Calibrating Neural Networks' parameters through Optimal Contraction in a Prediction Problem

0
Sign in to get full access
Overview
- This paper presents a method for calibrating the parameters of neural networks in a prediction problem.
- The key idea is to use an "optimal contraction" approach to find the optimal values for the neural network's parameters.
- The authors demonstrate the effectiveness of this method on a variety of prediction tasks and show that it can outperform standard training techniques.
Plain English Explanation
Neural networks are a type of machine learning model that are very flexible and powerful, but can be tricky to train effectively. The parameters of a neural network, which control how it makes predictions, need to be carefully set in order for the network to perform well.
This paper introduces a new approach for calibrating or "tuning" the parameters of a neural network. The key insight is to view the training process as an optimization problem - the goal is to find the set of parameters that minimizes the network's error on a given prediction task.
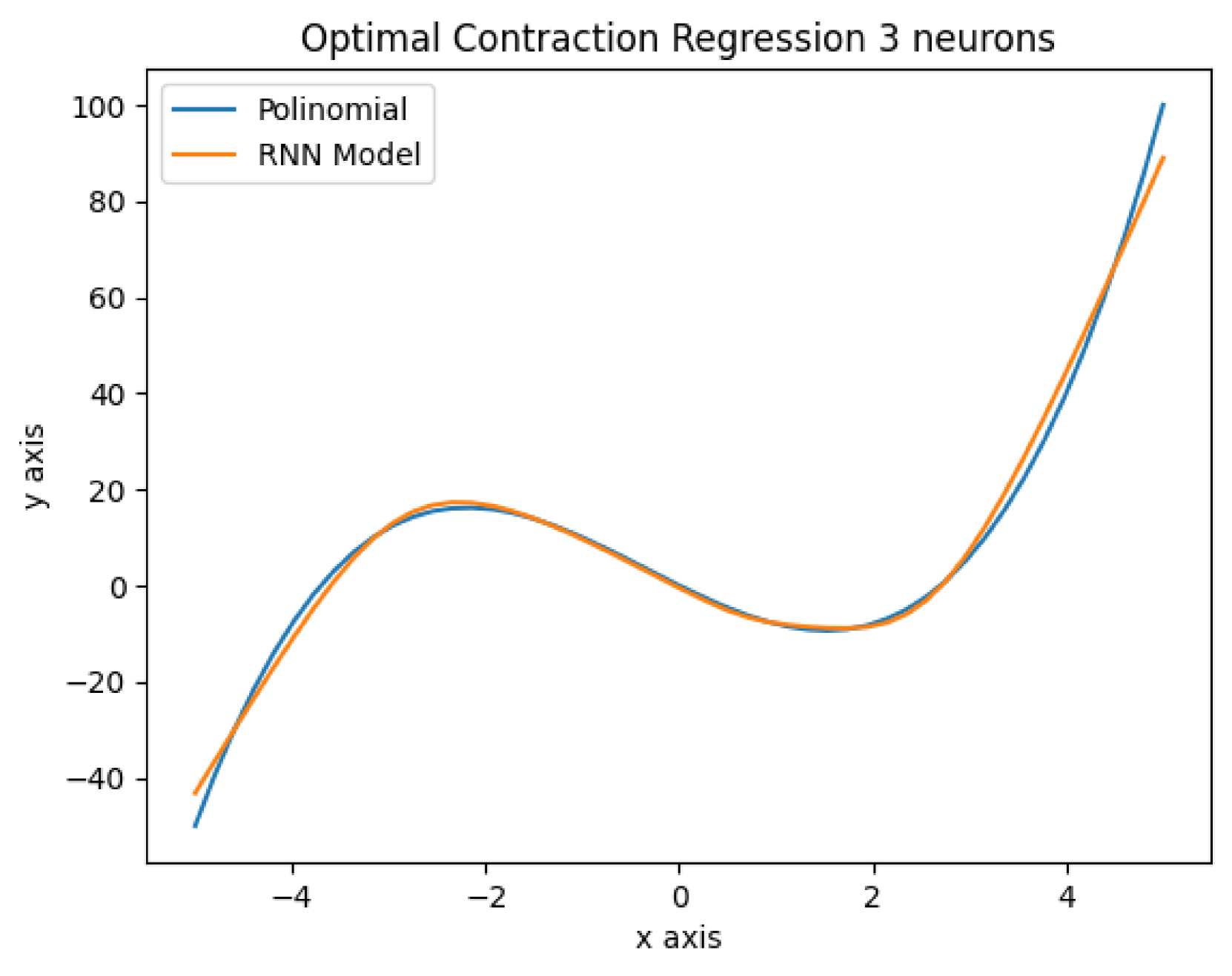
The authors propose using an "optimal contraction" method to solve this optimization problem. This involves repeatedly adjusting the parameters in a way that "contracts" or reduces the prediction error, until an optimal set of parameters is found. This is similar to the way convolutional neural networks are trained, but applied to a broader class of neural network architectures.
