Joint stereo 3D object detection and implicit surface reconstruction

0
🔎
Sign in to get full access
Overview
- Presents a new learning-based framework called S-3D-RCNN that can recover accurate object orientation in 3D space (SO(3)) and simultaneously predict implicit rigid shapes from stereo RGB images.
- For orientation estimation, proposes a progressive approach that extracts meaningful Intermediate Geometrical Representations (IGRs) instead of mapping local appearance to observation angles.
- Investigates the implicit shape estimation problem from stereo images, modeling visible object surfaces using a point-based representation and augmenting IGRs to address the unseen surface hallucination problem.
- Extensive experiments validate the effectiveness of the proposed IGRs, and S-3D-RCNN achieves superior 3D scene understanding performance.
- Designed new metrics on the KITTI benchmark for evaluation of implicit shape estimation.
Plain English Explanation
The paper presents a new computer vision system called S-3D-RCNN that can accurately determine the 3D orientation of objects and also predict their basic 3D shape from stereo (two-camera) images. Previous methods have tried to directly map an object's appearance to its orientation, but this new approach first extracts more meaningful intermediate geometric representations (IGRs) that help the system better understand the object's 3D structure.
To also estimate the 3D shape of objects, the system uses a point-based representation to model the visible surfaces, and builds on the IGRs to hallucinate or infer the parts of the object that are not directly visible in the images. Through extensive testing, the researchers show that this combined approach to orientation and shape estimation outperforms previous methods and advances the state-of-the-art in 3D scene understanding.
The paper also introduces new evaluation metrics for assessing this type of implicit 3D shape estimation on the standard KITTI benchmark dataset.
Technical Explanation
S-3D-RCNN is a learning-based framework that tackles two key problems in 3D scene understanding from stereo RGB images: accurate object orientation estimation in 3D space (SO(3)) and implicit rigid shape prediction.
For orientation estimation, the system departs from previous methods that directly map local object appearance to observation angles. Instead, it proposes a progressive approach that first extracts meaningful Intermediate Geometrical Representations (IGRs). These IGRs transform the perceived object intensities from one or two views into part-level 3D coordinates, enabling direct egocentric orientation estimation in the camera coordinate system.
To also estimate the 3D shape of objects, the system models visible object surfaces using a point-based representation. It further augments the IGRs to explicitly address the challenge of hallucinating or inferring the unseen surfaces of the object. This allows the system to provide a more detailed 3D description within the 3D bounding boxes.
Extensive experiments on benchmark datasets validate the effectiveness of the proposed IGRs, and show that S-3D-RCNN achieves superior 3D scene understanding performance compared to previous methods. The researchers also designed new evaluation metrics on the KITTI benchmark to assess the implicit 3D shape estimation capabilities of the system.
Critical Analysis
The paper presents a comprehensive framework for 3D object orientation and shape estimation that advances the state-of-the-art. The key innovations, such as the use of Intermediate Geometrical Representations (IGRs) and the point-based shape modeling, are well-motivated and effectively demonstrated through extensive experiments.
However, the paper does not discuss the computational complexity or inference time of the S-3D-RCNN system, which could be an important practical consideration, especially for real-time applications. Additionally, the paper does not provide much insight into the failure cases or limitations of the approach, which would be helpful for understanding its robustness and potential areas for further improvement.
It would also be interesting to see how S-3D-RCNN compares to other recent advancements in 3D object reconstruction and implicit shape representation learning, as well as to methods that jointly tackle 2D and 3D scene understanding tasks, such as SSR-2D or ImageNet3D.
Overall, the paper presents a solid contribution to the field of 3D scene understanding, and the proposed S-3D-RCNN framework could have important implications for applications such as autonomous driving, robotics, and augmented reality.
Conclusion
The presented S-3D-RCNN framework advances the state-of-the-art in 3D object orientation estimation and implicit shape prediction from stereo RGB images. By introducing Intermediate Geometrical Representations (IGRs) and a point-based shape modeling approach, the system is able to accurately recover object orientation in 3D space and provide a more detailed 3D description of observed objects.
