Joint Multimodal Transformer for Emotion Recognition in the Wild
2403.10488
0
0

Abstract
Multimodal emotion recognition (MMER) systems typically outperform unimodal systems by leveraging the inter- and intra-modal relationships between, e.g., visual, textual, physiological, and auditory modalities. This paper proposes an MMER method that relies on a joint multimodal transformer (JMT) for fusion with key-based cross-attention. This framework can exploit the complementary nature of diverse modalities to improve predictive accuracy. Separate backbones capture intra-modal spatiotemporal dependencies within each modality over video sequences. Subsequently, our JMT fusion architecture integrates the individual modality embeddings, allowing the model to effectively capture inter- and intra-modal relationships. Extensive experiments on two challenging expression recognition tasks -- (1) dimensional emotion recognition on the Affwild2 dataset (with face and voice) and (2) pain estimation on the Biovid dataset (with face and biosensors) -- indicate that our JMT fusion can provide a cost-effective solution for MMER. Empirical results show that MMER systems with our proposed fusion allow us to outperform relevant baseline and state-of-the-art methods.
Create account to get full access
Overview
- This paper proposes a new multimodal transformer model for dimensional emotional recognition in real-world scenarios.
- The model combines visual, audio, and text inputs to predict continuous scores for valence (positivity/negativity) and arousal (calmness/excitement).
- The authors evaluate their model on several challenging datasets and show improvements over previous state-of-the-art approaches.
Plain English Explanation
The researchers have developed a new artificial intelligence (AI) system that can understand and analyze human emotions from different types of data, such as facial expressions, voice recordings, and text. Traditionally, emotion recognition has been a difficult task for computers, but this new system aims to do it more accurately by combining information from multiple sources.
The key idea is to use a special type of neural network called a "transformer" that can effectively process and combine visual, audio, and text data. This allows the system to get a more well-rounded understanding of the person's emotional state, looking at not just their face but also how they are speaking and what they are saying.
The researchers tested their system on several real-world datasets, where people expressed emotions in natural, uncontrolled settings. They found that their multimodal transformer model outperformed previous approaches that relied on a single type of data. This suggests the combination of different information sources is crucial for accurately recognizing emotions in complex, real-world scenarios.
Technical Explanation
The paper introduces a Joint Multimodal Transformer (JMT) architecture for dimensional emotion recognition. The model takes in visual, audio, and text inputs and learns to predict continuous valence (positivity/negativity) and arousal (calmness/excitement) scores.
The visual input is processed by a pre-trained vision transformer, the audio by a pre-trained audio transformer, and the text by a pre-trained language model. These modality-specific representations are then combined through a series of transformer layers that learn cross-modal interactions. The final outputs are the predicted valence and arousal values.
The authors evaluate JMT on three in-the-wild emotion recognition datasets: CREMA-D, RAVDESS, and IEMOCAP. They compare against unimodal baselines as well as previous state-of-the-art multimodal approaches. The results demonstrate the effectiveness of the joint multimodal transformer architecture, with JMT outperforming other methods across the various evaluation metrics.
Critical Analysis
The paper makes a compelling case for the benefits of a multimodal transformer-based approach to emotion recognition. The authors thoroughly evaluate their model and provide insightful analyses of the results. However, a few potential limitations and areas for future work are worth noting.
First, the datasets used, while challenging, are still somewhat constrained and may not fully reflect the complexity of real-world emotional expressions. Extending the evaluation to even more naturalistic settings could further validate the model's capabilities.
Additionally, the paper does not provide much detail on the model's interpretability or explainability. Understanding how the different modalities and transformer components contribute to the final predictions could lead to important insights about emotional processing.
Finally, the authors mention the potential for the JMT model to be used in applications such as human-computer interaction and mental health monitoring. Careful consideration of ethical implications, such as privacy and fairness concerns, will be crucial as this technology is developed further.
