Single-image coherent reconstruction of objects and humans

0
Sign in to get full access
Overview
- This paper presents a method for reconstructing 3D models of objects and humans from a single input image.
- The approach aims to produce coherent and realistic 3D reconstructions that capture the structure and appearance of the scene.
- The method uses a deep neural network to jointly estimate 3D geometry, material properties, and lighting from a single image.
Plain English Explanation
The paper describes a technique for creating 3D digital models of objects and people from a single photograph. The key idea is to use a machine learning algorithm to analyze the contents of the image and automatically generate a 3D representation that accurately reflects the 3D structure, material properties, and lighting of the scene.
This is a challenging task, as a single 2D image contains limited information about the 3D world. However, the authors have developed a sophisticated neural network model that can cleverly infer the missing 3D details by recognizing patterns in the image data. The result is a 3D reconstruction that looks realistic and coherent, capturing the full 3D nature of the objects and people depicted.
This technology could be useful for a variety of applications, such as 3D reconstruction from monocular video, interactive 3D modeling of people and objects, and generating 3D clothing models from images. By automating the process of 3D reconstruction from single images, this approach could make it easier and more accessible to create high-quality 3D content.
Technical Explanation
The paper proposes a novel neural network architecture for single-image 3D reconstruction of objects and humans. The key innovation is the use of a coherent reconstruction approach, which aims to jointly estimate the 3D geometry, material properties, and lighting conditions of the scene.
The network takes a single RGB image as input and outputs a set of 3D meshes representing the objects and people in the scene, along with their associated material and lighting parameters. This is achieved through a multi-task learning framework that shares representational features across the different reconstruction subtasks.
The network architecture consists of an encoder-decoder structure, with a shared backbone encoder followed by separate decoders for geometry, materials, and lighting. The geometry decoder outputs a set of 3D vertex positions and connectivity, while the material and lighting decoders estimate the reflectance properties and illumination conditions, respectively.
The training process leverages diverse datasets of 3D models, materials, and lighting conditions to enable the network to learn robust feature representations. During inference, the network can take a single input image and efficiently generate a coherent 3D reconstruction of the scene.
The authors evaluate their approach on several benchmarks, demonstrating state-of-the-art performance on tasks such as complete 3D human shape reconstruction from a single image and jointly reconstructing multiple interacting people and objects. The results highlight the effectiveness of the coherent reconstruction approach in producing high-quality 3D models that faithfully capture the real-world scene.
Critical Analysis
The paper presents a compelling and technically sophisticated approach to single-image 3D reconstruction. The authors' key contribution is the coherent reconstruction framework, which jointly estimates the 3D geometry, materials, and lighting of the scene. This holistic approach is a significant advancement over previous methods that treated these aspects separately.
One potential limitation of the approach is the reliance on diverse training data, which may not always be available, especially for complex real-world scenes. The authors acknowledge this and suggest future work could explore strategies for handling more diverse and challenging input images.
Additionally, while the results demonstrate impressive reconstruction quality, there may be room for improvement in terms of computational efficiency and inference speed, especially for real-time applications. The authors could explore model compression techniques or dedicated hardware acceleration to address this.
Overall, this work represents an important step forward in single-image 3D reconstruction, with the potential to enable more natural and intuitive 3D content creation from everyday photographs. The authors' insights and technical innovations could inspire further research in this area, leading to even more powerful and user-friendly tools for 3D modeling and scene understanding.
Conclusion
This paper presents a novel deep learning-based approach for reconstructing 3D models of objects and humans from a single input image. The key innovation is the coherent reconstruction framework, which jointly estimates the 3D geometry, material properties, and lighting conditions of the scene.
The authors demonstrate state-of-the-art results on various 3D reconstruction benchmarks, showcasing the ability of their method to generate highly realistic and structurally accurate 3D models from 2D images. This technology has the potential to significantly streamline and democratize 3D content creation, making it more accessible to a wider range of users and applications.
While the paper highlights some limitations, such as the reliance on diverse training data, the authors' technical contributions and insights could inspire further advancements in this field. As 3D reconstruction from single images continues to improve, we may see increasingly widespread adoption of these tools in a variety of industries, from entertainment and design to e-commerce and virtual reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Single-image coherent reconstruction of objects and humans
Sarthak Batra, Partha P. Chakrabarti, Simon Hadfield, Armin Mustafa
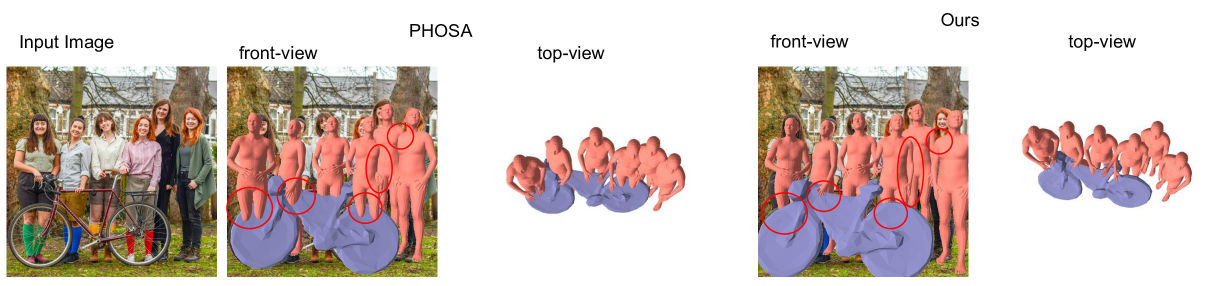
Existing methods for reconstructing objects and humans from a monocular image suffer from severe mesh collisions and performance limitations for interacting occluding objects. This paper introduces a method to obtain a globally consistent 3D reconstruction of interacting objects and people from a single image. Our contributions include: 1) an optimization framework, featuring a collision loss, tailored to handle human-object and human-human interactions, ensuring spatially coherent scene reconstruction; and 2) a novel technique to robustly estimate 6 degrees of freedom (DOF) poses, specifically for heavily occluded objects, exploiting image inpainting. Notably, our proposed method operates effectively on images from real-world scenarios, without necessitating scene or object-level 3D supervision. Extensive qualitative and quantitative evaluation against existing methods demonstrates a significant reduction in collisions in the final reconstructions of scenes with multiple interacting humans and objects and a more coherent scene reconstruction.
Read more8/16/2024

