Jina CLIP: Your CLIP Model Is Also Your Text Retriever
2405.20204
0
0

Abstract
Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common embedding space by mapping them to fixed-sized vectors. These models are key to multimodal information retrieval and related tasks. However, CLIP models generally underperform in text-only tasks compared to specialized text models. This creates inefficiencies for information retrieval systems that keep separate embeddings and models for text-only and multimodal tasks. We propose a novel, multi-task contrastive training method to address this issue, which we use to train the jina-clip-v1 model to achieve the state-of-the-art performance on both text-image and text-text retrieval tasks.
Create account to get full access
Overview
- The paper introduces "Jina CLIP", a framework that allows users to leverage a pre-trained CLIP (Contrastive Language-Image Pre-training) model as a text retrieval system.
- CLIP models are typically used for image-text matching, but this work demonstrates how they can also be effectively used for text retrieval tasks.
- The framework provides tools and techniques to enable effective text retrieval using a pre-trained CLIP model, without the need for additional finetuning or specialized training.
Plain English Explanation
The paper discusses a way to use a CLIP model, which is a type of machine learning model that is trained to understand the relationship between images and the text that describes them, for the task of retrieving relevant text from a large collection of documents.
Typically, CLIP models are used to match images with the text that best describes them. However, the researchers behind this work found that CLIP models can also be used to search through a database of text documents and retrieve the ones that are most relevant to a given query.
To do this, the researchers developed a framework called "Jina CLIP" that provides the necessary tools and techniques to leverage a pre-trained CLIP model for text retrieval, without the need for additional training or fine-tuning. This means that users can take an existing CLIP model and use it to search through their own text data, without having to go through the process of training a new model from scratch.
The key benefit of this approach is that it allows users to take advantage of the powerful text understanding capabilities of CLIP models, which are typically trained on vast amounts of data, and apply them to their own text retrieval needs. This can be particularly useful for tasks like document search, customer support, or knowledge management, where the ability to quickly and accurately retrieve relevant information is crucial.
Technical Explanation
The paper introduces the "Jina CLIP" framework, which allows users to leverage a pre-trained CLIP model for text retrieval tasks. CLIP models are typically used for image-text matching, but the researchers demonstrate that they can also be effectively used for text retrieval.
The framework provides several key components:
-
Text Encoding: The CLIP model is used to encode text documents into dense vector representations, which can then be efficiently stored and indexed for fast retrieval.
-
Similarity Search: The framework includes tools for performing fast, approximate nearest neighbor search on the encoded text vectors, allowing for efficient retrieval of the most relevant documents given a text query.
-
Evaluation Metrics: The researchers introduce new evaluation metrics specifically designed for text retrieval using CLIP models, such as "Rank-CLIP" and "Long-CLIP", which measure the model's ability to retrieve relevant text across different task settings.
-
Deployment and Scaling: The Jina CLIP framework is designed to be easily deployed and scaled, with support for distributed and cloud-based architectures.
The paper also includes a comprehensive set of experiments, demonstrating the effectiveness of the Jina CLIP framework on a variety of text retrieval benchmarks. The results show that the approach can achieve strong performance without the need for additional finetuning or specialized training, highlighting the versatility of CLIP models for text-based tasks.
Critical Analysis
The paper presents a compelling approach for leveraging pre-trained CLIP models for text retrieval tasks. By providing a well-designed framework and evaluation metrics, the researchers have made it easier for users to apply CLIP models to their own text data and use cases.
One potential limitation of the approach is that it relies on the pre-trained CLIP model's ability to accurately encode text, which may not always be the case, especially for specialized or domain-specific text corpora. The paper does not address how the framework might perform in such scenarios, and further research may be needed to understand the limitations and potential failure modes of the approach.
Additionally, the paper does not delve into the computational efficiency and resource requirements of the Jina CLIP framework, which could be an important consideration for users with limited computing resources or real-time performance requirements.
Overall, the Jina CLIP framework represents a valuable contribution to the field of text retrieval, demonstrating the versatility of CLIP models and providing a practical tool for users to leverage these powerful language models for their own text-based applications. Further research and development in this area could lead to even more efficient and robust text retrieval systems.
Conclusion
The paper introduces the "Jina CLIP" framework, which enables users to leverage pre-trained CLIP models for text retrieval tasks. By providing the necessary tools and techniques, the framework allows users to take advantage of the powerful text understanding capabilities of CLIP models without the need for additional training or fine-tuning.
The key benefits of the Jina CLIP framework include its ability to efficiently encode text documents, perform fast similarity search, and provide specialized evaluation metrics for text retrieval. The comprehensive set of experiments presented in the paper demonstrates the effectiveness of the approach across a variety of benchmarks.
While the paper highlights the versatility of CLIP models for text-based tasks, it also raises some potential limitations and areas for further research, such as the model's performance on specialized text corpora and the computational efficiency of the framework. Nevertheless, the Jina CLIP framework represents an important step forward in the integration of CLIP models into practical text retrieval applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024
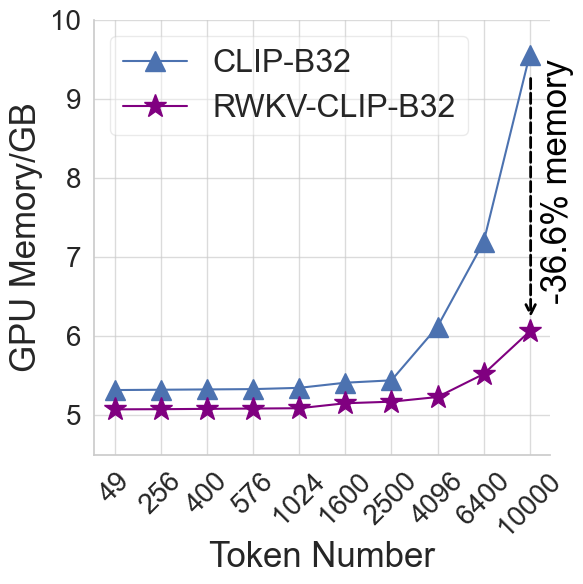
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024

CLIP-Branches: Interactive Fine-Tuning for Text-Image Retrieval
Christian Lulf, Denis Mayr Lima Martins, Marcos Antonio Vaz Salles, Yongluan Zhou, Fabian Gieseke
0
0
The advent of text-image models, most notably CLIP, has significantly transformed the landscape of information retrieval. These models enable the fusion of various modalities, such as text and images. One significant outcome of CLIP is its capability to allow users to search for images using text as a query, as well as vice versa. This is achieved via a joint embedding of images and text data that can, for instance, be used to search for similar items. Despite efficient query processing techniques such as approximate nearest neighbor search, the results may lack precision and completeness. We introduce CLIP-Branches, a novel text-image search engine built upon the CLIP architecture. Our approach enhances traditional text-image search engines by incorporating an interactive fine-tuning phase, which allows the user to further concretize the search query by iteratively defining positive and negative examples. Our framework involves training a classification model given the additional user feedback and essentially outputs all positively classified instances of the entire data catalog. By building upon recent techniques, this inference phase, however, is not implemented by scanning the entire data catalog, but by employing efficient index structures pre-built for the data. Our results show that the fine-tuned results can improve the initial search outputs in terms of relevance and accuracy while maintaining swift response times
6/21/2024
📊
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
0
0
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
4/9/2024