The extensive experiments validate the effectiveness of the proposed techniques, and the new evaluation metrics on the KITTI benchmark will help drive further progress in this important area of 3D scene understanding. While the paper does not explore all the potential limitations of the approach, it represents a significant step forward in enabling more comprehensive and robust 3D perception from stereo vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Joint stereo 3D object detection and implicit surface reconstruction
Shichao Li, Xijie Huang, Zechun Liu, Kwang-Ting Cheng
We present a new learning-based framework S-3D-RCNN that can recover accurate object orientation in SO(3) and simultaneously predict implicit rigid shapes from stereo RGB images. For orientation estimation, in contrast to previous studies that map local appearance to observation angles, we propose a progressive approach by extracting meaningful Intermediate Geometrical Representations (IGRs). This approach features a deep model that transforms perceived intensities from one or two views to object part coordinates to achieve direct egocentric object orientation estimation in the camera coordinate system. To further achieve finer description inside 3D bounding boxes, we investigate the implicit shape estimation problem from stereo images. We model visible object surfaces by designing a point-based representation, augmenting IGRs to explicitly address the unseen surface hallucination problem. Extensive experiments validate the effectiveness of the proposed IGRs, and S-3D-RCNN achieves superior 3D scene understanding performance. We also designed new metrics on the KITTI benchmark for our evaluation of implicit shape estimation.
Read more6/18/2024
🔍
0
Category-level Object Detection, Pose Estimation and Reconstruction from Stereo Images
Chuanrui Zhang, Yonggen Ling, Minglei Lu, Minghan Qin, Haoqian Wang
We study the 3D object understanding task for manipulating everyday objects with different material properties (diffuse, specular, transparent and mixed). Existing monocular and RGB-D methods suffer from scale ambiguity due to missing or imprecise depth measurements. We present CODERS, a one-stage approach for Category-level Object Detection, pose Estimation and Reconstruction from Stereo images. The base of our pipeline is an implicit stereo matching module that combines stereo image features with 3D position information. Concatenating this presented module and the following transform-decoder architecture leads to end-to-end learning of multiple tasks required by robot manipulation. Our approach significantly outperforms all competing methods in the public TOD dataset. Furthermore, trained on simulated data, CODERS generalize well to unseen category-level object instances in real-world robot manipulation experiments. Our dataset, code, and demos will be available on our project page.
Read more7/18/2024

0
General Geometry-aware Weakly Supervised 3D Object Detection
Guowen Zhang, Junsong Fan, Liyi Chen, Zhaoxiang Zhang, Zhen Lei, Lei Zhang
3D object detection is an indispensable component for scene understanding. However, the annotation of large-scale 3D datasets requires significant human effort. To tackle this problem, many methods adopt weakly supervised 3D object detection that estimates 3D boxes by leveraging 2D boxes and scene/class-specific priors. However, these approaches generally depend on sophisticated manual priors, which is hard to generalize to novel categories and scenes. In this paper, we are motivated to propose a general approach, which can be easily adapted to new scenes and/or classes. A unified framework is developed for learning 3D object detectors from RGB images and associated 2D boxes. In specific, we propose three general components: prior injection module to obtain general object geometric priors from LLM model, 2D space projection constraint to minimize the discrepancy between the boundaries of projected 3D boxes and their corresponding 2D boxes on the image plane, and 3D space geometry constraint to build a Point-to-Box alignment loss to further refine the pose of estimated 3D boxes. Experiments on KITTI and SUN-RGBD datasets demonstrate that our method yields surprisingly high-quality 3D bounding boxes with only 2D annotation. The source code is available at https://github.com/gwenzhang/GGA.
