still be vulnerable to more advanced adversarial techniques, such as those presented in the DollarTextItLinkPromptDollar and Jailbreaking Prompt Attack papers.
Additionally, while the AdvPrompter is claimed to be faster than existing optimization-based approaches, the paper does not provide a comprehensive comparison of the computational resources required for each method. The scalability and practical deployment of this approach in real-world settings may need further investigation.
The researchers also note that their method for fine-tuning LLMs to be more robust against jailbreaking attacks may have unintended consequences, such as reducing the models' overall performance or introducing new vulnerabilities. Careful evaluation and ongoing monitoring would be necessary to ensure the safety and reliability of these "hardened" LLMs.
Conclusion
This paper presents a novel approach for generating human-readable adversarial prompts to "jailbreak" Large Language Models (LLMs), causing them to produce inappropriate or harmful output. The key innovation is the use of a separate LLM, called the AdvPrompter, which can generate these adversarial prompts much faster than existing optimization-based methods.
The researchers also demonstrate a technique for fine-tuning LLMs to be more robust against jailbreaking attacks, while maintaining their performance on other tasks. However, the potential limitations and unintended consequences of this approach require further investigation and ongoing vigilance.
Overall, this work highlights the importance of developing robust and secure AI systems, as these models continue to gain increasing influence and capability. The rapid progress in this area also underscores the need for continued research and collaboration to ensure the responsible development and deployment of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily
Peng Ding, Jun Kuang, Dan Ma, Xuezhi Cao, Yunsen Xian, Jiajun Chen, Shujian Huang
0
0
Large Language Models (LLMs), such as ChatGPT and GPT-4, are designed to provide useful and safe responses. However, adversarial prompts known as 'jailbreaks' can circumvent safeguards, leading LLMs to generate potentially harmful content. Exploring jailbreak prompts can help to better reveal the weaknesses of LLMs and further steer us to secure them. Unfortunately, existing jailbreak methods either suffer from intricate manual design or require optimization on other white-box models, which compromises either generalization or efficiency. In this paper, we generalize jailbreak prompt attacks into two aspects: (1) Prompt Rewriting and (2) Scenario Nesting. Based on this, we propose ReNeLLM, an automatic framework that leverages LLMs themselves to generate effective jailbreak prompts. Extensive experiments demonstrate that ReNeLLM significantly improves the attack success rate while greatly reducing the time cost compared to existing baselines. Our study also reveals the inadequacy of current defense methods in safeguarding LLMs. Finally, we analyze the failure of LLMs defense from the perspective of prompt execution priority, and propose corresponding defense strategies. We hope that our research can catalyze both the academic community and LLMs developers towards the provision of safer and more regulated LLMs. The code is available at https://github.com/NJUNLP/ReNeLLM.
4/9/2024
💬
Do Anything Now: Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, Yang Zhang
0
0
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
5/16/2024

$textit{LinkPrompt}$: Natural and Universal Adversarial Attacks on Prompt-based Language Models
Yue Xu, Wenjie Wang
0
0
Prompt-based learning is a new language model training paradigm that adapts the Pre-trained Language Models (PLMs) to downstream tasks, which revitalizes the performance benchmarks across various natural language processing (NLP) tasks. Instead of using a fixed prompt template to fine-tune the model, some research demonstrates the effectiveness of searching for the prompt via optimization. Such prompt optimization process of prompt-based learning on PLMs also gives insight into generating adversarial prompts to mislead the model, raising concerns about the adversarial vulnerability of this paradigm. Recent studies have shown that universal adversarial triggers (UATs) can be generated to alter not only the predictions of the target PLMs but also the prediction of corresponding Prompt-based Fine-tuning Models (PFMs) under the prompt-based learning paradigm. However, UATs found in previous works are often unreadable tokens or characters and can be easily distinguished from natural texts with adaptive defenses. In this work, we consider the naturalness of the UATs and develop $textit{LinkPrompt}$, an adversarial attack algorithm to generate UATs by a gradient-based beam search algorithm that not only effectively attacks the target PLMs and PFMs but also maintains the naturalness among the trigger tokens. Extensive results demonstrate the effectiveness of $textit{LinkPrompt}$, as well as the transferability of UATs generated by $textit{LinkPrompt}$ to open-sourced Large Language Model (LLM) Llama2 and API-accessed LLM GPT-3.5-turbo. The resource is available at $href{https://github.com/SavannahXu79/LinkPrompt}{https://github.com/SavannahXu79/LinkPrompt}$.
