A Japanese-Chinese Parallel Corpus Using Crowdsourcing for Web Mining
2405.09017
0
0
🎯
Abstract
Using crowdsourcing, we collected more than 10,000 URL pairs (parallel top page pairs) of bilingual websites that contain parallel documents and created a Japanese-Chinese parallel corpus of 4.6M sentence pairs from these websites. We used a Japanese-Chinese bilingual dictionary of 160K word pairs for document and sentence alignment. We then used high-quality 1.2M Japanese-Chinese sentence pairs to train a parallel corpus filter based on statistical language models and word translation probabilities. We compared the translation accuracy of the model trained on these 4.6M sentence pairs with that of the model trained on Japanese-Chinese sentence pairs from CCMatrix (12.4M), a parallel corpus from global web mining. Although our corpus is only one-third the size of CCMatrix, we found that the accuracy of the two models was comparable and confirmed that it is feasible to use crowdsourcing for web mining of parallel data.
Create account to get full access
Overview
- Collected over 10,000 URL pairs of bilingual websites with parallel documents
- Created a Japanese-Chinese parallel corpus of 4.6M sentence pairs from these websites
- Used a 160K word pair Japanese-Chinese bilingual dictionary for document and sentence alignment
- Trained a parallel corpus filter using 1.2M high-quality Japanese-Chinese sentence pairs
- Compared the translation accuracy of the model trained on 4.6M sentence pairs to the model trained on 12.4M sentence pairs from CCMatrix
- Found the accuracy of the two models was comparable, demonstrating the feasibility of using crowdsourcing for web mining of parallel data
Plain English Explanation
The researchers collected a large number of website pairs with content in both Japanese and Chinese. They used these websites to create a parallel corpus - a dataset of sentence-level translations between the two languages. This corpus contained 4.6 million sentence pairs.
To help align the sentences between the two languages, the researchers used a Japanese-Chinese dictionary with 160,000 word pairs. They then used a subset of 1.2 million high-quality sentence pairs to train a filtering model. This model could identify which sentence pairs were good translations of each other, based on statistical patterns in the language.
The researchers compared the performance of machine translation models trained on their 4.6 million sentence pair corpus versus a larger 12.4 million sentence pair corpus called CCMatrix. Even though their corpus was only about a third the size, the translation accuracy of the two models was similar. This suggests that it is feasible to use crowdsourcing techniques to build useful parallel corpora for language translation, without needing to rely solely on large web mining efforts.
Technical Explanation
The researchers collected a large number of URL pairs of bilingual websites that contained parallel documents. From these websites, they created a Japanese-Chinese parallel corpus containing 4.6 million sentence pairs.
To align the documents and sentences between the two languages, the researchers used a Japanese-Chinese bilingual dictionary with 160,000 word pairs. They then used a subset of 1.2 million high-quality sentence pairs to train a parallel corpus filter. This filter used statistical language models and word translation probabilities to identify which sentence pairs were good translations of each other.
The researchers compared the translation accuracy of a model trained on their 4.6 million sentence pair corpus to a model trained on 12.4 million sentence pairs from the CCMatrix corpus. Despite being only about one-third the size, they found the translation accuracy of the two models was comparable. This confirms that it is feasible to use crowdsourcing techniques, such as identifying parallel web pages, to build useful parallel corpora for machine translation, without needing to rely solely on large-scale web mining efforts.
Critical Analysis
The researchers acknowledge that their corpus of 4.6 million sentence pairs is relatively small compared to the 12.4 million sentence pairs in the CCMatrix corpus. They also note that the quality of the sentence pairs in their corpus may vary, as they were collected through crowdsourcing rather than large-scale web mining.
While the researchers found that the translation accuracy of the two models was comparable, it's possible that the CCMatrix corpus may still have an advantage in certain language domains or use cases. The researchers encourage further research to explore the strengths and limitations of both approaches to parallel corpus construction.
Additionally, the researchers do not provide much detail on the specific crowdsourcing techniques they used to collect the website pairs. More research may be needed to understand the best practices and challenges of using crowdsourcing for parallel data collection.
