Just How Flexible are Neural Networks in Practice?

0
Sign in to get full access
Overview
- This paper investigates the practical flexibility of neural networks, exploring how well they can adapt to different functions and tasks.
- The authors examine several aspects of neural network flexibility, including their ability to calibrate parameters, model non-parametric functions, approximate gradient descent training, improve generalization, and adapt to different functions.
Plain English Explanation
Neural networks are a type of machine learning model inspired by the structure of the human brain. They are known for their ability to learn complex patterns in data and adapt to different tasks. However, the true extent of their flexibility in practice is not fully understood.
This paper explores how well neural networks can adapt to various functions and challenges. The researchers investigate several key aspects of neural network flexibility, including their ability to fine-tune their internal parameters, model non-linear relationships, approximate complex training algorithms, improve their performance on new data, and adapt to different types of functions.
Through a series of experiments and analyses, the authors shed light on the practical limits and capabilities of neural networks. Their findings provide valuable insights into the strengths and weaknesses of these powerful machine learning models, which have become ubiquitous in modern artificial intelligence systems.
Technical Explanation
The paper delves into several technical aspects of neural network flexibility:
-
[object Object]: The authors examine the ability of neural networks to optimize their internal parameters through a process called "optimal contraction," which allows the model to fine-tune its performance on specific tasks.
-
[object Object]: The researchers investigate how well neural networks can model non-linear, non-parametric functions, which are complex relationships that cannot be easily captured by traditional statistical models.
-
[object Object]: The paper examines the ability of neural networks to approximate the gradient descent training algorithm, which is a fundamental method used to optimize the model's parameters.
-
[object Object]: The authors explore techniques for improving the generalization performance of neural networks, which is their ability to perform well on new, unseen data.
-
[object Object]: Finally, the paper investigates the overall adaptability of neural networks to different types of functions, assessing their flexibility in handling a wide range of tasks and data.
Through these technical investigations, the researchers aim to provide a comprehensive understanding of the practical flexibility and limitations of neural networks, which have become widely used in various domains, from image recognition to natural language processing.
Critical Analysis
The paper provides a thorough and rigorous analysis of neural network flexibility, exploring several key aspects of their capabilities. However, the authors acknowledge certain caveats and limitations to their work:
-
The experiments are conducted on relatively simple, synthetic datasets, which may not fully capture the complexity of real-world problems. Further research is needed to validate the findings on more realistic and challenging tasks.
-
The analysis focuses on shallow, fully-connected neural networks, which may not fully represent the diversity of neural network architectures used in practice, such as convolutional or recurrent networks.
-
The paper does not address the impact of hyperparameter tuning, regularization techniques, or other advanced training methods, which can significantly influence the flexibility and generalization performance of neural networks.
Additionally, while the paper provides a comprehensive technical examination, it could benefit from a more in-depth discussion of the broader implications and potential societal impacts of neural network flexibility. As these models become increasingly integrated into decision-making systems, it is essential to consider their limitations and potential biases.
Conclusion
This paper offers a valuable contribution to the understanding of neural network flexibility by systematically investigating several key aspects of their adaptability. The findings suggest that neural networks possess a high degree of flexibility, allowing them to calibrate parameters, model non-parametric functions, approximate complex training algorithms, improve generalization, and adapt to diverse types of functions.
These insights have important implications for the continued development and application of neural networks in various domains, from scientific research to real-world problem-solving. As the field of artificial intelligence continues to rapidly evolve, a deeper understanding of the practical capabilities and limitations of neural networks will be crucial in shaping the responsible and ethical use of these powerful machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Just How Flexible are Neural Networks in Practice?
