Jina-ColBERT-v2: A General-Purpose Multilingual Late Interaction Retriever

0

Sign in to get full access
Overview
- This paper introduces Jina-ColBERT-v2, a multilingual late interaction retriever.
- It aims to create a general-purpose retrieval model that can handle a wide range of tasks and languages.
- The model builds on the ColBERT architecture, adding improvements for better efficiency and performance.
Plain English Explanation
Jina-ColBERT-v2 is a new type of retrieval model that can search through large amounts of text in multiple languages and find the most relevant information. Unlike some earlier retrieval models that only looked at individual words, Jina-ColBERT-v2 considers the relationships between words and how they are used together.
This allows the model to better understand the meaning and context of the text, and retrieve information that is more relevant to the user's query. The model is also designed to be efficient, so it can quickly search through large databases of information without taking too much time or computing power.
One key feature of Jina-ColBERT-v2 is that it can work with many different languages, not just English. This makes it a more versatile tool that can be used in a variety of settings and applications.
Technical Explanation
Jina-ColBERT-v2 builds upon the ColBERT architecture, which is a late interaction retrieval model. Late interaction models first encode the query and documents separately, then perform a more sophisticated interaction step to match the query with the most relevant documents.
The key innovations in Jina-ColBERT-v2 include:
- Multilingual Support: The model is trained on a diverse dataset covering 100 languages, allowing it to work effectively across a wide range of languages.
- Efficiency Improvements: The authors introduce techniques to make the model more computationally efficient, such as using sparse representations and optimized training procedures.
- Retrieval Quality Enhancements: Several modifications are made to the ColBERT architecture to improve the overall quality of the retrieved results.
These improvements allow Jina-ColBERT-v2 to perform well on a variety of retrieval tasks, from document search to question answering, while maintaining efficiency and broad language support.
Critical Analysis
The paper provides a thorough evaluation of Jina-ColBERT-v2, demonstrating its strong performance across multiple benchmarks and use cases. However, some potential limitations and areas for further research are:
- Specialized Domains: While the model is designed as a general-purpose retriever, its performance may vary for highly specialized or technical domains that require more domain-specific knowledge.
- Fairness and Bias: As with many large language models, there are potential concerns about biases and fairness issues that should be carefully examined, especially when deploying the model in high-stakes applications.
- Interpretability: The late interaction architecture can make the model's decision-making process less transparent compared to simpler retrieval approaches. Improving the interpretability of such models is an important area for future research.
Overall, Jina-ColBERT-v2 represents a significant advancement in multilingual retrieval technology, but there is still room for further improvements and research to address some of its potential limitations.
Conclusion
Jina-ColBERT-v2 is a powerful and versatile retrieval model that can handle a wide range of languages and tasks. Its ability to efficiently process large amounts of text while maintaining high retrieval quality makes it a valuable tool for a variety of applications, from search engines to question-answering systems. While there are some areas for potential improvement, this research represents an important step forward in developing general-purpose, multilingual retrieval systems that can benefit users around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Jina-ColBERT-v2: A General-Purpose Multilingual Late Interaction Retriever
Rohan Jha, Bo Wang, Michael Gunther, Georgios Mastrapas, Saba Sturua, Isabelle Mohr, Andreas Koukounas, Mohammad Kalim Akram, Nan Wang, Han Xiao
Multi-vector dense models, such as ColBERT, have proven highly effective in information retrieval. ColBERT's late interaction scoring approximates the joint query-document attention seen in cross-encoders while maintaining inference efficiency closer to traditional dense retrieval models, thanks to its bi-encoder architecture and recent optimizations in indexing and search. In this work we propose a number of incremental improvements to the ColBERT model architecture and training pipeline, using methods shown to work in the more mature single-vector embedding model training paradigm, particularly those that apply to heterogeneous multilingual data or boost efficiency with little tradeoff. Our new model, Jina-ColBERT-v2, demonstrates strong performance across a range of English and multilingual retrieval tasks.
Read more9/17/2024
💬
0
JaColBERTv2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources
Benjamin Clavi'e
Neural Information Retrieval has advanced rapidly in high-resource languages, but progress in lower-resource ones such as Japanese has been hindered by data scarcity, among other challenges. Consequently, multilingual models have dominated Japanese retrieval, despite their computational inefficiencies and inability to capture linguistic nuances. While recent multi-vector monolingual models like JaColBERT have narrowed this gap, they still lag behind multilingual methods in large-scale evaluations. This work addresses the suboptimal training methods of multi-vector retrievers in lower-resource settings, focusing on Japanese. We systematically evaluate and improve key aspects of the inference and training settings of JaColBERT, and more broadly, multi-vector models. We further enhance performance through a novel checkpoint merging step, showcasing it to be an effective way of combining the benefits of fine-tuning with the generalization capabilities of the original checkpoint. Building on our analysis, we introduce a novel training recipe, resulting in the JaColBERTv2.5 model. JaColBERTv2.5, with only 110 million parameters and trained in under 15 hours on 4 A100 GPUs, significantly outperforms all existing methods across all common benchmarks, reaching an average score of 0.754, significantly above the previous best of 0.720. To support future research, we make our final models, intermediate checkpoints and all data used publicly available.
Read more7/31/2024

