KGpose: Keypoint-Graph Driven End-to-End Multi-Object 6D Pose Estimation via Point-Wise Pose Voting

0

Sign in to get full access
Overview
- This paper presents a novel deep learning-based method for estimating the 6D pose (position and orientation) of multiple objects in a given scene.
- The proposed approach, called KGpose, uses a keypoint-graph driven end-to-end network architecture to achieve accurate and efficient multi-object 6D pose estimation.
- KGpose leverages point-wise pose voting to infer the 6D poses of multiple objects simultaneously, addressing limitations of previous methods.
Plain English Explanation
The paper introduces a new way to estimate the 3D position and orientation (known as 6D pose) of multiple objects in an image or video frame. This is an important task for applications like robotic manipulation, augmented reality, and autonomous driving, where knowing the precise location and orientation of objects is crucial.
The key idea behind the KGpose method is to use a deep neural network that can look at an image and directly output the 6D poses of all the objects in the scene. This differs from previous approaches that first detected the objects and then estimated their poses separately.
The network architecture of KGpose is designed to be "end-to-end", meaning it can perform the entire 6D pose estimation process in a single forward pass, without requiring multiple stages. It builds on ideas from earlier work like RDPN6D and One-Point-One-Object, but introduces several key innovations.
One important aspect is the use of a "keypoint graph", which encodes the spatial relationships between different parts of the objects. This helps the network understand the 3D structure of the objects, which is crucial for accurate pose estimation. The keypoint graph approach is similar to techniques used in prior work like OMNi6DPose.
Another novel component is the "point-wise pose voting" mechanism, which allows the network to infer the 6D poses of multiple objects simultaneously. This is more efficient than approaches that estimate poses one object at a time. This simultaneous multi-object pose estimation is related to ideas explored in papers like SRPose.
Overall, the KGpose method represents an important advancement in 6D pose estimation, with the potential to enable more accurate and efficient object tracking and manipulation in a variety of real-world applications.
Technical Explanation
The KGpose method uses a deep neural network with a keypoint-graph driven architecture to perform end-to-end multi-object 6D pose estimation. The network takes an input image and directly outputs the 6D poses (position and orientation) of all the objects in the scene.
The key components of the KGpose architecture include:
-
Keypoint-Graph Representation: The network learns to predict a graph-structured representation of the object keypoints, which encodes the spatial relationships between different parts of the objects. This helps the network understand the 3D structure of the objects.
-
Point-Wise Pose Voting: The network uses a point-wise voting mechanism to infer the 6D poses of multiple objects simultaneously. Each pixel in the feature map casts votes for the 6D pose of the object it belongs to, allowing the network to handle multiple objects in a single forward pass.
-
End-to-End Training: KGpose is trained in an end-to-end fashion, directly optimizing the 6D pose estimation objective without requiring separate object detection or pose regression stages. This makes the inference process more efficient compared to multi-stage approaches.
The authors conduct extensive experiments on several 6D pose estimation benchmarks, including LINEMOD, YCB-Video, and Occlusion LINEMOD. They demonstrate that KGpose outperforms state-of-the-art methods in terms of both accuracy and inference speed, highlighting the effectiveness of the keypoint-graph representation and point-wise voting approach.
Critical Analysis
The authors provide a thorough evaluation of the KGpose method, discussing its strengths and limitations. One notable limitation is that the current implementation is not fully end-to-end, as it requires a separate object segmentation step. The authors acknowledge this and suggest that future work could explore more tightly integrated object detection and pose estimation components.
Additionally, the paper does not provide detailed analysis of the computational complexity and runtime performance of KGpose compared to other methods. While the authors claim improved efficiency, a more comprehensive benchmarking of the inference speed across diverse hardware configurations would help readers better understand the practical advantages of the proposed approach.
Overall, the KGpose method represents a significant advancement in multi-object 6D pose estimation, with a well-designed architecture and promising experimental results. The paper provides a solid foundation for future research in this important computer vision task.
Conclusion
The KGpose paper introduces a novel deep learning-based approach for estimating the 6D poses (position and orientation) of multiple objects in a given scene. The key innovations include the use of a keypoint-graph representation to capture the 3D structure of objects, and a point-wise pose voting mechanism to enable efficient simultaneous pose estimation of multiple objects.
