JEAN: Joint Expression and Audio-guided NeRF-based Talking Face Generation

0

Sign in to get full access
Overview
- The paper proposes a novel method called JEAN (Joint Expression and Audio-guided NeRF-based Talking Face Generation) for generating realistic 3D talking faces from audio input.
- JEAN jointly models facial expressions and audio-driven head motion, enabling high-fidelity video synthesis of a talking face.
- The method leverages a NeRF-based representation to model the 3D facial geometry, while also incorporating an audio-driven animation component.
Plain English Explanation
JEAN is a system that can create realistic 3D videos of a person's face moving and talking, just from an audio recording. It works by combining two key technologies:
-
A NeRF model that can accurately represent the 3D shape and appearance of the person's face. NeRF is a machine learning technique that can create high-quality 3D models from 2D images.
-
An audio-driven animation component that analyzes the audio and uses it to control the movement and expression of the 3D face model. This allows the face to naturally sync up with the speech.
By jointly modeling both the facial geometry and the audio-driven animation, JEAN can generate very convincing talking face videos that look and move realistically. This could be useful for applications like virtual assistants, video dubbing, or CGI characters.
Technical Explanation
The core of JEAN is a NeRF-based 3D face model that represents the geometry and appearance of the person's face. This NeRF model is conditioned on a set of control parameters that govern the facial expressions and head pose.
To animate the face, JEAN uses an audio-driven animation module that takes the input audio and predicts these control parameters over time. This allows the 3D face model to move and deform in sync with the speech.
The key innovation is the joint training of the NeRF face model and the audio-driven animation module. This enables the system to learn the complex relationship between audio, facial expressions, and 3D face shape in an integrated manner.
Experiments show that JEAN can generate high-fidelity talking face videos that outperform prior methods in terms of visual quality and audio-visual synchronization. The system is also able to generalize to new speakers and can be fine-tuned to specific individuals.
Critical Analysis
The paper presents a compelling approach to the challenging problem of generating realistic 3D talking faces from audio input. The key strengths are the integration of NeRF-based 3D face modeling with audio-driven animation, as well as the joint training strategy that allows the system to learn the complex relationships between audio, expressions, and 3D geometry.
However, the paper does not address some potential limitations and areas for further research:
- The system was only evaluated on a limited dataset of frontal-facing talking heads. It's unclear how well it would generalize to more diverse head poses, facial features, or speaking styles.
- The paper does not provide details on the computational complexity and real-time performance of the system, which would be important for many practical applications.
- While the results are impressive, there may still be room for improvement in terms of generating even more realistic and natural-looking talking face videos.
Overall, JEAN represents an important step forward in audio-driven 3D talking face generation, but further research and development will be needed to fully realize the potential of this technology.
Conclusion
The JEAN system proposed in this paper demonstrates how the integration of NeRF-based 3D face modeling and audio-driven animation can enable the generation of high-quality, realistic talking face videos. By jointly learning the relationship between audio, facial expressions, and 3D face geometry, JEAN is able to produce talking face renderings that are significantly more natural and synchronous compared to prior methods.
While the current system has some limitations, the core ideas behind JEAN open up exciting possibilities for advanced virtual avatars, CGI characters, and other applications that require believable audio-visual synthesis. As the underlying technologies continue to improve, we can expect to see even more realistic and versatile talking face generation systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
JEAN: Joint Expression and Audio-guided NeRF-based Talking Face Generation
Sai Tanmay Reddy Chakkera, Aggelina Chatziagapi, Dimitris Samaras
We introduce a novel method for joint expression and audio-guided talking face generation. Recent approaches either struggle to preserve the speaker identity or fail to produce faithful facial expressions. To address these challenges, we propose a NeRF-based network. Since we train our network on monocular videos without any ground truth, it is essential to learn disentangled representations for audio and expression. We first learn audio features in a self-supervised manner, given utterances from multiple subjects. By incorporating a contrastive learning technique, we ensure that the learned audio features are aligned to the lip motion and disentangled from the muscle motion of the rest of the face. We then devise a transformer-based architecture that learns expression features, capturing long-range facial expressions and disentangling them from the speech-specific mouth movements. Through quantitative and qualitative evaluation, we demonstrate that our method can synthesize high-fidelity talking face videos, achieving state-of-the-art facial expression transfer along with lip synchronization to unseen audio.
