Joint Optimization of Resource Allocation and Data Selection for Fast and Cost-Efficient Federated Edge Learning

0
Sign in to get full access
Overview
- This paper proposes a joint optimization approach for resource allocation and data selection in federated edge learning (FEL) systems.
- The goal is to achieve fast and cost-efficient FEL by addressing challenges such as mislabeling, heterogeneous device capabilities, and limited communication resources.
- The authors develop an optimization framework that simultaneously optimizes the allocation of computational and communication resources and the selection of training data to minimize the overall training cost and time.
Plain English Explanation
In federated edge learning (FEL), multiple edge devices collaborate to train a machine learning model without sending their raw data to a central server. This can be more efficient and privacy-preserving than traditional centralized training. However, FEL faces challenges such as mislabeled data, varying device capabilities, and limited communication bandwidth.
The researchers in this paper propose a way to address these challenges by jointly optimizing the allocation of computational and communication resources and the selection of training data. Imagine you're baking a cake and need to decide how much flour, sugar, and time to use. Similarly, in FEL, the system needs to determine how much processing power and network bandwidth to give each device, as well as which data samples each device should use for training.
By making these decisions together, the system can achieve faster convergence and lower overall training costs compared to approaches that optimize these elements separately. For example, the system might allocate more resources to devices with high-quality, trustworthy data, while limiting the impact of devices with mislabeled data.
Technical Explanation
The authors formulate the problem as a joint optimization of resource allocation and data selection, with the objective of minimizing the overall training cost and time. The key elements of their approach include:
- Resource Allocation: The system determines the computational and communication resources (e.g., CPU, bandwidth) to allocate to each participating device, considering their heterogeneous capabilities.
- Data Selection: The system selects a subset of the available training data on each device, prioritizing high-quality samples and mitigating the impact of mislabeled data.
- Joint Optimization: The resource allocation and data selection decisions are optimized simultaneously, allowing the system to find a balance that achieves fast convergence and low training costs.
The authors develop a multi-stage optimization algorithm to solve this problem and evaluate their approach on both synthetic and real-world datasets. Their results demonstrate that the joint optimization approach outperforms methods that optimize these elements separately, leading to improved efficiency and performance.
Critical Analysis
The paper presents a comprehensive approach to addressing key challenges in FEL systems, and the joint optimization framework is a novel and promising solution. However, some potential limitations and areas for further research include:
- Complexity: The optimization problem formulated in the paper may be computationally complex, especially for large-scale FEL systems with many participating devices. The authors acknowledge this and suggest investigating more efficient optimization algorithms.
- Practical Considerations: The paper does not extensively discuss practical implementation details, such as how the system would handle dynamic changes in device availability or the impact of communication delays and failures.
- Generalizability: The evaluation is focused on specific datasets and task types. Further research is needed to assess the generalizability of the approach to a wider range of FEL applications.
Overall, this paper presents an important contribution to the field of federated edge learning by addressing key challenges and demonstrating the value of jointly optimizing resource allocation and data selection.
Conclusion
This paper proposes a novel approach to federated edge learning that jointly optimizes the allocation of computational and communication resources and the selection of training data. By addressing challenges such as mislabeling, device heterogeneity, and limited communication resources, the authors' framework can achieve faster convergence and lower overall training costs compared to existing methods.
