Kinematics-based 3D Human-Object Interaction Reconstruction from Single View

0

Sign in to get full access
Overview
- Kinematics-based approach for reconstructing 3D human-object interactions from a single input image
- Novel method to jointly estimate 3D human pose, object pose, and their interactions
- Aims to improve understanding of human-object interactions in 3D scenes
Plain English Explanation
This paper presents a new method for reconstructing 3D human-object interactions from a single input image. The key idea is to use the kinematics, or the motion and positioning, of the human body and objects to infer their 3D relationships.
Rather than just estimating the 3D pose of the human or the object separately, the proposed approach jointly reconstructs the 3D pose of both the human and the object, as well as how they are interacting. This provides a more complete understanding of the 3D scene and the human-object dynamics.
The method works by leveraging the kinematic constraints between the human body and the interacting object. By modeling these physical relationships, the system can more accurately predict the 3D configuration of the human, object, and their interaction.
Technical Explanation
The paper introduces a kinematics-based 3D human-object interaction reconstruction approach from a single input image. The key technical contributions are:
- A novel neural network architecture that jointly estimates the 3D human pose, object pose, and their interaction.
- Incorporation of kinematic constraints between the human and object to improve the 3D reconstruction.
- A contact-guided loss function that enforces physical plausibility of the predicted human-object interaction.
The model first extracts visual features from the input image using a CNN backbone. It then uses a series of decoders to predict the 3D human pose, 3D object pose, and contact points between the human and object. The contact information is used to guide the reconstruction and ensure the interaction is physically valid.
Experiments on benchmark datasets show the proposed method outperforms prior work on 3D human-object interaction reconstruction from single views. The joint estimation of human, object, and interaction yields more complete and accurate 3D scene understanding compared to decoupled approaches.
Critical Analysis
The paper presents a strong technical contribution in the area of 3D human-object interaction reconstruction. The key strength is the joint modeling of human, object, and interaction, which allows the system to leverage kinematic and physical constraints to improve the 3D reconstruction.
However, a potential limitation is that the method still relies on a single input image, which inherently lacks depth information. While the kinematics-based approach helps overcome this, incorporating additional cues like temporal information or depth sensors could further boost performance.
Additionally, the paper focuses on controlled, lab-like settings with known object categories. Extending the approach to handle more diverse, cluttered real-world scenes with unknown objects would be an important direction for future research.
Conclusion
This work presents a novel kinematics-based method for reconstructing 3D human-object interactions from a single input image. By jointly estimating the 3D pose of the human, object, and their interaction, the system can leverage physical constraints to improve the overall 3D scene understanding.
The technical contributions and experimental results demonstrate the value of this approach for tasks like human-robot interaction, augmented reality, and video analysis. As the field of 3D human-object understanding continues to evolve, techniques like the one proposed in this paper will be crucial for building more intelligent and responsive AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Kinematics-based 3D Human-Object Interaction Reconstruction from Single View
Yuhang Chen, Chenxing Wang
Reconstructing 3D human-object interaction (HOI) from single-view RGB images is challenging due to the absence of depth information and potential occlusions. Existing methods simply predict the body poses merely rely on network training on some indoor datasets, which cannot guarantee the rationality of the results if some body parts are invisible due to occlusions that appear easily. Inspired by the end-effector localization task in robotics, we propose a kinematics-based method that can drive the joints of human body to the human-object contact regions accurately. After an improved forward kinematics algorithm is proposed, the Multi-Layer Perceptron is introduced into the solution of inverse kinematics process to determine the poses of joints, which achieves precise results than the commonly-used numerical methods in robotics. Besides, a Contact Region Recognition Network (CRRNet) is also proposed to robustly determine the contact regions using a single-view video. Experimental results demonstrate that our method outperforms the state-of-the-art on benchmark BEHAVE. Additionally, our approach shows good portability and can be seamlessly integrated into other methods for optimizations.
Read more7/22/2024