Read more9/19/2024
🌐
0
Embedded Representation Learning Network for Animating Styled Video Portrait
Tianyong Wang, Xiangyu Liang, Wangguandong Zheng, Dan Niu, Haifeng Xia, Siyu Xia
The talking head generation recently attracted considerable attention due to its widespread application prospects, especially for digital avatars and 3D animation design. Inspired by this practical demand, several works explored Neural Radiance Fields (NeRF) to synthesize the talking heads. However, these methods based on NeRF face two challenges: (1) Difficulty in generating style-controllable talking heads. (2) Displacement artifacts around the neck in rendered images. To overcome these two challenges, we propose a novel generative paradigm textit{Embedded Representation Learning Network} (ERLNet) with two learning stages. First, the textit{ audio-driven FLAME} (ADF) module is constructed to produce facial expression and head pose sequences synchronized with content audio and style video. Second, given the sequence deduced by the ADF, one novel textit{dual-branch fusion NeRF} (DBF-NeRF) explores these contents to render the final images. Extensive empirical studies demonstrate that the collaboration of these two stages effectively facilitates our method to render a more realistic talking head than the existing algorithms.
Read more5/1/2024

0
RealTalk: Real-time and Realistic Audio-driven Face Generation with 3D Facial Prior-guided Identity Alignment Network
Xiaozhong Ji, Chuming Lin, Zhonggan Ding, Ying Tai, Jian Yang, Junwei Zhu, Xiaobin Hu, Jiangning Zhang, Donghao Luo, Chengjie Wang
Person-generic audio-driven face generation is a challenging task in computer vision. Previous methods have achieved remarkable progress in audio-visual synchronization, but there is still a significant gap between current results and practical applications. The challenges are two-fold: 1) Preserving unique individual traits for achieving high-precision lip synchronization. 2) Generating high-quality facial renderings in real-time performance. In this paper, we propose a novel generalized audio-driven framework RealTalk, which consists of an audio-to-expression transformer and a high-fidelity expression-to-face renderer. In the first component, we consider both identity and intra-personal variation features related to speaking lip movements. By incorporating cross-modal attention on the enriched facial priors, we can effectively align lip movements with audio, thus attaining greater precision in expression prediction. In the second component, we design a lightweight facial identity alignment (FIA) module which includes a lip-shape control structure and a face texture reference structure. This novel design allows us to generate fine details in real-time, without depending on sophisticated and inefficient feature alignment modules. Our experimental results, both quantitative and qualitative, on public datasets demonstrate the clear advantages of our method in terms of lip-speech synchronization and generation quality. Furthermore, our method is efficient and requires fewer computational resources, making it well-suited to meet the needs of practical applications.