Read more7/19/2024
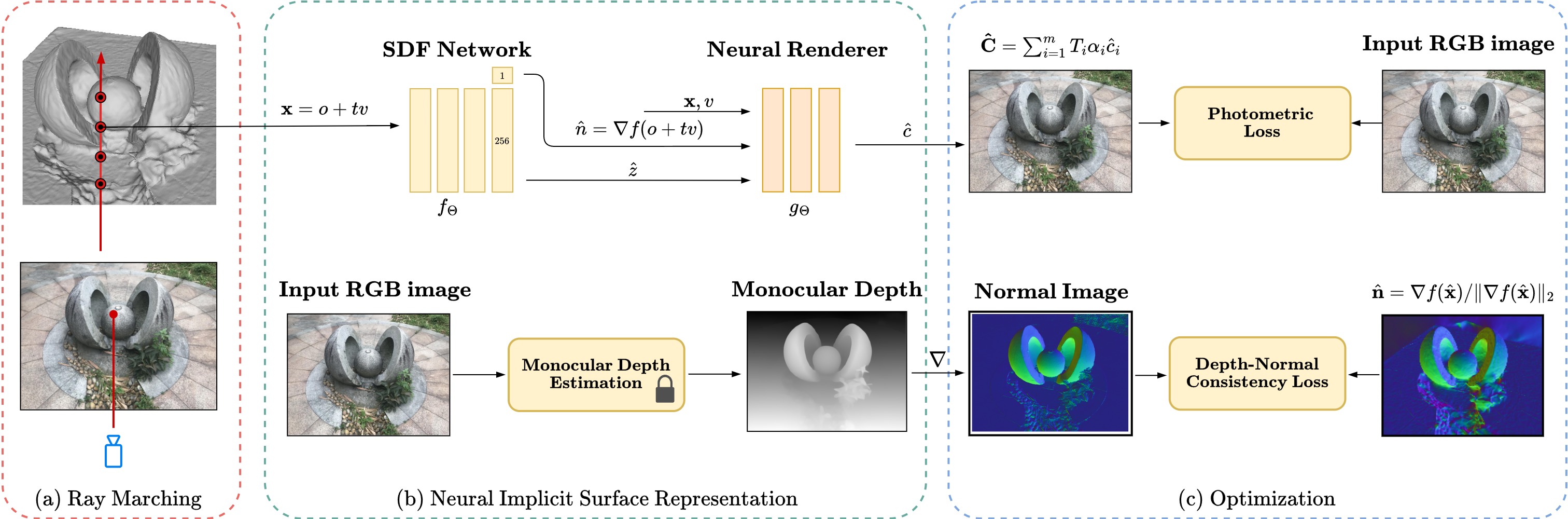
0
Normal-guided Detail-Preserving Neural Implicit Functions for High-Fidelity 3D Surface Reconstruction
Aarya Patel, Hamid Laga, Ojaswa Sharma
Neural implicit representations have emerged as a powerful paradigm for 3D reconstruction. However, despite their success, existing methods fail to capture fine geometric details and thin structures, especially in scenarios where only sparse RGB views of the objects of interest are available. We hypothesize that current methods for learning neural implicit representations from RGB or RGBD images produce 3D surfaces with missing parts and details because they only rely on 0-order differential properties, i.e. the 3D surface points and their projections, as supervisory signals. Such properties, however, do not capture the local 3D geometry around the points and also ignore the interactions between points. This paper demonstrates that training neural representations with first-order differential properties, i.e. surface normals, leads to highly accurate 3D surface reconstruction even in situations where only as few as two RGB (front and back) images are available. Given multiview RGB images of an object of interest, we first compute the approximate surface normals in the image space using the gradient of the depth maps produced using an off-the-shelf monocular depth estimator such as Depth Anything model. An implicit surface regressor is then trained using a loss function that enforces the first-order differential properties of the regressed surface to match those estimated from Depth Anything. Our extensive experiments on a wide range of real and synthetic datasets show that the proposed method achieves an unprecedented level of reconstruction accuracy even when using as few as two RGB views. The detailed ablation study also demonstrates that normal-based supervision plays a key role in this significant improvement in performance, enabling the 3D reconstruction of intricate geometric details and thin structures that were previously challenging to capture.
Read more6/10/2024