Ravid Shwartz-Ziv, Micah Goldblum, Arpit Bansal, C. Bayan Bruss, Yann LeCun, Andrew Gordon Wilson
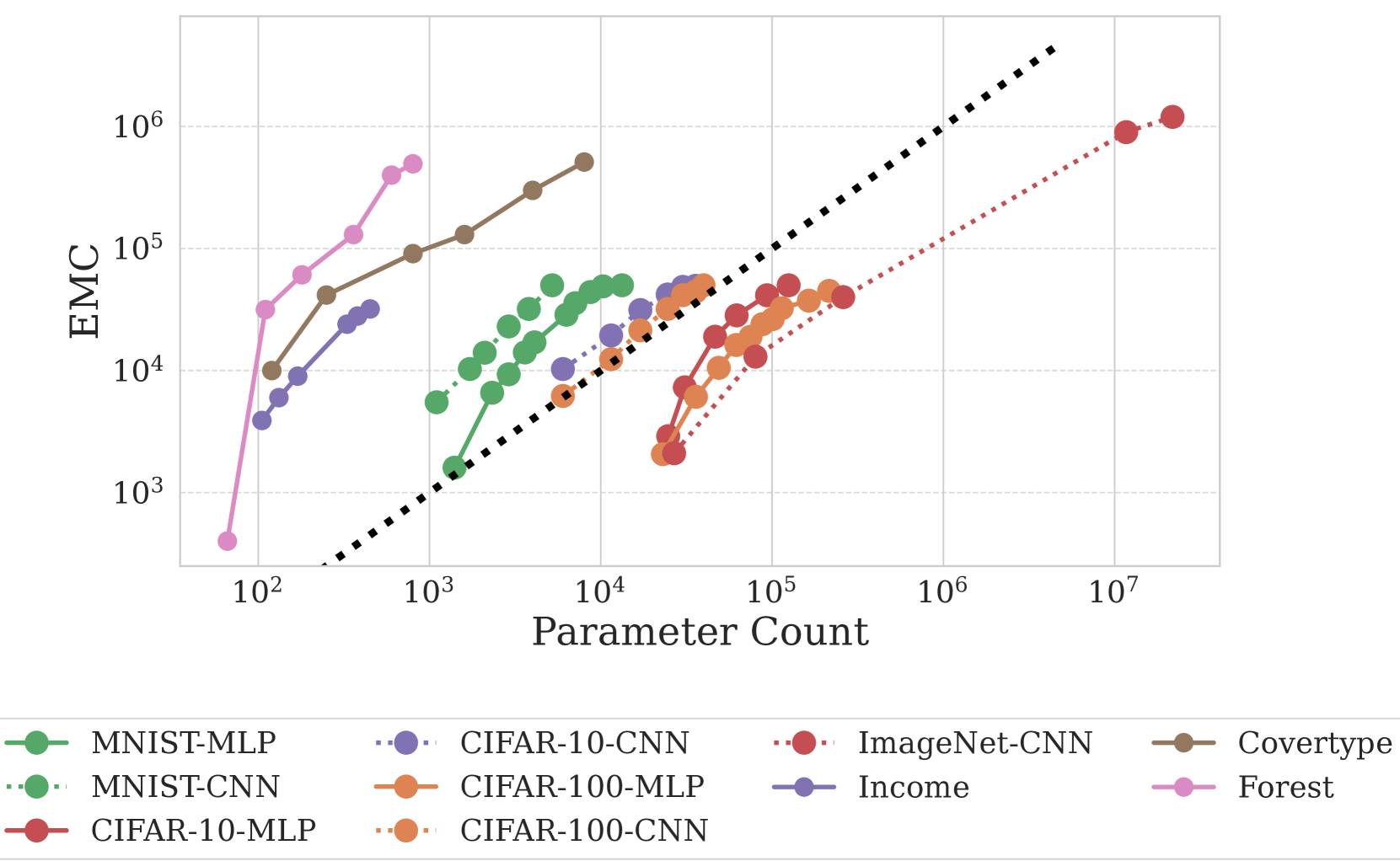
It is widely believed that a neural network can fit a training set containing at least as many samples as it has parameters, underpinning notions of overparameterized and underparameterized models. In practice, however, we only find solutions accessible via our training procedure, including the optimizer and regularizers, limiting flexibility. Moreover, the exact parameterization of the function class, built into an architecture, shapes its loss surface and impacts the minima we find. In this work, we examine the ability of neural networks to fit data in practice. Our findings indicate that: (1) standard optimizers find minima where the model can only fit training sets with significantly fewer samples than it has parameters; (2) convolutional networks are more parameter-efficient than MLPs and ViTs, even on randomly labeled data; (3) while stochastic training is thought to have a regularizing effect, SGD actually finds minima that fit more training data than full-batch gradient descent; (4) the difference in capacity to fit correctly labeled and incorrectly labeled samples can be predictive of generalization; (5) ReLU activation functions result in finding minima that fit more data despite being designed to avoid vanishing and exploding gradients in deep architectures.
Read more6/18/2024

0
The Unreasonable Effectiveness of Solving Inverse Problems with Neural Networks
Philipp Holl, Nils Thuerey
Finding model parameters from data is an essential task in science and engineering, from weather and climate forecasts to plasma control. Previous works have employed neural networks to greatly accelerate finding solutions to inverse problems. Of particular interest are end-to-end models which utilize differentiable simulations in order to backpropagate feedback from the simulated process to the network weights and enable roll-out of multiple time steps. So far, it has been assumed that, while model inference is faster than classical optimization, this comes at the cost of a decrease in solution accuracy. We show that this is generally not true. In fact, neural networks trained to learn solutions to inverse problems can find better solutions than classical optimizers even on their training set. To demonstrate this, we perform both a theoretical analysis as well an extensive empirical evaluation on challenging problems involving local minima, chaos, and zero-gradient regions. Our findings suggest an alternative use for neural networks: rather than generalizing to new data for fast inference, they can also be used to find better solutions on known data.
Read more8/16/2024

0
How Can Deep Neural Networks Fail Even With Global Optima?
Qingguang Guan
Fully connected deep neural networks are successfully applied to classification and function approximation problems. By minimizing the cost function, i.e., finding the proper weights and biases, models can be built for accurate predictions. The ideal optimization process can achieve global optima. However, do global optima always perform well? If not, how bad can it be? In this work, we aim to: 1) extend the expressive power of shallow neural networks to networks of any depth using a simple trick, 2) construct extremely overfitting deep neural networks that, despite having global optima, still fail to perform well on classification and function approximation problems. Different types of activation functions are considered, including ReLU, Parametric ReLU, and Sigmoid functions. Extensive theoretical analysis has been conducted, ranging from one-dimensional models to models of any dimensionality. Numerical results illustrate our theoretical findings.
