Feriji: A French-Zarma Parallel Corpus, Glossary & Translator
2406.05888
0
0
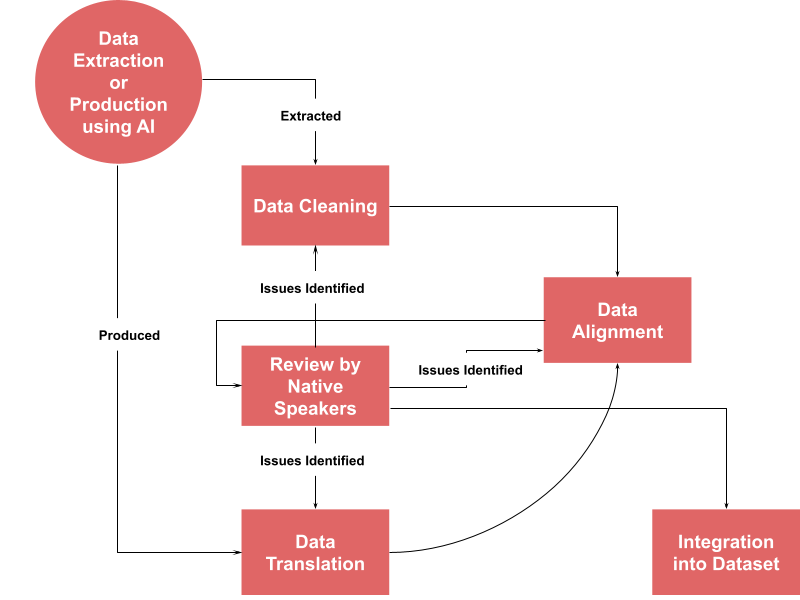
Abstract
Machine translation (MT) is a rapidly expanding field that has experienced significant advancements in recent years with the development of models capable of translating multiple languages with remarkable accuracy. However, the representation of African languages in this field still needs to improve due to linguistic complexities and limited resources. This applies to the Zarma language, a dialect of Songhay (of the Nilo-Saharan language family) spoken by over 5 million people across Niger and neighboring countries cite{lewis2016ethnologue}. This paper introduces Feriji, the first robust French-Zarma parallel corpus and glossary designed for MT. The corpus, containing 61,085 sentences in Zarma and 42,789 in French, and a glossary of 4,062 words represent a significant step in addressing the need for more resources for Zarma. We fine-tune three large language models on our dataset, obtaining a BLEU score of 30.06 on the best-performing model. We further evaluate the models on human judgments of fluency, comprehension, and readability and the importance and impact of the corpus and models. Our contributions help to bridge a significant language gap and promote an essential and overlooked indigenous African language.
Create account to get full access
Overview
- This paper presents Feriji, a French-Zarma parallel corpus, glossary, and machine translation system.
- Zarma is a language spoken in West Africa, particularly in Niger.
- The corpus, glossary, and translation model were developed to improve language resources and machine translation capabilities for the Zarma language.
Plain English Explanation
The researchers created a collection of French and Zarma text that are translations of each other, known as a parallel corpus. They also developed a glossary that maps words between the two languages, and a machine translation system that can convert text from French to Zarma and vice versa.
This work is significant because Zarma is a low-resource language, meaning there are limited digital language resources available compared to major global languages like English or French. By building this French-Zarma parallel corpus, glossary, and translation model, the researchers aim to improve the ability to process and translate content in the Zarma language, which could benefit speakers of Zarma and enable more digital content in their native language.
Technical Explanation
The Feriji corpus contains over 30,000 parallel sentence pairs in French and Zarma, collected from various sources including government documents, news articles, and educational materials. The researchers developed a glossary mapping over 20,000 French and Zarma word pairs to enable lexical translation. They then trained a neural machine translation model on the parallel corpus to translate between the two languages.
The model architecture and training process are described in detail in the paper. Evaluations on held-out test data show the model achieves strong performance on standard translation metrics like BLEU score, demonstrating the effectiveness of the Feriji resources for French-Zarma machine translation.
