KazParC: Kazakh Parallel Corpus for Machine Translation
2403.19399
0
0
📉
Abstract
We introduce KazParC, a parallel corpus designed for machine translation across Kazakh, English, Russian, and Turkish. The first and largest publicly available corpus of its kind, KazParC contains a collection of 371,902 parallel sentences covering different domains and developed with the assistance of human translators. Our research efforts also extend to the development of a neural machine translation model nicknamed Tilmash. Remarkably, the performance of Tilmash is on par with, and in certain instances, surpasses that of industry giants, such as Google Translate and Yandex Translate, as measured by standard evaluation metrics, such as BLEU and chrF. Both KazParC and Tilmash are openly available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
Create account to get full access
Overview
- This paper introduces KazParC, a new parallel corpus for Kazakh-English machine translation.
- The corpus contains over 600,000 sentence pairs collected from various online sources.
- The authors describe the process of developing the corpus, including data collection, cleaning, and preprocessing.
- Experiments show the corpus can improve performance on Kazakh-English translation tasks compared to existing resources.
Plain English Explanation
KazParC is a new dataset for training machine translation models between Kazakh and English. Machine translation is the process of automatically translating text from one language to another. Building high-quality translation models requires large datasets of parallel text, where the same content is available in both languages.
The researchers behind KazParC collected over 600,000 Kazakh-English sentence pairs from various online sources, such as websites and databases. They then cleaned and preprocessed the data to ensure it was of high quality and suitable for training machine learning models.
By evaluating the performance of translation models trained on KazParC, the researchers demonstrated that this new corpus can lead to better Kazakh-English translation results compared to using other available datasets. This is an important contribution, as high-quality translation is crucial for enabling communication and information exchange between speakers of these two languages.
Technical Explanation
The paper describes the development of KazParC, a large-scale parallel corpus for Kazakh-English machine translation. The corpus contains 625,584 sentence pairs collected from a variety of online sources, including government websites, news articles, and user-generated content.
To build the corpus, the authors first identified relevant Kazakh and English content online. They then applied language identification, sentence alignment, and data cleaning techniques to extract high-quality parallel sentences. This involved removing noisy or low-quality data, normalizing text, and handling formatting issues.
The authors also conducted experiments to assess the quality and usefulness of the KazParC corpus. They trained neural machine translation models on KazParC and compared the results to models trained on other available Kazakh-English datasets. The experiments showed that KazParC led to improved translation performance, indicating its value as a resource for developing Kazakh-English translation systems.
Critical Analysis
The paper provides a thorough description of the KazParC corpus development process and demonstrates its utility through translation experiments. However, the authors acknowledge several limitations and areas for future work.
One key limitation is the potential bias in the data sources, as the corpus is primarily composed of text from online sources rather than a more balanced representation of real-world language use. The authors note that extending the corpus with content from additional domains, such as literature and specialized technical materials, could help address this issue.
Additionally, the paper does not provide a detailed error analysis of the translation results, which could offer insights into the specific strengths and weaknesses of the KazParC corpus. Such an analysis could guide future efforts to further improve the corpus and the underlying translation models.
Finally, the authors suggest that extending KazParC to include other language pairs, such as Kazakh-Russian, would be a valuable direction for future research. This could help establish KazParC as a more comprehensive resource for multilingual language processing in the region.
Conclusion
The KazParC corpus represents an important contribution to the field of machine translation, providing a high-quality dataset for developing Kazakh-English translation systems. By making this corpus publicly available, the researchers have opened up new possibilities for advancing Kazakh language technology and enabling better cross-lingual communication. As the authors have highlighted, continued efforts to expand and refine KazParC could further enhance its impact and utility for the research community and broader society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
A Japanese-Chinese Parallel Corpus Using Crowdsourcing for Web Mining
Masaaki Nagata, Makoto Morishita, Katsuki Chousa, Norihito Yasuda
0
0
Using crowdsourcing, we collected more than 10,000 URL pairs (parallel top page pairs) of bilingual websites that contain parallel documents and created a Japanese-Chinese parallel corpus of 4.6M sentence pairs from these websites. We used a Japanese-Chinese bilingual dictionary of 160K word pairs for document and sentence alignment. We then used high-quality 1.2M Japanese-Chinese sentence pairs to train a parallel corpus filter based on statistical language models and word translation probabilities. We compared the translation accuracy of the model trained on these 4.6M sentence pairs with that of the model trained on Japanese-Chinese sentence pairs from CCMatrix (12.4M), a parallel corpus from global web mining. Although our corpus is only one-third the size of CCMatrix, we found that the accuracy of the two models was comparable and confirmed that it is feasible to use crowdsourcing for web mining of parallel data.