Conclusion
This paper presents a novel multimodal transformer-based approach for dimensional emotion recognition that outperforms previous state-of-the-art methods. By effectively combining visual, audio, and text inputs, the Joint Multimodal Transformer model demonstrates strong performance on challenging real-world datasets.
The research highlights the value of integrating multiple information sources for robust and accurate emotion recognition, with potential applications in areas like human-computer interaction and mental health monitoring. While the model shows promising results, continued exploration of its limitations and ethical considerations will be important as this technology matures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
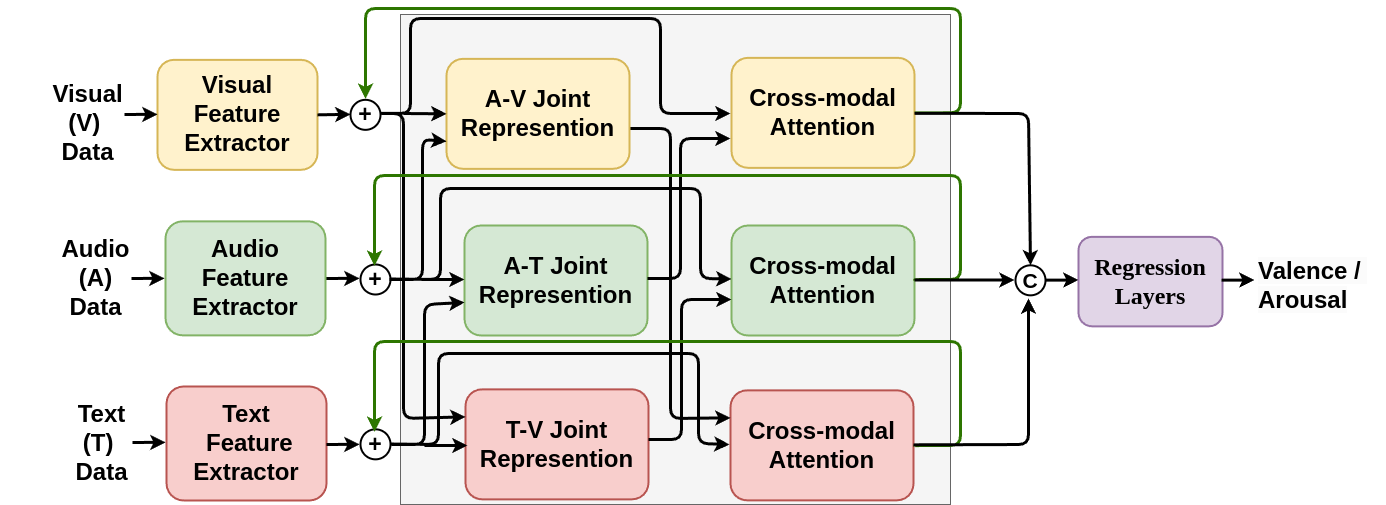
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Jahangir Alam
0
0
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra- and inter-modal relationships across audio, visual, and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and intermodal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual, and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.674 (0.619) for valence and arousal respectively on the validation set(test set). This shows a significant improvement over the baseline of 0.240 (0.211) and 0.200 (0.191) for valence and arousal, respectively, in the validation set (test set), achieving second place in the valence-arousal challenge of the 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
4/16/2024
🌐
A Multimodal Fusion Network For Student Emotion Recognition Based on Transformer and Tensor Product
Ao Xiang, Zongqing Qi, Han Wang, Qin Yang, Danqing Ma
0
0
This paper introduces a new multi-modal model based on the Transformer architecture and tensor product fusion strategy, combining BERT's text vectors and ViT's image vectors to classify students' psychological conditions, with an accuracy of 93.65%. The purpose of the study is to accurately analyze the mental health status of students from various data sources. This paper discusses modal fusion methods, including early, late and intermediate fusion, to overcome the challenges of integrating multi-modal information. Ablation studies compare the performance of different models and fusion techniques, showing that the proposed model outperforms existing methods such as CLIP and ViLBERT in terms of accuracy and inference speed. Conclusions indicate that while this model has significant advantages in emotion recognition, its potential to incorporate other data modalities provides areas for future research.
