Joint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content

0
Sign in to get full access
Overview
- Disentangled representation learning to separate image content from appearance
- Novel approach for joint quality assessment and example-guided image processing
- Enables fine-grained control over image attributes like tone mapping, color, and contrast
Plain English Explanation
This research paper proposes a new way to process and edit digital images. The key idea is to separate the "content" of an image - what the image is actually showing - from its "appearance" - things like the color, contrast, and overall look and feel.
By disentangling these two aspects, the researchers developed a system that can assess the quality of an image and then adjust its appearance based on example images. For example, you could take a photo and use this system to make it look more like a professional photograph, without changing the actual subject of the image.
This could be useful for things like high dynamic range (HDR) imaging, where the goal is to capture a wide range of brightness levels in a single image. It could also help with editing and enhancing photos to match a certain style or aesthetic.
The key innovation is the ability to independently control the content and appearance of an image, which gives users much finer control over the final result compared to traditional image editing tools.
Technical Explanation
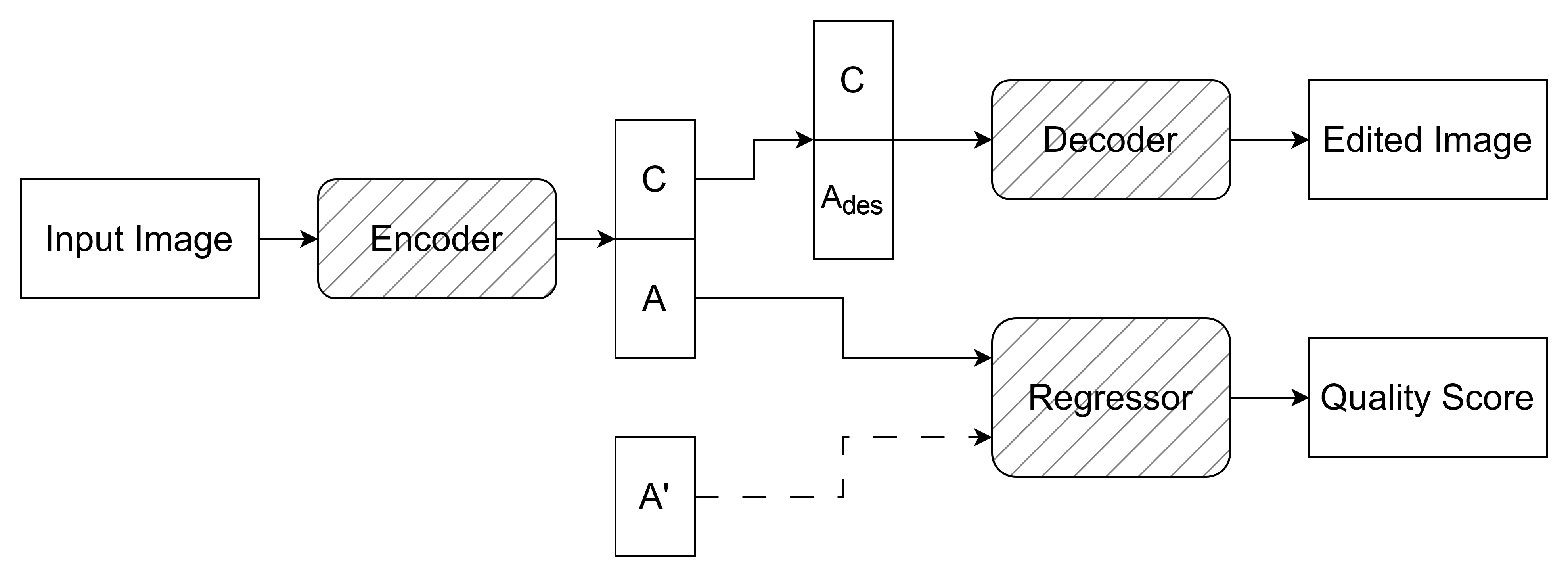
The researchers developed a deep learning-based framework that can disentangle the content and appearance representations of an image. This is achieved through the use of a content encoder and an appearance encoder, which learn to extract these distinct factors of variation from the input image.
