SPLATE: Sparse Late Interaction Retrieval

0
Sign in to get full access
Overview
- Introduces a new information retrieval method called SPLATE (Sparse Late Interaction Retrieval)
- Aims to improve efficiency and effectiveness of late interaction retrieval models
- Proposes a sparse approximation approach to reduce computational costs
Plain English Explanation
SPLATE is a new technique for information retrieval, which is the process of finding relevant documents or information in response to a user's query. Traditional retrieval models often involve a "late interaction" step, where the query and document representations are combined to determine relevance. However, this late interaction can be computationally expensive, especially for large-scale applications.
The researchers behind SPLATE have developed a way to make late interaction retrieval more efficient, without sacrificing effectiveness. Their approach is based on the idea of "sparse approximation" - instead of fully computing the late interaction, they use a sparse set of interactions to estimate the relevance. This reduces the computational costs while still maintaining the performance of the retrieval model.
To achieve this, SPLATE learns a sparse set of interactions during the training process, which can then be efficiently applied to new queries and documents. This means that the model can quickly determine the most relevant information, without having to perform a costly full computation.
The researchers have evaluated SPLATE on several standard information retrieval benchmarks, and have found that it outperforms other efficient late interaction retrieval methods in terms of both effectiveness and efficiency. This suggests that SPLATE could be a valuable tool for a wide range of information retrieval applications, from web search to academic literature search.
Technical Explanation
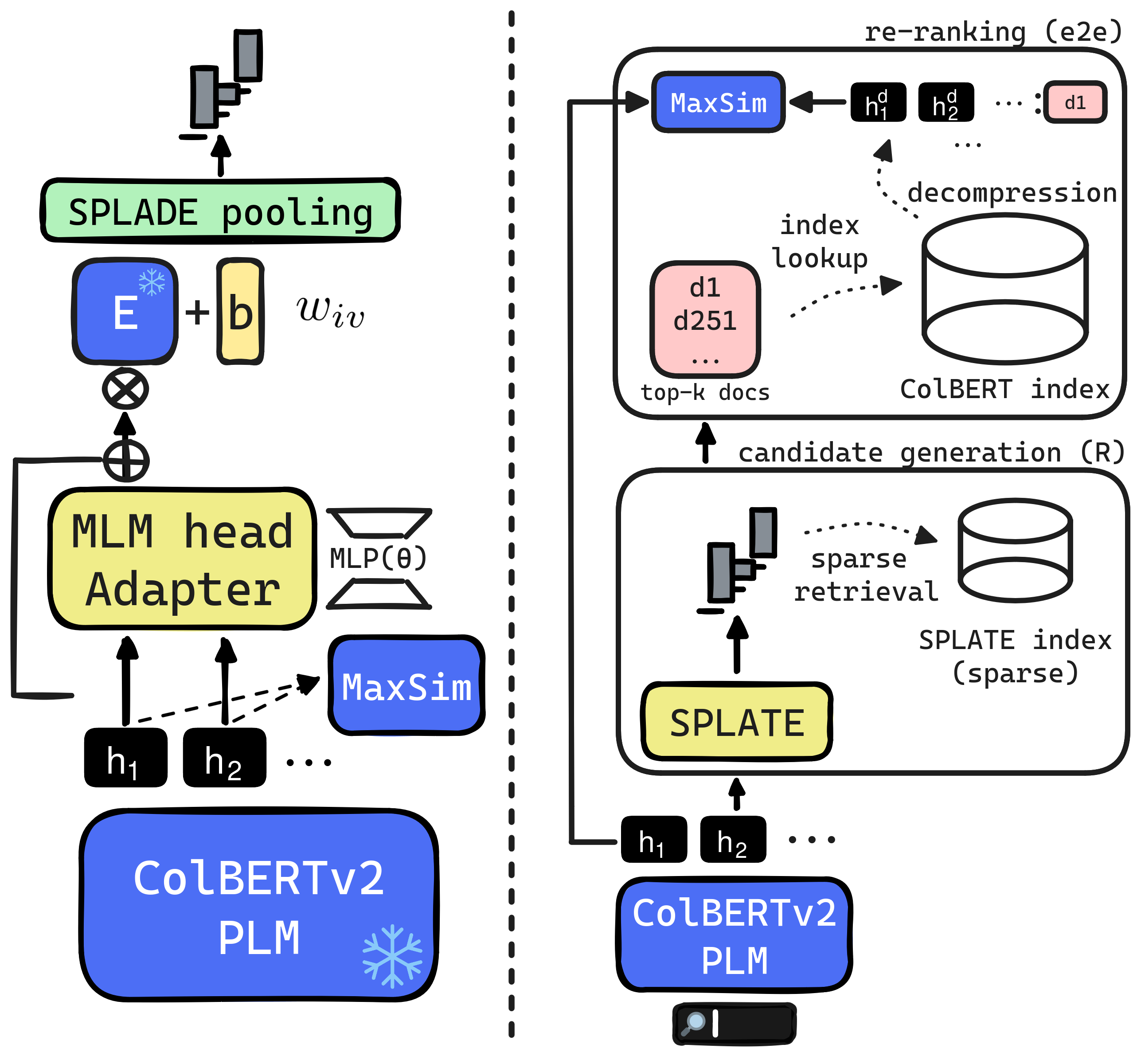
The paper introduces a new information retrieval method called SPLATE (Sparse Late Interaction Retrieval) that aims to improve the efficiency and effectiveness of late interaction retrieval models. Late interaction retrieval models, such as SPLADE, combine the query and document representations in a final step to determine relevance. While effective, this late interaction step can be computationally expensive, especially for large-scale applications.