Overall, the researchers have demonstrated a promising approach to building useful parallel corpora through crowdsourcing, but there is still room for further exploration and refinement of the methodology.
Conclusion
This research shows that it is possible to use crowdsourcing techniques to build a large-scale parallel corpus for machine translation, without needing to rely solely on web mining efforts. The researchers were able to create a Japanese-Chinese corpus of 4.6 million sentence pairs that achieved comparable translation accuracy to a much larger corpus.
This suggests that crowdsourcing can be a viable and cost-effective approach for building high-quality parallel data, which is a critical component of cross-lingual language models and other multilingual natural language processing applications. As the field of machine translation continues to advance, techniques like this that leverage the wisdom of the crowd could play an important role in accelerating progress and making language technologies more accessible to diverse global audiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
KazParC: Kazakh Parallel Corpus for Machine Translation
Rustem Yeshpanov, Alina Polonskaya, Huseyin Atakan Varol
0
0
We introduce KazParC, a parallel corpus designed for machine translation across Kazakh, English, Russian, and Turkish. The first and largest publicly available corpus of its kind, KazParC contains a collection of 371,902 parallel sentences covering different domains and developed with the assistance of human translators. Our research efforts also extend to the development of a neural machine translation model nicknamed Tilmash. Remarkably, the performance of Tilmash is on par with, and in certain instances, surpasses that of industry giants, such as Google Translate and Yandex Translate, as measured by standard evaluation metrics, such as BLEU and chrF. Both KazParC and Tilmash are openly available for download under the Creative Commons Attribution 4.0 International License (CC BY 4.0) through our GitHub repository.
4/11/2024
💬
Quality Does Matter: A Detailed Look at the Quality and Utility of Web-Mined Parallel Corpora
Surangika Ranathunga, Nisansa de Silva, Menan Velayuthan, Aloka Fernando, Charitha Rathnayake
0
0
We conducted a detailed analysis on the quality of web-mined corpora for two low-resource languages (making three language pairs, English-Sinhala, English-Tamil and Sinhala-Tamil). We ranked each corpus according to a similarity measure and carried out an intrinsic and extrinsic evaluation on different portions of this ranked corpus. We show that there are significant quality differences between different portions of web-mined corpora and that the quality varies across languages and datasets. We also show that, for some web-mined datasets, Neural Machine Translation (NMT) models trained with their highest-ranked 25k portion can be on par with human-curated datasets.
6/17/2024

New!A Recipe of Parallel Corpora Exploitation for Multilingual Large Language Models
Peiqin Lin, Andr'e F. T. Martins, Hinrich Schutze
0
0
Recent studies have highlighted the potential of exploiting parallel corpora to enhance multilingual large language models, improving performance in both bilingual tasks, e.g., machine translation, and general-purpose tasks, e.g., text classification. Building upon these findings, our comprehensive study aims to identify the most effective strategies for leveraging parallel corpora. We investigate the impact of parallel corpora quality and quantity, training objectives, and model size on the performance of multilingual large language models enhanced with parallel corpora across diverse languages and tasks. Our analysis reveals several key insights: (i) filtering noisy translations is essential for effectively exploiting parallel corpora, while language identification and short sentence filtering have little effect; (ii) even a corpus containing just 10K parallel sentences can yield results comparable to those obtained from much larger datasets; (iii) employing only the machine translation objective yields the best results among various training objectives and their combinations; (iv) larger multilingual language models benefit more from parallel corpora than smaller models due to their stronger capacity for cross-task transfer. Our study offers valuable insights into the optimal utilization of parallel corpora to enhance multilingual large language models, extending the generalizability of previous findings from limited languages and tasks to a broader range of scenarios.