Read more6/27/2024
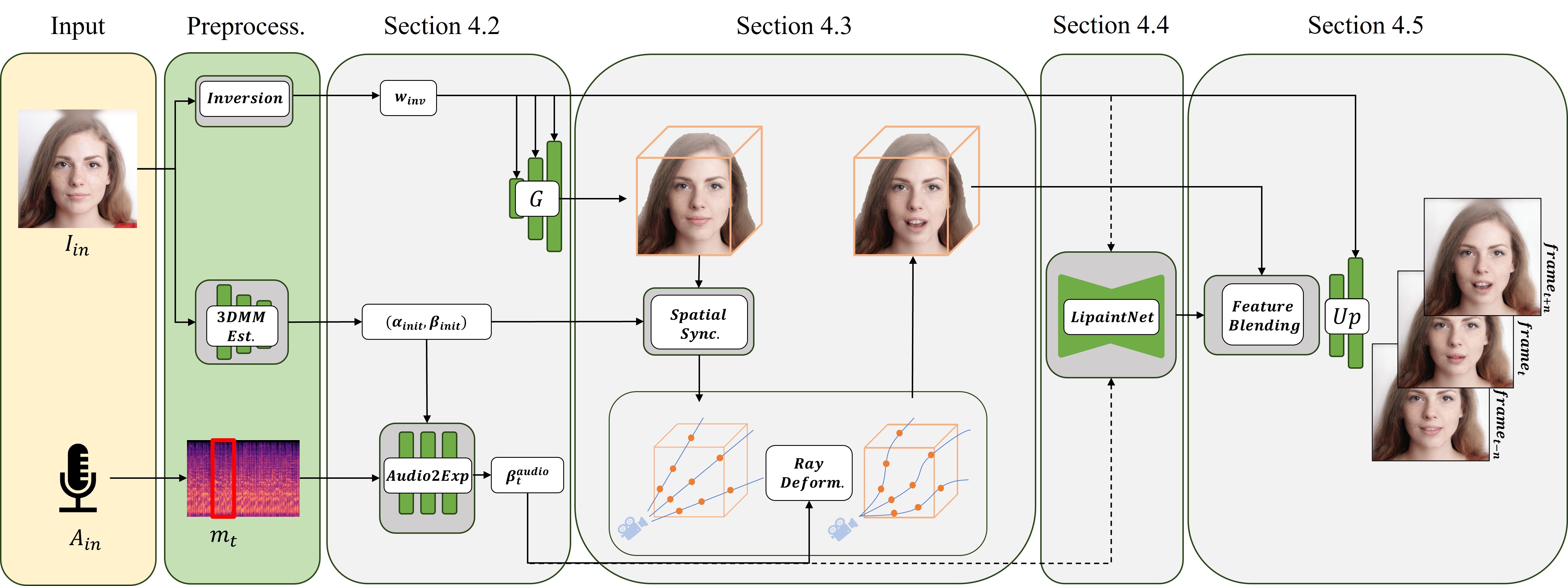
0
NeRFFaceSpeech: One-shot Audio-diven 3D Talking Head Synthesis via Generative Prior
Gihoon Kim, Kwanggyoon Seo, Sihun Cha, Junyong Noh
Audio-driven talking head generation is advancing from 2D to 3D content. Notably, Neural Radiance Field (NeRF) is in the spotlight as a means to synthesize high-quality 3D talking head outputs. Unfortunately, this NeRF-based approach typically requires a large number of paired audio-visual data for each identity, thereby limiting the scalability of the method. Although there have been attempts to generate audio-driven 3D talking head animations with a single image, the results are often unsatisfactory due to insufficient information on obscured regions in the image. In this paper, we mainly focus on addressing the overlooked aspect of 3D consistency in the one-shot, audio-driven domain, where facial animations are synthesized primarily in front-facing perspectives. We propose a novel method, NeRFFaceSpeech, which enables to produce high-quality 3D-aware talking head. Using prior knowledge of generative models combined with NeRF, our method can craft a 3D-consistent facial feature space corresponding to a single image. Our spatial synchronization method employs audio-correlated vertex dynamics of a parametric face model to transform static image features into dynamic visuals through ray deformation, ensuring realistic 3D facial motion. Moreover, we introduce LipaintNet that can replenish the lacking information in the inner-mouth area, which can not be obtained from a given single image. The network is trained in a self-supervised manner by utilizing the generative capabilities without additional data. The comprehensive experiments demonstrate the superiority of our method in generating audio-driven talking heads from a single image with enhanced 3D consistency compared to previous approaches. In addition, we introduce a quantitative way of measuring the robustness of a model against pose changes for the first time, which has been possible only qualitatively.
Read more5/13/2024