0
Monocular Human-Object Reconstruction in the Wild
Chaofan Huo, Ye Shi, Jingya Wang
Learning the prior knowledge of the 3D human-object spatial relation is crucial for reconstructing human-object interaction from images and understanding how humans interact with objects in 3D space. Previous works learn this prior from datasets collected in controlled environments, but due to the diversity of domains, they struggle to generalize to real-world scenarios. To overcome this limitation, we present a 2D-supervised method that learns the 3D human-object spatial relation prior purely from 2D images in the wild. Our method utilizes a flow-based neural network to learn the prior distribution of the 2D human-object keypoint layout and viewports for each image in the dataset. The effectiveness of the prior learned from 2D images is demonstrated on the human-object reconstruction task by applying the prior to tune the relative pose between the human and the object during the post-optimization stage. To validate and benchmark our method on in-the-wild images, we collect the WildHOI dataset from the YouTube website, which consists of various interactions with 8 objects in real-world scenarios. We conduct the experiments on the indoor BEHAVE dataset and the outdoor WildHOI dataset. The results show that our method achieves almost comparable performance with fully 3D supervised methods on the BEHAVE dataset, even if we have only utilized the 2D layout information, and outperforms previous methods in terms of generality and interaction diversity on in-the-wild images.
Read more8/1/2024
0
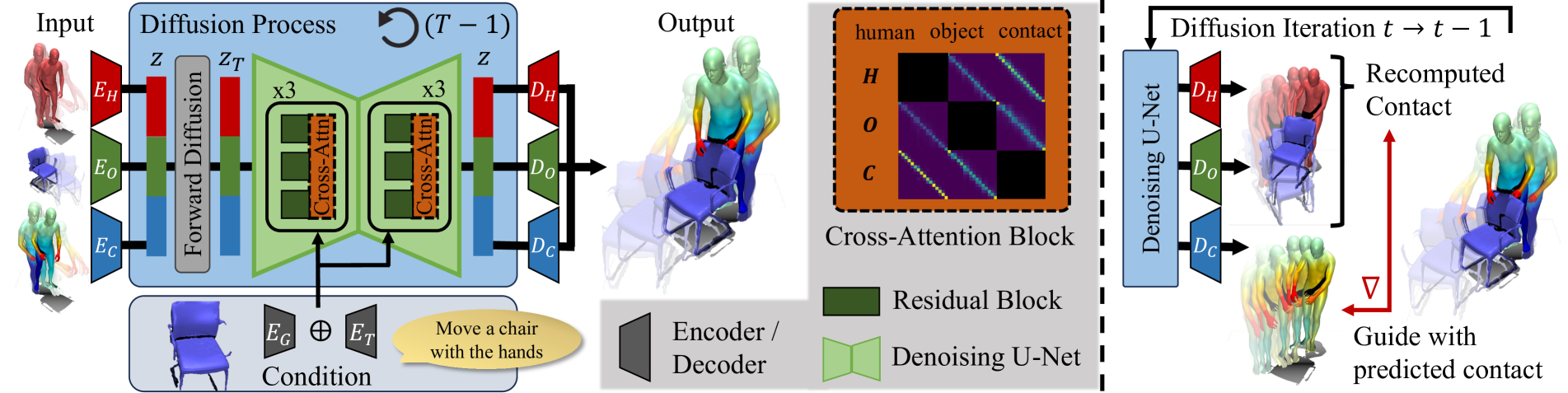
CG-HOI: Contact-Guided 3D Human-Object Interaction Generation
Christian Diller, Angela Dai
We propose CG-HOI, the first method to address the task of generating dynamic 3D human-object interactions (HOIs) from text. We model the motion of both human and object in an interdependent fashion, as semantically rich human motion rarely happens in isolation without any interactions. Our key insight is that explicitly modeling contact between the human body surface and object geometry can be used as strong proxy guidance, both during training and inference. Using this guidance to bridge human and object motion enables generating more realistic and physically plausible interaction sequences, where the human body and corresponding object move in a coherent manner. Our method first learns to model human motion, object motion, and contact in a joint diffusion process, inter-correlated through cross-attention. We then leverage this learned contact for guidance during inference to synthesize realistic and coherent HOIs. Extensive evaluation shows that our joint contact-based human-object interaction approach generates realistic and physically plausible sequences, and we show two applications highlighting the capabilities of our method. Conditioned on a given object trajectory, we can generate the corresponding human motion without re-training, demonstrating strong human-object interdependency learning. Our approach is also flexible, and can be applied to static real-world 3D scene scans.
Read more5/20/2024
0
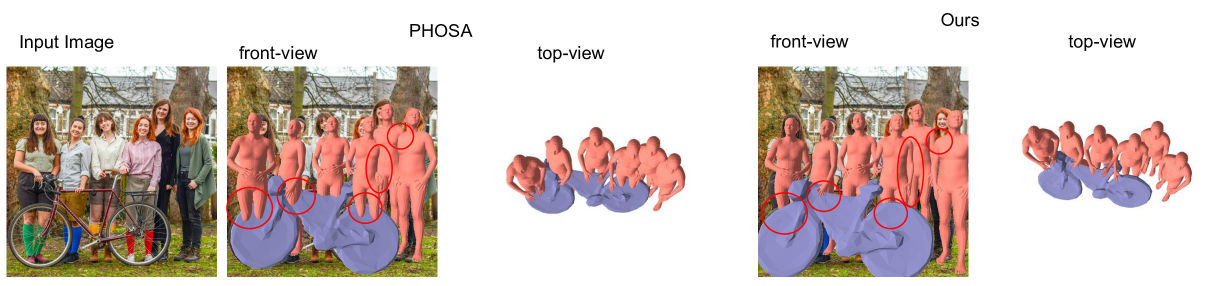
Single-image coherent reconstruction of objects and humans
Sarthak Batra, Partha P. Chakrabarti, Simon Hadfield, Armin Mustafa
Existing methods for reconstructing objects and humans from a monocular image suffer from severe mesh collisions and performance limitations for interacting occluding objects. This paper introduces a method to obtain a globally consistent 3D reconstruction of interacting objects and people from a single image. Our contributions include: 1) an optimization framework, featuring a collision loss, tailored to handle human-object and human-human interactions, ensuring spatially coherent scene reconstruction; and 2) a novel technique to robustly estimate 6 degrees of freedom (DOF) poses, specifically for heavily occluded objects, exploiting image inpainting. Notably, our proposed method operates effectively on images from real-world scenarios, without necessitating scene or object-level 3D supervision. Extensive qualitative and quantitative evaluation against existing methods demonstrates a significant reduction in collisions in the final reconstructions of scenes with multiple interacting humans and objects and a more coherent scene reconstruction.
Read more8/16/2024