Critical Analysis
The paper acknowledges several limitations of the work, such as the potential for domain mismatch between the training and test data, and the need for further expansion of the corpus size and coverage. The authors also note that human evaluation of the translation quality could provide additional insight beyond automatic metrics.
One potential issue not addressed is the demographic representation within the Zarma language data. It's unclear if the corpus draws from a diverse range of Zarma speakers and dialects, or if there are any biases in the sources. Ensuring broad linguistic coverage is important for developing equitable language technologies.
Overall, the Feriji resources represent an important step forward for supporting the Zarma language in the digital space. Further research could explore ways to iteratively grow the corpus, integrate it with other Zarma NLP tools, and deploy the translation system for real-world applications.
Conclusion
This paper introduces the Feriji French-Zarma parallel corpus, glossary, and machine translation system, which aim to improve language resources and translation capabilities for the Zarma language. By developing these tools, the researchers hope to enable more digital content and services in Zarma, benefiting speakers of this low-resource language in West Africa. The technical work demonstrates the effectiveness of the Feriji resources, while also highlighting areas for future research and development to further advance Zarma language technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Krey`ol-MT: Building MT for Latin American, Caribbean and Colonial African Creole Languages
Nathaniel R. Robinson, Raj Dabre, Ammon Shurtz, Rasul Dent, Onenamiyi Onesi, Claire Bizon Monroc, Loic Grobol, Hasan Muhammad, Ashi Garg, Naome A. Etori, Vijay Murari Tiyyala, Olanrewaju Samuel, Matthew Dean Stutzman, Bismarck Bamfo Odoom, Sanjeev Khudanpur, Stephen D. Richardson, Kenton Murray
0
0
A majority of language technologies are tailored for a small number of high-resource languages, while relatively many low-resource languages are neglected. One such group, Creole languages, have long been marginalized in academic study, though their speakers could benefit from machine translation (MT). These languages are predominantly used in much of Latin America, Africa and the Caribbean. We present the largest cumulative dataset to date for Creole language MT, including 14.5M unique Creole sentences with parallel translations -- 11.6M of which we release publicly, and the largest bitexts gathered to date for 41 languages -- the first ever for 21. In addition, we provide MT models supporting all 41 Creole languages in 172 translation directions. Given our diverse dataset, we produce a model for Creole language MT exposed to more genre diversity than ever before, which outperforms a genre-specific Creole MT model on its own benchmark for 26 of 34 translation directions.
5/14/2024
📉
KazParC: Kazakh Parallel Corpus for Machine Translation
Rustem Yeshpanov, Alina Polonskaya, Huseyin Atakan Varol
0
0
We introduce KazParC, a parallel corpus designed for machine translation across Kazakh, English, Russian, and Turkish. The first and largest publicly available corpus of its kind, KazParC contains a collection of 371,902 parallel sentences covering different domains and developed with the assistance of human translators. Our research efforts also extend to the development of a neural machine translation model nicknamed Tilmash. Remarkably, the performance of Tilmash is on par with, and in certain instances, surpasses that of industry giants, such as Google Translate and Yandex Translate, as measured by standard evaluation metrics, such as BLEU and chrF. Both KazParC and Tilmash are openly available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
4/11/2024
💬
Machine Translation for Ge'ez Language
Aman Kassahun Wassie
0
0
Machine translation (MT) for low-resource languages such as Ge'ez, an ancient language that is no longer the native language of any community, faces challenges such as out-of-vocabulary words, domain mismatches, and lack of sufficient labeled training data. In this work, we explore various methods to improve Ge'ez MT, including transfer-learning from related languages, optimizing shared vocabulary and token segmentation approaches, finetuning large pre-trained models, and using large language models (LLMs) for few-shot translation with fuzzy matches. We develop a multilingual neural machine translation (MNMT) model based on languages relatedness, which brings an average performance improvement of about 4 BLEU compared to standard bilingual models. We also attempt to finetune the NLLB-200 model, one of the most advanced translation models available today, but find that it performs poorly with only 4k training samples for Ge'ez. Furthermore, we experiment with using GPT-3.5, a state-of-the-art LLM, for few-shot translation with fuzzy matches, which leverages embedding similarity-based retrieval to find context examples from a parallel corpus. We observe that GPT-3.5 achieves a remarkable BLEU score of 9.2 with no initial knowledge of Ge'ez, but still lower than the MNMT baseline of 15.2. Our work provides insights into the potential and limitations of different approaches for low-resource and ancient language MT.