7/2/2024
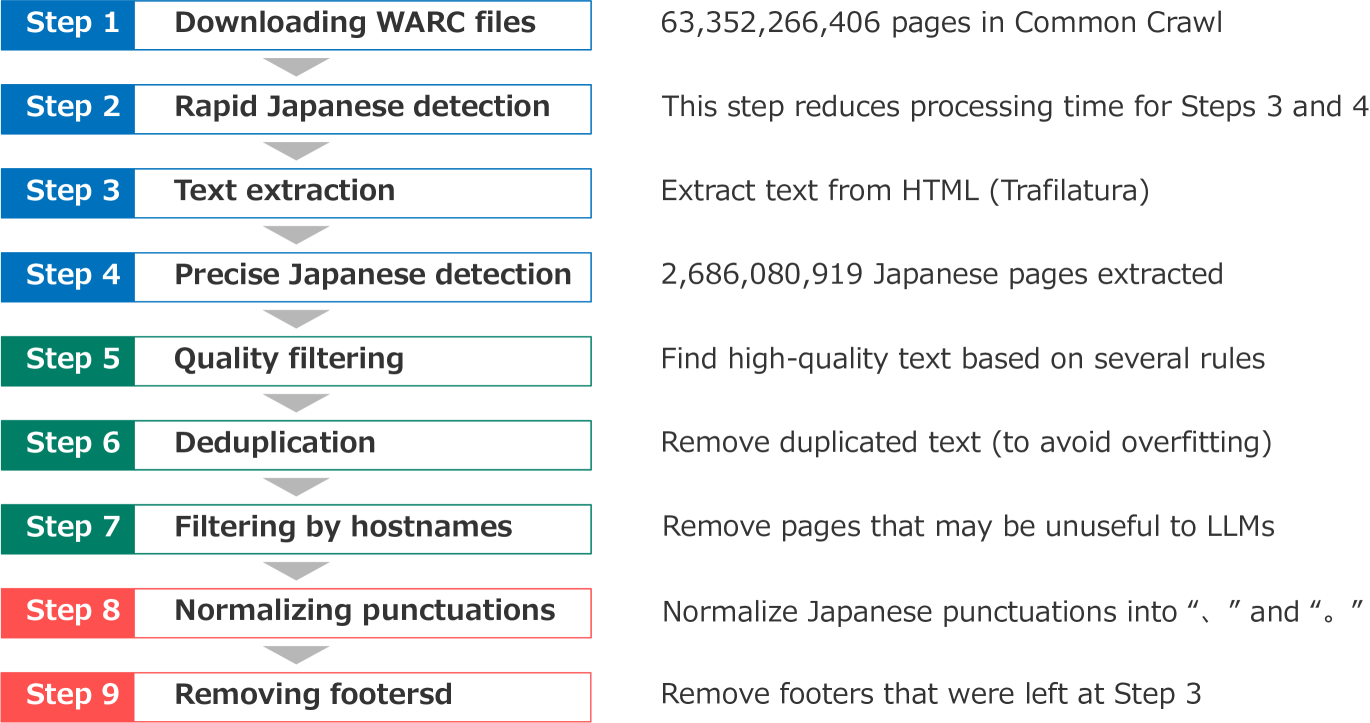
Building a Large Japanese Web Corpus for Large Language Models
Naoaki Okazaki, Kakeru Hattori, Hirai Shota, Hiroki Iida, Masanari Ohi, Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Rio Yokota, Sakae Mizuki
0
0
Open Japanese large language models (LLMs) have been trained on the Japanese portions of corpora such as CC-100, mC4, and OSCAR. However, these corpora were not created for the quality of Japanese texts. This study builds a large Japanese web corpus by extracting and refining text from the Common Crawl archive (21 snapshots of approximately 63.4 billion pages crawled between 2020 and 2023). This corpus consists of approximately 312.1 billion characters (approximately 173 million pages), which is the largest of all available training corpora for Japanese LLMs, surpassing CC-100 (approximately 25.8 billion characters), mC4 (approximately 239.7 billion characters) and OSCAR 23.10 (approximately 74 billion characters). To confirm the quality of the corpus, we performed continual pre-training on Llama 2 7B, 13B, 70B, Mistral 7B v0.1, and Mixtral 8x7B Instruct as base LLMs and gained consistent (6.6-8.1 points) improvements on Japanese benchmark datasets. We also demonstrate that the improvement on Llama 2 13B brought from the presented corpus was the largest among those from other existing corpora.
4/30/2024