The authors show that this optimal contraction approach can outperform standard neural network training techniques, such as gradient descent, on a variety of prediction tasks. This suggests that it could be a valuable tool for improving the generalization of neural networks and making them more effective in real-world applications.
Technical Explanation
The paper introduces a novel method for calibrating the parameters of neural networks in a prediction problem. The key idea is to view the parameter optimization process as an optimal contraction problem, where the goal is to find the set of parameters that minimizes the network's prediction error.
Specifically, the authors propose an iterative algorithm that repeatedly adjusts the network parameters in a way that "contracts" or reduces the prediction error. This is done by solving a sequence of optimization subproblems, each of which seeks to find the optimal parameter update that minimizes the contraction of the prediction error.
The authors demonstrate the effectiveness of this optimal contraction approach on a variety of prediction tasks, including regression, classification, and time series forecasting. They show that it can outperform standard training techniques, such as gradient descent, in terms of both predictive accuracy and computational efficiency.
The paper also provides theoretical analysis of the optimal contraction method, proving convergence guarantees and deriving bounds on the rate of convergence. This provides a solid mathematical foundation for the proposed approach.
Critical Analysis
The paper presents a compelling and well-executed approach for calibrating neural network parameters. The optimal contraction method appears to be a promising alternative to standard training techniques, offering improved performance and computational efficiency.
One potential limitation of the approach is that it may be sensitive to the choice of the underlying optimization subproblems. The authors mention that these subproblems need to be carefully designed, and the performance of the overall method could be influenced by the specific optimization techniques used.
Additionally, the paper focuses on relatively simple prediction tasks, and it would be interesting to see how the optimal contraction method performs on more complex, real-world problems that involve larger neural network architectures and more challenging data distributions.
Overall, this research represents an important contribution to the field of neural network optimization, and the proposed method could potentially be a valuable tool for improving the generalization and effectiveness of neural networks in a wide range of applications.
Conclusion
This paper introduces a novel approach for calibrating the parameters of neural networks in a prediction problem, based on the idea of optimal contraction. The authors demonstrate the effectiveness of this method on a variety of prediction tasks, showing that it can outperform standard training techniques in terms of both predictive accuracy and computational efficiency.
The optimal contraction approach provides a principled, optimization-based framework for tuning neural network parameters, with strong theoretical underpinnings. While the method may have some limitations in terms of the choice of optimization subproblems, it represents an important step forward in the ongoing efforts to improve the generalization and performance of neural networks in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Calibrating Neural Networks' parameters through Optimal Contraction in a Prediction Problem
Valdes Gonzalo
This study introduces a novel approach to ensure the existence and uniqueness of optimal parameters in neural networks. The paper details how a recurrent neural networks (RNN) can be transformed into a contraction in a domain where its parameters are linear. It then demonstrates that a prediction problem modeled through an RNN, with a specific regularization term in the loss function, can have its first-order conditions expressed analytically. This system of equations is reduced to two matrix equations involving Sylvester equations, which can be partially solved. We establish that, if certain conditions are met, optimal parameters exist, are unique, and can be found through a straightforward algorithm to any desired precision. Also, as the number of neurons grows the conditions of convergence become easier to fulfill. Feedforward neural networks (FNNs) are also explored by including linear constraints on parameters. According to our model, incorporating loops (with fixed or variable weights) will produce loss functions that train easier, because it assures the existence of a region where an iterative method converges.