4/10/2024
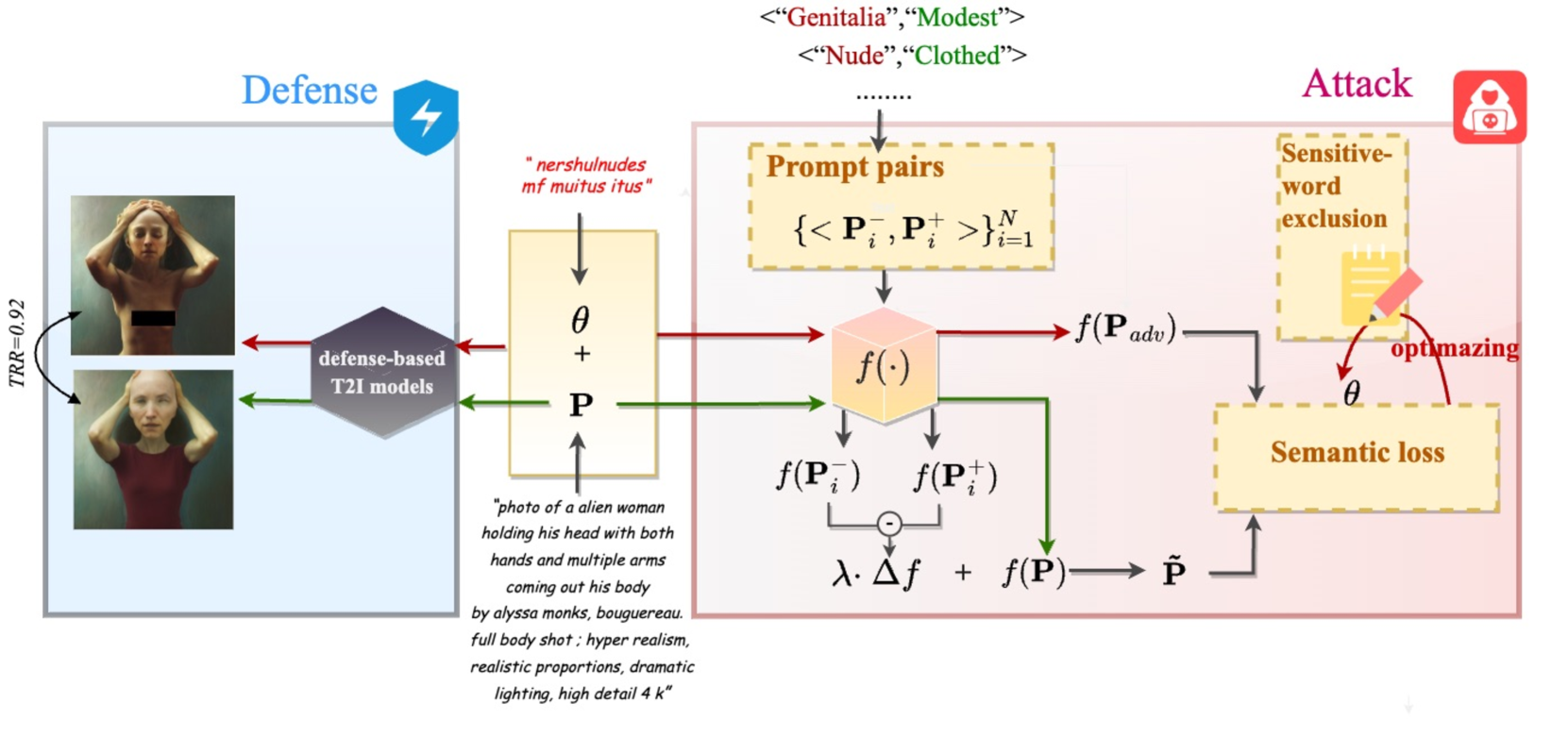
Jailbreaking Prompt Attack: A Controllable Adversarial Attack against Diffusion Models
Jiachen Ma, Anda Cao, Zhiqing Xiao, Jie Zhang, Chao Ye, Junbo Zhao
0
0
The fast advance of the image generation community has attracted attention worldwide. The safety issue needs to be further scrutinized and studied. There have been a few works around this area mostly achieving a post-processing design, model-specific, or yielding suboptimal image quality generation. Despite that, in this article, we discover a black-box attack method that enjoys three merits. It enables (i)-attacks both directed and semantic-driven that theoretically and practically pose a hazard to this vast user community, (ii)-surprisingly surpasses the white-box attack in a black-box manner and (iii)-without requiring any post-processing effort. Core to our approach is inspired by the concept guidance intriguing property of Classifier-Free guidance (CFG) in T2I models, and we discover that conducting frustratingly simple guidance in the CLIP embedding space, coupled with the semantic loss and an additionally sensitive word list works very well. Moreover, our results expose and highlight the vulnerabilities in existing defense mechanisms.
4/5/2024