4/16/2024
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
David Ifeoluwa Adelani, Jessica Ojo, Israel Abebe Azime, Jian Yun Zhuang, Jesujoba O. Alabi, Xuanli He, Millicent Ochieng, Sara Hooker, Andiswa Bukula, En-Shiun Annie Lee, Chiamaka Chukwuneke, Happy Buzaaba, Blessing Sibanda, Godson Kalipe, Jonathan Mukiibi, Salomon Kabongo, Foutse Yuehgoh, Mmasibidi Setaka, Lolwethu Ndolela, Nkiruka Odu, Rooweither Mabuya, Shamsuddeen Hassan Muhammad, Salomey Osei, Sokhar Samb, Tadesse Kebede Guge, Pontus Stenetorp
0
0
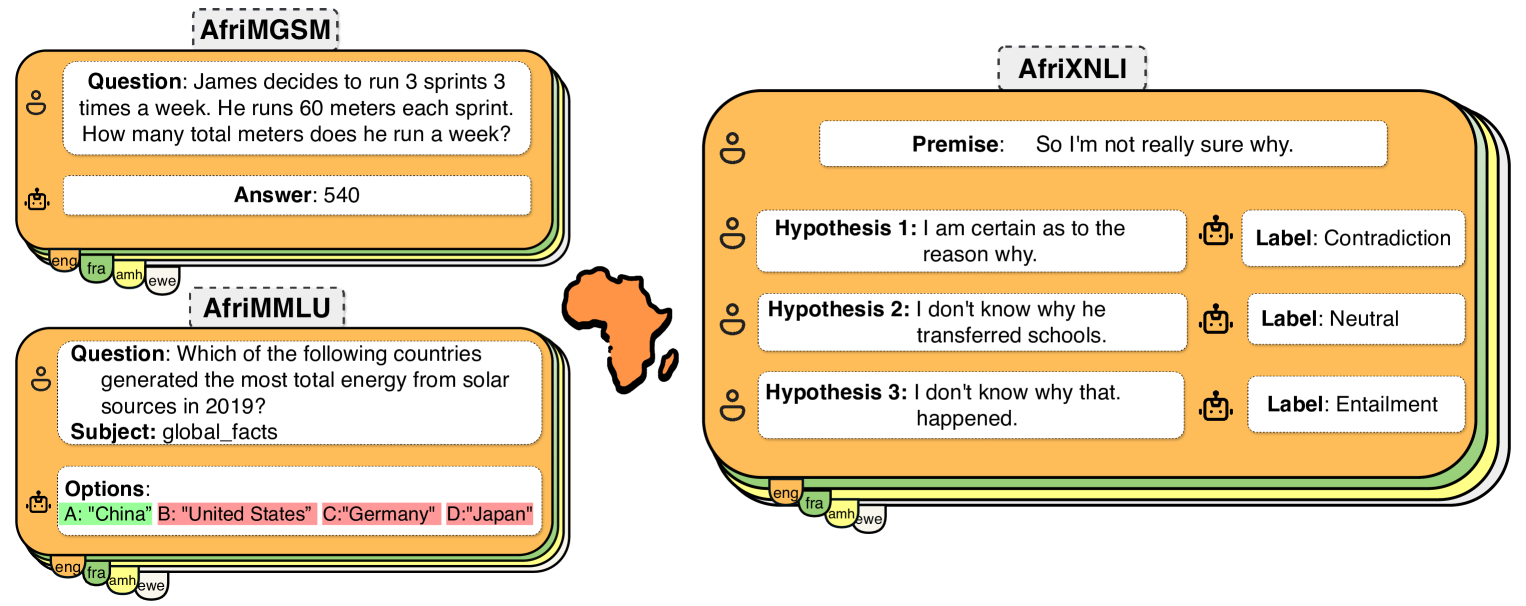
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
6/6/2024