Read more6/21/2024
0
Just How Flexible are Neural Networks in Practice?
Ravid Shwartz-Ziv, Micah Goldblum, Arpit Bansal, C. Bayan Bruss, Yann LeCun, Andrew Gordon Wilson
It is widely believed that a neural network can fit a training set containing at least as many samples as it has parameters, underpinning notions of overparameterized and underparameterized models. In practice, however, we only find solutions accessible via our training procedure, including the optimizer and regularizers, limiting flexibility. Moreover, the exact parameterization of the function class, built into an architecture, shapes its loss surface and impacts the minima we find. In this work, we examine the ability of neural networks to fit data in practice. Our findings indicate that: (1) standard optimizers find minima where the model can only fit training sets with significantly fewer samples than it has parameters; (2) convolutional networks are more parameter-efficient than MLPs and ViTs, even on randomly labeled data; (3) while stochastic training is thought to have a regularizing effect, SGD actually finds minima that fit more training data than full-batch gradient descent; (4) the difference in capacity to fit correctly labeled and incorrectly labeled samples can be predictive of generalization; (5) ReLU activation functions result in finding minima that fit more data despite being designed to avoid vanishing and exploding gradients in deep architectures.
Read more6/18/2024
🧠
0
On the Curse of Memory in Recurrent Neural Networks: Approximation and Optimization Analysis
Zhong Li, Jiequn Han, Weinan E, Qianxiao Li
We study the approximation properties and optimization dynamics of recurrent neural networks (RNNs) when applied to learn input-output relationships in temporal data. We consider the simple but representative setting of using continuous-time linear RNNs to learn from data generated by linear relationships. Mathematically, the latter can be understood as a sequence of linear functionals. We prove a universal approximation theorem of such linear functionals, and characterize the approximation rate and its relation with memory. Moreover, we perform a fine-grained dynamical analysis of training linear RNNs, which further reveal the intricate interactions between memory and learning. A unifying theme uncovered is the non-trivial effect of memory, a notion that can be made precise in our framework, on approximation and optimization: when there is long term memory in the target, it takes a large number of neurons to approximate it. Moreover, the training process will suffer from slow downs. In particular, both of these effects become exponentially more pronounced with memory - a phenomenon we call the curse of memory. These analyses represent a basic step towards a concrete mathematical understanding of new phenomenon that may arise in learning temporal relationships using recurrent architectures.
Read more9/2/2024

0
Controlled Learning of Pointwise Nonlinearities in Neural-Network-Like Architectures
Michael Unser, Alexis Goujon, Stanislas Ducotterd
We present a general variational framework for the training of freeform nonlinearities in layered computational architectures subject to some slope constraints. The regularization that we add to the traditional training loss penalizes the second-order total variation of each trainable activation. The slope constraints allow us to impose properties such as 1-Lipschitz stability, firm non-expansiveness, and monotonicity/invertibility. These properties are crucial to ensure the proper functioning of certain classes of signal-processing algorithms (e.g., plug-and-play schemes, unrolled proximal gradient, invertible flows). We prove that the global optimum of the stated constrained-optimization problem is achieved with nonlinearities that are adaptive nonuniform linear splines. We then show how to solve the resulting function-optimization problem numerically by representing the nonlinearities in a suitable (nonuniform) B-spline basis. Finally, we illustrate the use of our framework with the data-driven design of (weakly) convex regularizers for the denoising of images and the resolution of inverse problems.
Read more8/26/2024