The key insights from this research have the potential to enhance the efficiency and performance of multi-device federated learning systems, enabling more practical and cost-effective deployment of FEL in real-world applications. As the field of edge computing and distributed machine learning continues to evolve, this work represents an important step forward in optimizing the use of limited resources to deliver high-quality, responsive AI services at the edge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Joint Optimization of Resource Allocation and Data Selection for Fast and Cost-Efficient Federated Edge Learning
Yunjian Jia, Zhen Huang, Jiping Yan, Yulu Zhang, Kun Luo, Wanli Wen
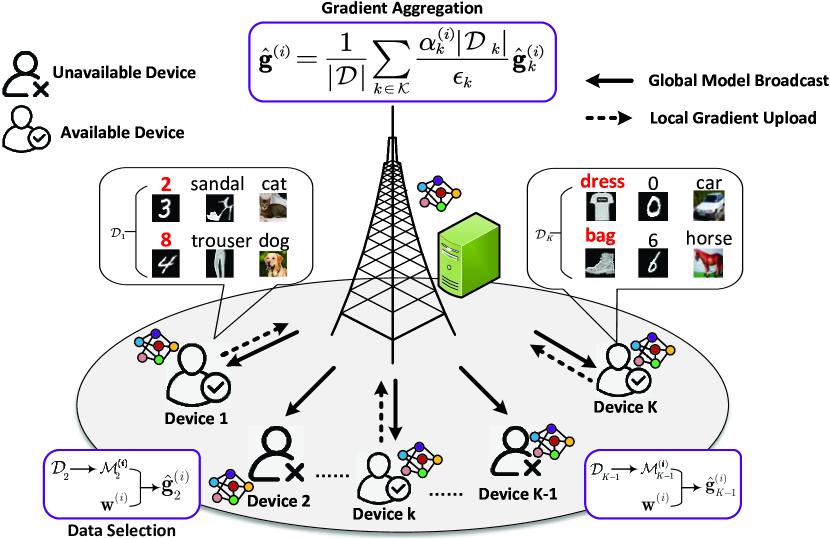
Deploying federated learning at the wireless edge introduces federated edge learning (FEEL). Given FEEL's limited communication resources and potential mislabeled data on devices, improper resource allocation or data selection can hurt convergence speed and increase training costs. Thus, to realize an efficient FEEL system, this paper emphasizes jointly optimizing resource allocation and data selection. Specifically, in this work, through rigorously modeling the training process and deriving an upper bound on FEEL's one-round convergence rate, we establish a problem of joint resource allocation and data selection, which, unfortunately, cannot be solved directly. Toward this end, we equivalently transform the original problem into a solvable form via a variable substitution and then break it into two subproblems, that is, the resource allocation problem and the data selection problem. The two subproblems are mixed-integer non-convex and integer non-convex problems, respectively, and achieving their optimal solutions is a challenging task. Based on the matching theory and applying the convex-concave procedure and gradient projection methods, we devise a low-complexity suboptimal algorithm for the two subproblems, respectively. Finally, the superiority of our proposed scheme of joint resource allocation and data selection is validated by numerical results.
Read more7/4/2024
🛠️
0
Energy-Efficient Federated Edge Learning with Streaming Data: A Lyapunov Optimization Approach
Chung-Hsuan Hu, Zheng Chen, Erik G. Larsson
Federated learning (FL) has received significant attention in recent years for its advantages in efficient training of machine learning models across distributed clients without disclosing user-sensitive data. Specifically, in federated edge learning (FEEL) systems, the time-varying nature of wireless channels introduces inevitable system dynamics in the communication process, thereby affecting training latency and energy consumption. In this work, we further consider a streaming data scenario where new training data samples are randomly generated over time at edge devices. Our goal is to develop a dynamic scheduling and resource allocation algorithm to address the inherent randomness in data arrivals and resource availability under long-term energy constraints. To achieve this, we formulate a stochastic network optimization problem and use the Lyapunov drift-plus-penalty framework to obtain a dynamic resource management design. Our proposed algorithm makes adaptive decisions on device scheduling, computational capacity adjustment, and allocation of bandwidth and transmit power in every round. We provide convergence analysis for the considered setting with heterogeneous data and time-varying objective functions, which supports the rationale behind our proposed scheduling design. The effectiveness of our scheme is verified through simulation results, demonstrating improved learning performance and energy efficiency as compared to baseline schemes.
Read more5/21/2024

0
Faster Convergence on Heterogeneous Federated Edge Learning: An Adaptive Sidelink-Assisted Data Multicasting Approach
Gang Hu, Yinglei Teng, Nan Wang, Zhu Han
Federated Edge Learning (FEEL) emerges as a pioneering distributed machine learning paradigm for the 6G Hyper-Connectivity, harnessing data from the Internet of Things (IoT) devices while upholding data privacy. However, current FEEL algorithms struggle with non-independent and non-identically distributed (non-IID) data, leading to elevated communication costs and compromised model accuracy. To address these statistical imbalances within FEEL, we introduce a clustered data sharing framework, mitigating data heterogeneity by selectively sharing partial data from cluster heads to trusted associates through sidelink-aided multicasting. The collective communication pattern is integral to FEEL training, where both cluster formation and the efficiency of communication and computation impact training latency and accuracy simultaneously. To tackle the strictly coupled data sharing and resource optimization, we decompose the overall optimization problem into the clients clustering and effective data sharing subproblems. Specifically, a distribution-based adaptive clustering algorithm (DACA) is devised basing on three deductive cluster forming conditions, which ensures the maximum sharing yield. Meanwhile, we design a stochastic optimization based joint computed frequency and shared data volume optimization (JFVO) algorithm, determining the optimal resource allocation with an uncertain objective function. The experiments show that the proposed framework facilitates FEEL on non-IID datasets with faster convergence rate and higher model accuracy in a limited communication environment.