0
New!jina-embeddings-v3: Multilingual Embeddings With Task LoRA
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Gunther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Andreas Koukounas, Nan Wang, Han Xiao
We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens. The model includes a set of task-specific Low-Rank Adaptation (LoRA) adapters to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching. Additionally, Matryoshka Representation Learning is integrated into the training process, allowing flexible truncation of embedding dimensions without compromising performance. Evaluation on the MTEB benchmark shows that jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks, while achieving superior performance compared to multilingual-e5-large-instruct across all multilingual tasks.
Read more9/18/2024
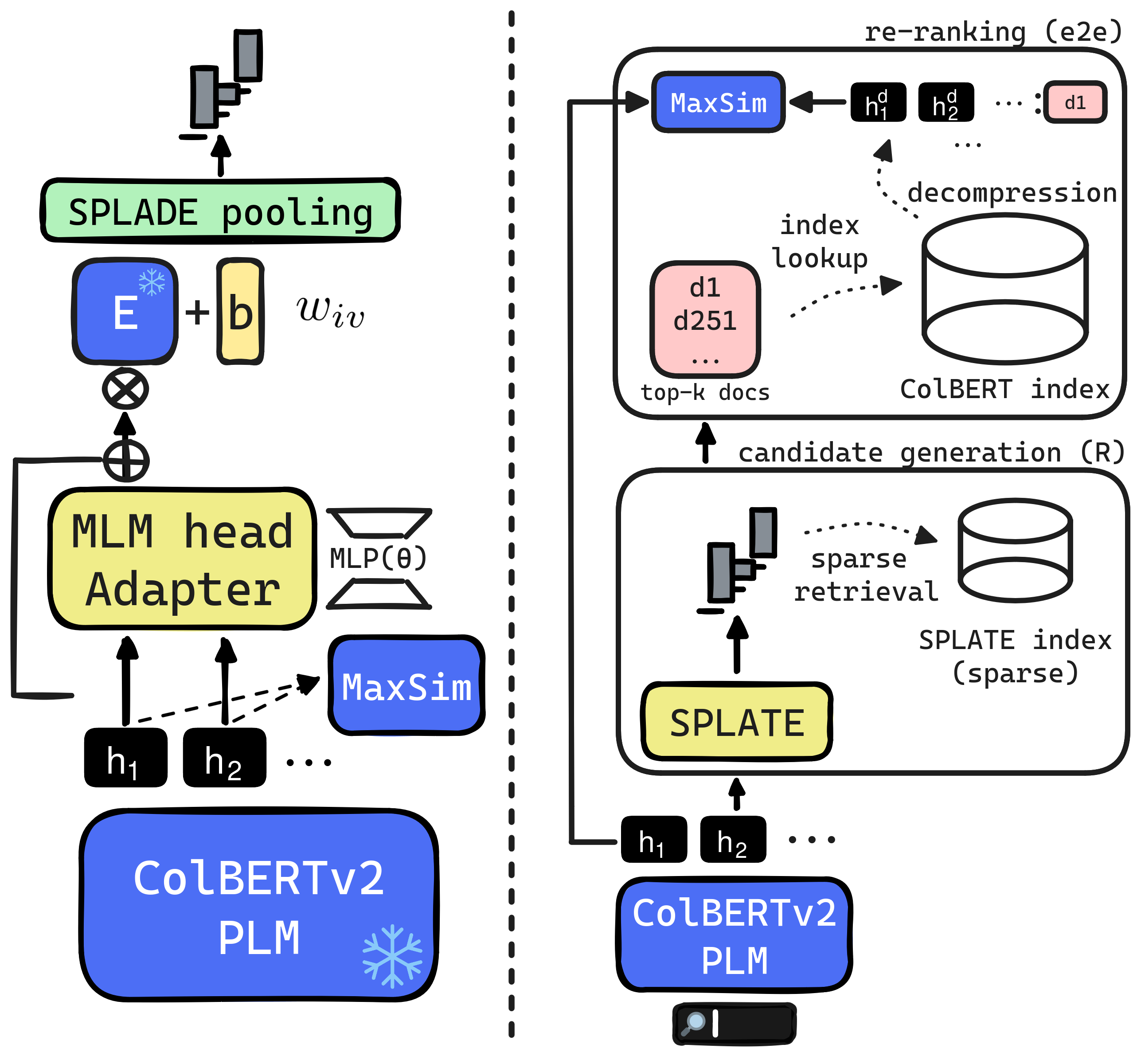
0
SPLATE: Sparse Late Interaction Retrieval
Thibault Formal, St'ephane Clinchant, Herv'e D'ejean, Carlos Lassance
The late interaction paradigm introduced with ColBERT stands out in the neural Information Retrieval space, offering a compelling effectiveness-efficiency trade-off across many benchmarks. Efficient late interaction retrieval is based on an optimized multi-step strategy, where an approximate search first identifies a set of candidate documents to re-rank exactly. In this work, we introduce SPLATE, a simple and lightweight adaptation of the ColBERTv2 model which learns an ``MLM adapter'', mapping its frozen token embeddings to a sparse vocabulary space with a partially learned SPLADE module. This allows us to perform the candidate generation step in late interaction pipelines with traditional sparse retrieval techniques, making it particularly appealing for running ColBERT in CPU environments. Our SPLATE ColBERTv2 pipeline achieves the same effectiveness as the PLAID ColBERTv2 engine by re-ranking 50 documents that can be retrieved under 10ms.
Read more4/23/2024