The experimental results demonstrate that KGpose outperforms state-of-the-art methods in terms of both accuracy and inference speed, highlighting its potential for real-world applications such as robotic manipulation, augmented reality, and autonomous driving. While the paper identifies some areas for future research, such as tighter integration of object detection and pose estimation, the KGpose method represents an important step forward in the field of 6D pose estimation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
KGpose: Keypoint-Graph Driven End-to-End Multi-Object 6D Pose Estimation via Point-Wise Pose Voting
Andrew Jeong
This letter presents KGpose, a novel end-to-end framework for 6D pose estimation of multiple objects. Our approach combines keypoint-based method with learnable pose regression through `keypoint-graph', which is a graph representation of the keypoints. KGpose first estimates 3D keypoints for each object using an attentional multi-modal feature fusion of RGB and point cloud features. These keypoints are estimated from each point of point cloud and converted into a graph representation. The network directly regresses 6D pose parameters for each point through a sequence of keypoint-graph embedding and local graph embedding which are designed with graph convolutions, followed by rotation and translation heads. The final pose for each object is selected from the candidates of point-wise predictions. The method achieves competitive results on the benchmark dataset, demonstrating the effectiveness of our model. KGpose enables multi-object pose estimation without requiring an extra localization step, offering a unified and efficient solution for understanding geometric contexts in complex scenes for robotic applications.
Read more7/15/2024
🤷
0
Pseudo-keypoint RKHS Learning for Self-supervised 6DoF Pose Estimation
Yangzheng Wu, Michael Greenspan
We address the simulation-to-real domain gap in six degree-of-freedom pose estimation (6DoF PE), and propose a novel self-supervised keypoint voting-based 6DoF PE framework, effectively narrowing this gap using a learnable kernel in RKHS. We formulate this domain gap as a distance in high-dimensional feature space, distinct from previous iterative matching methods. We propose an adapter network, which is pre-trained on purely synthetic data with synthetic ground truth poses, and which evolves the network parameters from this source synthetic domain to the target real domain. Importantly, the real data training only uses pseudo-poses estimated by pseudo-keypoints, and thereby requires no real ground truth data annotations. Our proposed method is called RKHSPose, and achieves state-of-the-art performance among self-supervised methods on three commonly used 6DoF PE datasets including LINEMOD (+4.2%), Occlusion LINEMOD (+2%), and YCB-Video (+3%). It also compares favorably to fully supervised methods on all six applicable BOP core datasets, achieving within -11.3% to +0.2% of the top fully supervised results.
Read more7/18/2024

0
A Graph-Based Approach for Category-Agnostic Pose Estimation
Or Hirschorn, Shai Avidan
Traditional 2D pose estimation models are limited by their category-specific design, making them suitable only for predefined object categories. This restriction becomes particularly challenging when dealing with novel objects due to the lack of relevant training data. To address this limitation, category-agnostic pose estimation (CAPE) was introduced. CAPE aims to enable keypoint localization for arbitrary object categories using a few-shot single model, requiring minimal support images with annotated keypoints. We present a significant departure from conventional CAPE techniques, which treat keypoints as isolated entities, by treating the input pose data as a graph. We leverage the inherent geometrical relations between keypoints through a graph-based network to break symmetry, preserve structure, and better handle occlusions. We validate our approach on the MP-100 benchmark, a comprehensive dataset comprising over 20,000 images spanning over 100 categories. Our solution boosts performance by 0.98% under a 1-shot setting, achieving a new state-of-the-art for CAPE. Additionally, we enhance the dataset with skeleton annotations. Our code and data are publicly available.