The content encoder captures the semantic information and structural details of the image, while the appearance encoder learns to model the low-level visual attributes like color, tone, and texture. By combining these two latent representations, the system can reconstruct the original image.
Crucially, the researchers also developed a quality assessment module that can evaluate the perceptual quality of the reconstructed image. This allows the system to not only process the image, but also assess how well it has done in preserving the original content and enhancing the appearance.
The framework is trained in an end-to-end manner on a large dataset of natural images. During inference, users can provide example images to guide the appearance transformation of a target image, enabling example-guided image processing. This gives users fine-grained control over the final visual output.
Critical Analysis
The researchers have demonstrated promising results on a variety of image processing tasks, including tone mapping, color adjustment, and contrast enhancement. However, the paper does not provide a comprehensive evaluation of the system's performance across a wide range of image types and processing scenarios.
Additionally, the paper does not address potential issues with content preservation - it is possible that in some cases, the appearance transformations could inadvertently alter the semantic content of the image. Further research is needed to ensure the system maintains fidelity to the original image content.
Another area for improvement is the quality assessment module. While the researchers show that it can effectively evaluate perceptual quality, it would be valuable to understand how it compares to human judgments of image quality, and whether it can generalize to a diverse range of image types and processing tasks.
Conclusion
This research presents a novel approach to image processing that leverages disentangled representation learning to independently control the content and appearance of an image. The ability to guide the appearance transformation using example images is a particularly compelling feature, as it allows users to achieve fine-grained control over the final visual output.
While the paper demonstrates promising results, further research is needed to fully evaluate the system's performance, robustness, and generalization capabilities. Nonetheless, this work represents an important step towards more advanced and user-friendly image editing tools that can enhance the visual quality of digital images while preserving their semantic content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Joint Quality Assessment and Example-Guided Image Processing by Disentangling Picture Appearance from Content
Abhinau K. Venkataramanan, Cosmin Stejerean, Ioannis Katsavounidis, Hassene Tmar, Alan C. Bovik
The deep learning revolution has strongly impacted low-level image processing tasks such as style/domain transfer, enhancement/restoration, and visual quality assessments. Despite often being treated separately, the aforementioned tasks share a common theme of understanding, editing, or enhancing the appearance of input images without modifying the underlying content. We leverage this observation to develop a novel disentangled representation learning method that decomposes inputs into content and appearance features. The model is trained in a self-supervised manner and we use the learned features to develop a new quality prediction model named DisQUE. We demonstrate through extensive evaluations that DisQUE achieves state-of-the-art accuracy across quality prediction tasks and distortion types. Moreover, we demonstrate that the same features may also be used for image processing tasks such as HDR tone mapping, where the desired output characteristics may be tuned using example input-output pairs.
Read more4/23/2024

0
Vision Language Modeling of Content, Distortion and Appearance for Image Quality Assessment
Fei Zhou, Zhicong Huang, Tianhao Gu, Guoping Qiu
The visual quality of an image is confounded by a number of intertwined factors including its semantic content, distortion characteristics and appearance properties such as brightness, contrast, sharpness, and colourfulness. Distilling high level knowledge about all these quality bearing attributes is crucial for developing objective Image Quality Assessment (IQA).While existing solutions have modeled some of these aspects, a comprehensive solution that involves all these important quality related attributes has not yet been developed. In this paper, we present a new blind IQA (BIQA) model termed Self-supervision and Vision-Language supervision Image QUality Evaluator (SLIQUE) that features a joint vision-language and visual contrastive representation learning framework for acquiring high level knowledge about the images semantic contents, distortion characteristics and appearance properties for IQA. For training SLIQUE, we have developed a systematic approach to constructing a first of its kind large image database annotated with all three categories of quality relevant texts. The Text Annotated Distortion, Appearance and Content (TADAC) database has over 1.6 million images annotated with textual descriptions of their semantic contents, distortion characteristics and appearance properties. The method for constructing TADAC and the database itself will be particularly useful for exploiting vision-language modeling for advanced IQA applications. Extensive experimental results show that SLIQUE has superior performances over state of the art, demonstrating the soundness of its design principle and the effectiveness of its implementation.