Read more7/9/2024
0
Toward efficient resource utilization at edge nodes in federated learning
Sadi Alawadi, Addi Ait-Mlouk, Salman Toor, Andreas Hellander
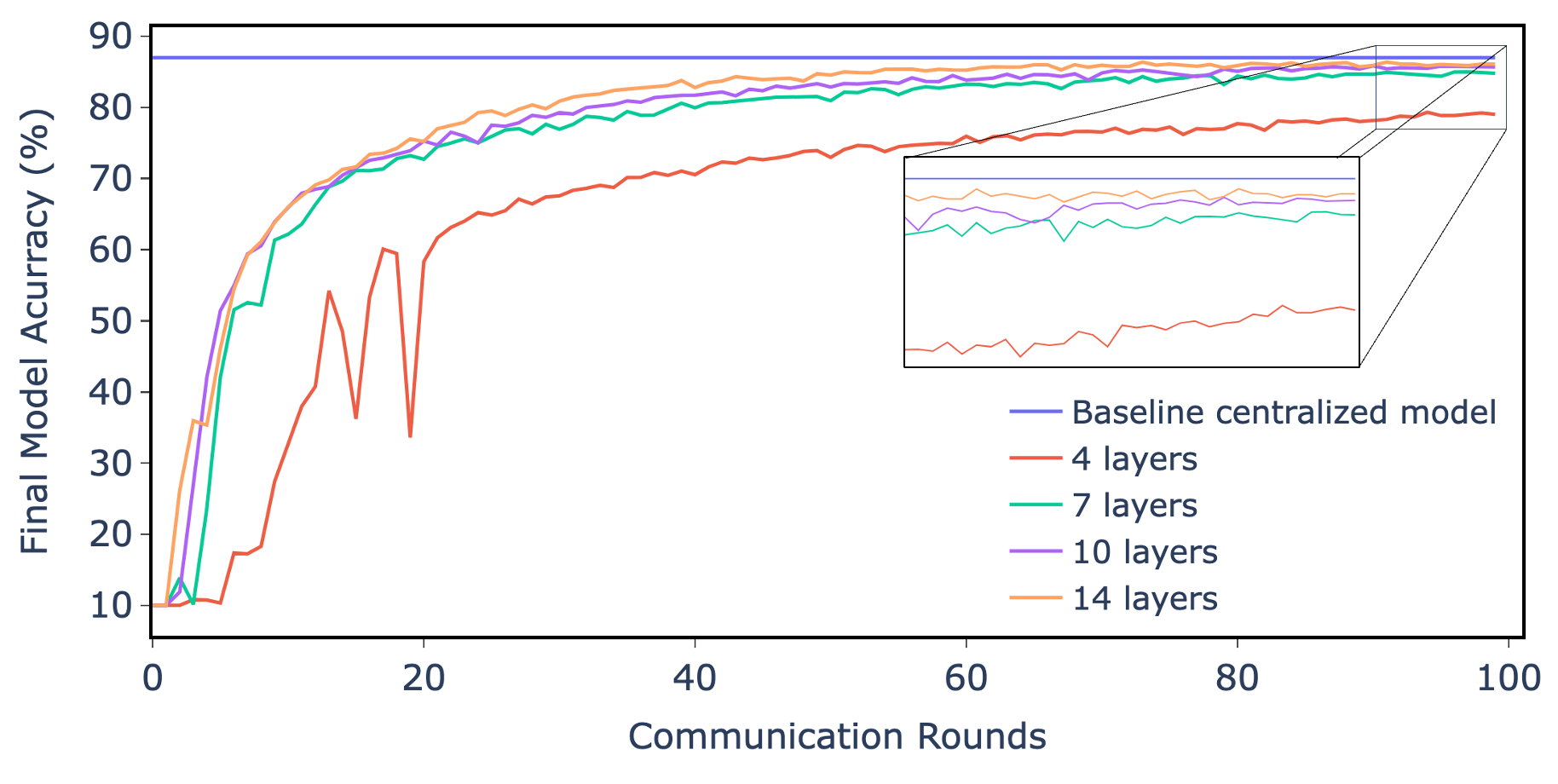
Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
Read more6/12/2024