4/22/2024
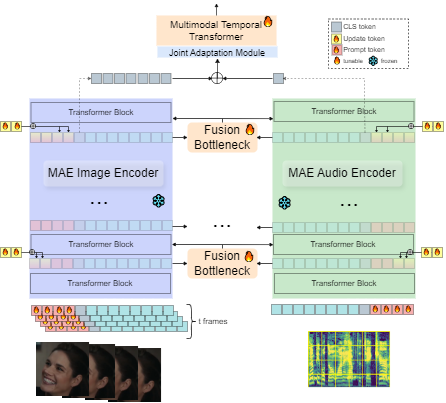
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Kateryna Chumachenko, Alexandros Iosifidis, Moncef Gabbouj
0
0
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
4/16/2024
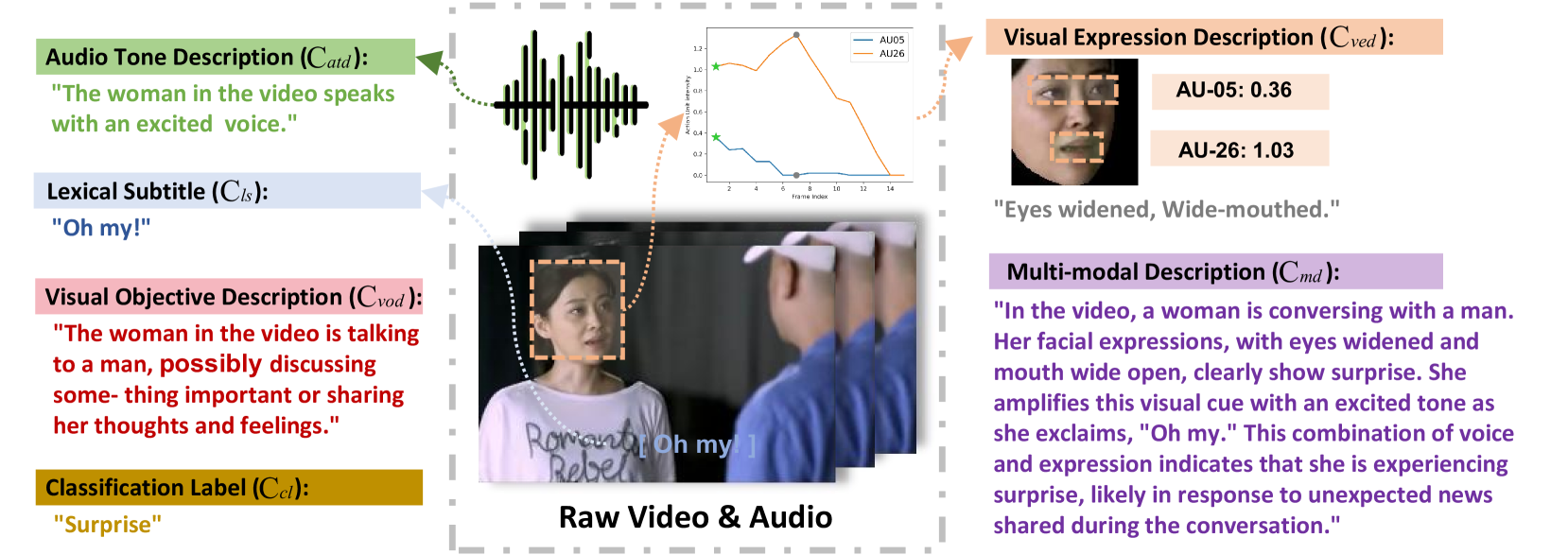
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024