Read more7/12/2024
0
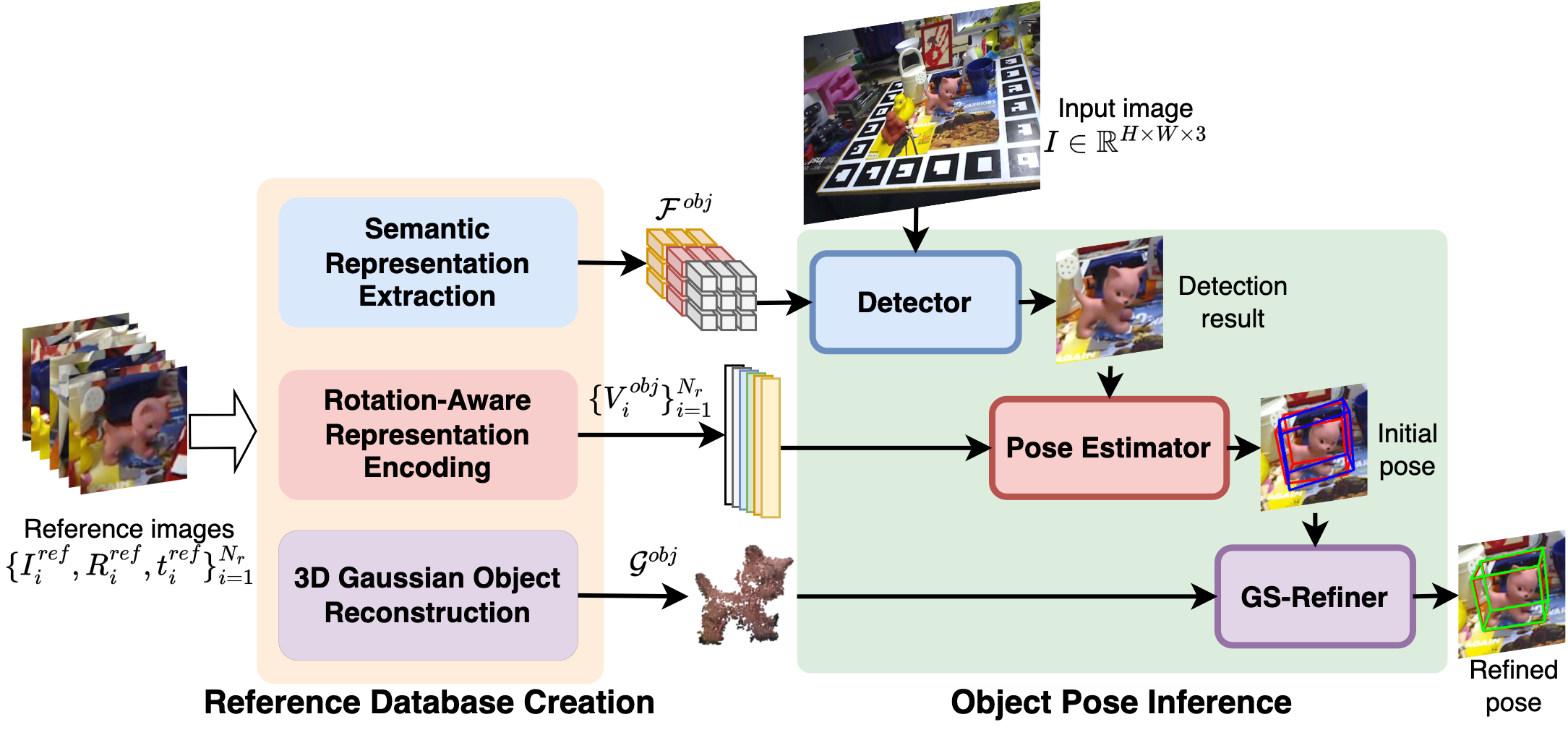
GS-Pose: Generalizable Segmentation-based 6D Object Pose Estimation with 3D Gaussian Splatting
Dingding Cai, Janne Heikkila, Esa Rahtu
This paper introduces GS-Pose, a unified framework for localizing and estimating the 6D pose of novel objects. GS-Pose begins with a set of posed RGB images of a previously unseen object and builds three distinct representations stored in a database. At inference, GS-Pose operates sequentially by locating the object in the input image, estimating its initial 6D pose using a retrieval approach, and refining the pose with a render-and-compare method. The key insight is the application of the appropriate object representation at each stage of the process. In particular, for the refinement step, we leverage 3D Gaussian splatting, a novel differentiable rendering technique that offers high rendering speed and relatively low optimization time. Off-the-shelf toolchains and commodity hardware, such as mobile phones, can be used to capture new objects to be added to the database. Extensive evaluations on the LINEMOD and OnePose-LowTexture datasets demonstrate excellent performance, establishing the new state-of-the-art. Project page: https://dingdingcai.github.io/gs-pose.
Read more8/15/2024