The key idea behind SPLATE is to use a sparse approximation of the late interaction to reduce computational costs. During the training process, the model learns a sparse set of interactions that can be efficiently applied to new queries and documents. This sparse set of interactions is used to estimate the relevance, rather than performing a full late interaction computation.
The researchers evaluate SPLATE on several standard information retrieval benchmarks, including MS MARCO and ClueWeb09-B. They compare SPLATE to other efficient late interaction retrieval methods, such as Bi-Transformer and LLM-Augmented Retrieval. Their results show that SPLATE outperforms these methods in terms of both effectiveness and efficiency, demonstrating the value of the sparse approximation approach.
Critical Analysis
The SPLATE paper presents a promising approach to improving the efficiency of late interaction retrieval models without sacrificing effectiveness. The sparse approximation technique is a clever way to reduce computational costs, and the experimental results suggest that it can be a valuable tool for a wide range of information retrieval applications.
However, the paper does not address some potential limitations or areas for further research. For example, the performance of SPLATE may be sensitive to the specific dataset or task, and it's unclear how well the approach would generalize to different types of retrieval problems or languages. Additionally, the paper does not provide a detailed analysis of the trade-offs between the level of sparsity and the resulting retrieval performance.
Furthermore, while the paper compares SPLATE to other efficient late interaction methods, it would be interesting to see how it performs relative to more traditional retrieval models, such as BM25 or TF-IDF. This could help contextualize the benefits of the SPLATE approach and identify any potential limitations.
Overall, the SPLATE paper presents a valuable contribution to the field of information retrieval, but further research and analysis would be needed to fully understand the strengths, weaknesses, and potential applications of this technique.
Conclusion
The SPLATE paper introduces a new, efficient late interaction retrieval method that uses a sparse approximation approach to reduce computational costs without sacrificing effectiveness. By learning a sparse set of interactions during the training process, SPLATE is able to quickly estimate the relevance of documents for a given query, making it a promising tool for large-scale information retrieval applications.