Read more7/25/2024
0
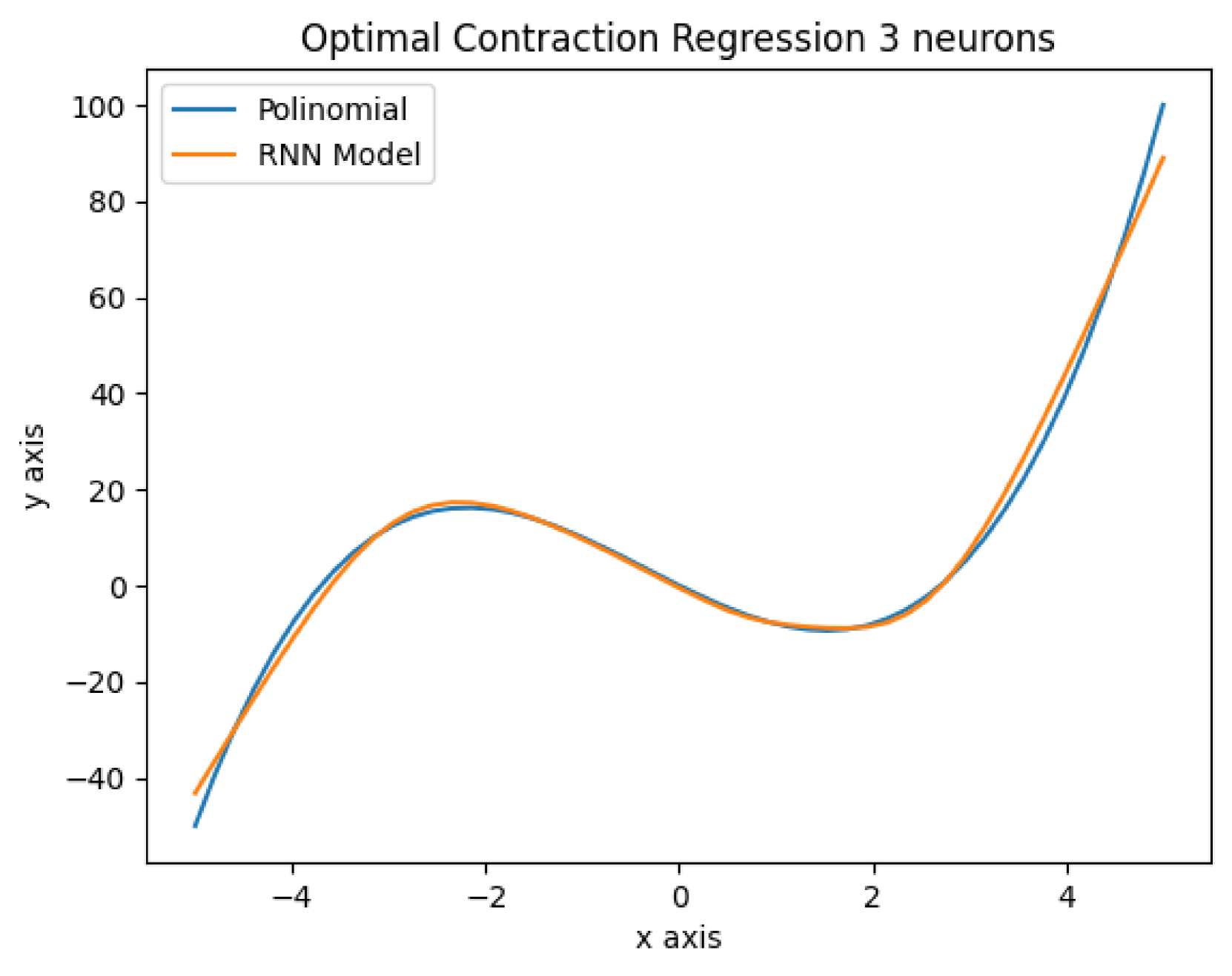
Calibrating Neural Networks' parameters through Optimal Contraction in a Prediction Problem
Valdes Gonzalo
This study introduces a novel approach to ensure the existence and uniqueness of optimal parameters in neural networks. The paper details how a recurrent neural networks (RNN) can be transformed into a contraction in a domain where its parameters are linear. It then demonstrates that a prediction problem modeled through an RNN, with a specific regularization term in the loss function, can have its first-order conditions expressed analytically. This system of equations is reduced to two matrix equations involving Sylvester equations, which can be partially solved. We establish that, if certain conditions are met, optimal parameters exist, are unique, and can be found through a straightforward algorithm to any desired precision. Also, as the number of neurons grows the conditions of convergence become easier to fulfill. Feedforward neural networks (FNNs) are also explored by including linear constraints on parameters. According to our model, incorporating loops (with fixed or variable weights) will produce loss functions that train easier, because it assures the existence of a region where an iterative method converges.
Read more6/21/2024