5/16/2024
💬
Investigating the translation capabilities of Large Language Models trained on parallel data only
Javier Garc'ia Gilabert, Carlos Escolano, Aleix Sant Savall, Francesca De Luca Fornaciari, Audrey Mash, Xixian Liao, Maite Melero
0
0
In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
6/14/2024
Feriji: A French-Zarma Parallel Corpus, Glossary & Translator
Mamadou K. Keita, Elysabhete Amadou Ibrahim, Habibatou Abdoulaye Alfari, Christopher Homan
0
0
Machine translation (MT) is a rapidly expanding field that has experienced significant advancements in recent years with the development of models capable of translating multiple languages with remarkable accuracy. However, the representation of African languages in this field still needs to improve due to linguistic complexities and limited resources. This applies to the Zarma language, a dialect of Songhay (of the Nilo-Saharan language family) spoken by over 5 million people across Niger and neighboring countries cite{lewis2016ethnologue}. This paper introduces Feriji, the first robust French-Zarma parallel corpus and glossary designed for MT. The corpus, containing 61,085 sentences in Zarma and 42,789 in French, and a glossary of 4,062 words represent a significant step in addressing the need for more resources for Zarma. We fine-tune three large language models on our dataset, obtaining a BLEU score of 30.06 on the best-performing model. We further evaluate the models on human judgments of fluency, comprehension, and readability and the importance and impact of the corpus and models. Our contributions help to bridge a significant language gap and promote an essential and overlooked indigenous African language.
6/19/2024
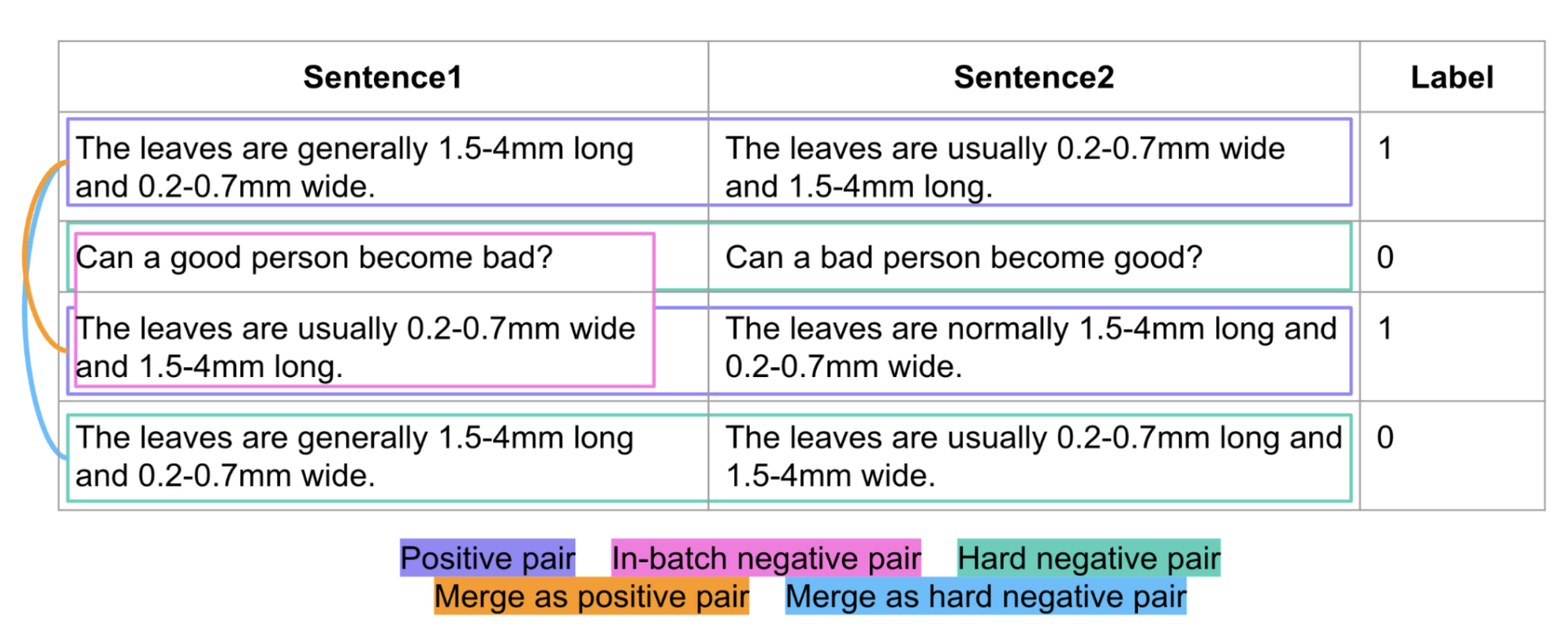
Cross-lingual paraphrase identification
Inessa Fedorova, Aleksei Musatow
0
0
The paraphrase identification task involves measuring semantic similarity between two short sentences. It is a tricky task, and multilingual paraphrase identification is even more challenging. In this work, we train a bi-encoder model in a contrastive manner to detect hard paraphrases across multiple languages. This approach allows us to use model-produced embeddings for various tasks, such as semantic search. We evaluate our model on downstream tasks and also assess embedding space quality. Our performance is comparable to state-of-the-art cross-encoders, with only a minimal relative drop of 7-10% on the chosen dataset, while keeping decent quality of embeddings.
6/24/2024