Read more6/24/2024

0
Assessing UHD Image Quality from Aesthetics, Distortions, and Saliency
Wei Sun, Weixia Zhang, Yuqin Cao, Linhan Cao, Jun Jia, Zijian Chen, Zicheng Zhang, Xiongkuo Min, Guangtao Zhai
UHD images, typically with resolutions equal to or higher than 4K, pose a significant challenge for efficient image quality assessment (IQA) algorithms, as adopting full-resolution images as inputs leads to overwhelming computational complexity and commonly used pre-processing methods like resizing or cropping may cause substantial loss of detail. To address this problem, we design a multi-branch deep neural network (DNN) to assess the quality of UHD images from three perspectives: global aesthetic characteristics, local technical distortions, and salient content perception. Specifically, aesthetic features are extracted from low-resolution images downsampled from the UHD ones, which lose high-frequency texture information but still preserve the global aesthetics characteristics. Technical distortions are measured using a fragment image composed of mini-patches cropped from UHD images based on the grid mini-patch sampling strategy. The salient content of UHD images is detected and cropped to extract quality-aware features from the salient regions. We adopt the Swin Transformer Tiny as the backbone networks to extract features from these three perspectives. The extracted features are concatenated and regressed into quality scores by a two-layer multi-layer perceptron (MLP) network. We employ the mean square error (MSE) loss to optimize prediction accuracy and the fidelity loss to optimize prediction monotonicity. Experimental results show that the proposed model achieves the best performance on the UHD-IQA dataset while maintaining the lowest computational complexity, demonstrating its effectiveness and efficiency. Moreover, the proposed model won first prize in ECCV AIM 2024 UHD-IQA Challenge. The code is available at https://github.com/sunwei925/UIQA.
Read more9/4/2024

0
Descriptive Image Quality Assessment in the Wild
Zhiyuan You, Jinjin Gu, Zheyuan Li, Xin Cai, Kaiwen Zhu, Chao Dong, Tianfan Xue
With the rapid advancement of Vision Language Models (VLMs), VLM-based Image Quality Assessment (IQA) seeks to describe image quality linguistically to align with human expression and capture the multifaceted nature of IQA tasks. However, current methods are still far from practical usage. First, prior works focus narrowly on specific sub-tasks or settings, which do not align with diverse real-world applications. Second, their performance is sub-optimal due to limitations in dataset coverage, scale, and quality. To overcome these challenges, we introduce Depicted image Quality Assessment in the Wild (DepictQA-Wild). Our method includes a multi-functional IQA task paradigm that encompasses both assessment and comparison tasks, brief and detailed responses, full-reference and non-reference scenarios. We introduce a ground-truth-informed dataset construction approach to enhance data quality, and scale up the dataset to 495K under the brief-detail joint framework. Consequently, we construct a comprehensive, large-scale, and high-quality dataset, named DQ-495K. We also retain image resolution during training to better handle resolution-related quality issues, and estimate a confidence score that is helpful to filter out low-quality responses. Experimental results demonstrate that DepictQA-Wild significantly outperforms traditional score-based methods, prior VLM-based IQA models, and proprietary GPT-4V in distortion identification, instant rating, and reasoning tasks. Our advantages are further confirmed by real-world applications including assessing the web-downloaded images and ranking model-processed images. Datasets and codes will be released in https://depictqa.github.io/depictqa-wild/.
Read more6/13/2024