The experimental results demonstrate the value of the SPLATE approach, showing that it outperforms other efficient late interaction methods on standard benchmarks. While the paper does not address all potential limitations, it represents an important step forward in improving the efficiency of information retrieval systems, which could have significant implications for a wide range of applications, from web search to academic literature search.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SPLATE: Sparse Late Interaction Retrieval
Thibault Formal, St'ephane Clinchant, Herv'e D'ejean, Carlos Lassance
The late interaction paradigm introduced with ColBERT stands out in the neural Information Retrieval space, offering a compelling effectiveness-efficiency trade-off across many benchmarks. Efficient late interaction retrieval is based on an optimized multi-step strategy, where an approximate search first identifies a set of candidate documents to re-rank exactly. In this work, we introduce SPLATE, a simple and lightweight adaptation of the ColBERTv2 model which learns an ``MLM adapter'', mapping its frozen token embeddings to a sparse vocabulary space with a partially learned SPLADE module. This allows us to perform the candidate generation step in late interaction pipelines with traditional sparse retrieval techniques, making it particularly appealing for running ColBERT in CPU environments. Our SPLATE ColBERTv2 pipeline achieves the same effectiveness as the PLAID ColBERTv2 engine by re-ranking 50 documents that can be retrieved under 10ms.
Read more4/23/2024

0
Mistral-SPLADE: LLMs for for better Learned Sparse Retrieval
Meet Doshi, Vishwajeet Kumar, Rudra Murthy, Vignesh P, Jaydeep Sen
Learned Sparse Retrievers (LSR) have evolved into an effective retrieval strategy that can bridge the gap between traditional keyword-based sparse retrievers and embedding-based dense retrievers. At its core, learned sparse retrievers try to learn the most important semantic keyword expansions from a query and/or document which can facilitate better retrieval with overlapping keyword expansions. LSR like SPLADE has typically been using encoder only models with MLM (masked language modeling) style objective in conjunction with known ways of retrieval performance improvement such as hard negative mining, distillation, etc. In this work, we propose to use decoder-only model for learning semantic keyword expansion. We posit, decoder only models that have seen much higher magnitudes of data are better equipped to learn keyword expansions needed for improved retrieval. We use Mistral as the backbone to develop our Learned Sparse Retriever similar to SPLADE and train it on a subset of sentence-transformer data which is often used for training text embedding models. Our experiments support the hypothesis that a sparse retrieval model based on decoder only large language model (LLM) surpasses the performance of existing LSR systems, including SPLADE and all its variants. The LLM based model (Echo-Mistral-SPLADE) now stands as a state-of-the-art learned sparse retrieval model on the BEIR text retrieval benchmark.
Read more8/23/2024
🔍
0
PLAID SHIRTTT for Large-Scale Streaming Dense Retrieval
Dawn Lawrie, Efsun Kayi, Eugene Yang, James Mayfield, Douglas W. Oard
PLAID, an efficient implementation of the ColBERT late interaction bi-encoder using pretrained language models for ranking, consistently achieves state-of-the-art performance in monolingual, cross-language, and multilingual retrieval. PLAID differs from ColBERT by assigning terms to clusters and representing those terms as cluster centroids plus compressed residual vectors. While PLAID is effective in batch experiments, its performance degrades in streaming settings where documents arrive over time because representations of new tokens may be poorly modeled by the earlier tokens used to select cluster centroids. PLAID Streaming Hierarchical Indexing that Runs on Terabytes of Temporal Text (PLAID SHIRTTT) addresses this concern using multi-phase incremental indexing based on hierarchical sharding. Experiments on ClueWeb09 and the multilingual NeuCLIR collection demonstrate the effectiveness of this approach both for the largest collection indexed to date by the ColBERT architecture and in the multilingual setting, respectively.
Read more5/3/2024
🤷
0
CoSPLADE: Contextualizing SPLADE for Conversational Information Retrieval
Nam Le Hai, Thomas Gerald, Thibault Formal, Jian-Yun Nie, Benjamin Piwowarski, Laure Soulier
Conversational search is a difficult task as it aims at retrieving documents based not only on the current user query but also on the full conversation history. Most of the previous methods have focused on a multi-stage ranking approach relying on query reformulation, a critical intermediate step that might lead to a sub-optimal retrieval. Other approaches have tried to use a fully neural IR first-stage, but are either zero-shot or rely on full learning-to-rank based on a dataset with pseudo-labels. In this work, leveraging the CANARD dataset, we propose an innovative lightweight learning technique to train a first-stage ranker based on SPLADE. By relying on SPLADE sparse representations, we show that, when combined with a second-stage ranker based on T5Mono, the results are competitive on the TREC CAsT 2020 and 2021 tracks.
Read more7/8/2024