0
3D Reconstruction of Interacting Multi-Person in Clothing from a Single Image
Junuk Cha, Hansol Lee, Jaewon Kim, Nhat Nguyen Bao Truong, Jae Shin Yoon, Seungryul Baek
This paper introduces a novel pipeline to reconstruct the geometry of interacting multi-person in clothing on a globally coherent scene space from a single image. The main challenge arises from the occlusion: a part of a human body is not visible from a single view due to the occlusion by others or the self, which introduces missing geometry and physical implausibility (e.g., penetration). We overcome this challenge by utilizing two human priors for complete 3D geometry and surface contacts. For the geometry prior, an encoder learns to regress the image of a person with missing body parts to the latent vectors; a decoder decodes these vectors to produce 3D features of the associated geometry; and an implicit network combines these features with a surface normal map to reconstruct a complete and detailed 3D humans. For the contact prior, we develop an image-space contact detector that outputs a probability distribution of surface contacts between people in 3D. We use these priors to globally refine the body poses, enabling the penetration-free and accurate reconstruction of interacting multi-person in clothing on the scene space. The results demonstrate that our method is complete, globally coherent, and physically plausible compared to existing methods.
Read more4/3/2024

0
COSMU: Complete 3D human shape from monocular unconstrained images
Marco Pesavento, Marco Volino, Adrian Hilton
We present a novel framework to reconstruct complete 3D human shapes from a given target image by leveraging monocular unconstrained images. The objective of this work is to reproduce high-quality details in regions of the reconstructed human body that are not visible in the input target. The proposed methodology addresses the limitations of existing approaches for reconstructing 3D human shapes from a single image, which cannot reproduce shape details in occluded body regions. The missing information of the monocular input can be recovered by using multiple views captured from multiple cameras. However, multi-view reconstruction methods necessitate accurately calibrated and registered images, which can be challenging to obtain in real-world scenarios. Given a target RGB image and a collection of multiple uncalibrated and unregistered images of the same individual, acquired using a single camera, we propose a novel framework to generate complete 3D human shapes. We introduce a novel module to generate 2D multi-view normal maps of the person registered with the target input image. The module consists of body part-based reference selection and body part-based registration. The generated 2D normal maps are then processed by a multi-view attention-based neural implicit model that estimates an implicit representation of the 3D shape, ensuring the reproduction of details in both observed and occluded regions. Extensive experiments demonstrate that the proposed approach estimates higher quality details in the non-visible regions of the 3D clothed human shapes compared to related methods, without using parametric models.
Read more7/16/2024

0
Kinematics-based 3D Human-Object Interaction Reconstruction from Single View
Yuhang Chen, Chenxing Wang
Reconstructing 3D human-object interaction (HOI) from single-view RGB images is challenging due to the absence of depth information and potential occlusions. Existing methods simply predict the body poses merely rely on network training on some indoor datasets, which cannot guarantee the rationality of the results if some body parts are invisible due to occlusions that appear easily. Inspired by the end-effector localization task in robotics, we propose a kinematics-based method that can drive the joints of human body to the human-object contact regions accurately. After an improved forward kinematics algorithm is proposed, the Multi-Layer Perceptron is introduced into the solution of inverse kinematics process to determine the poses of joints, which achieves precise results than the commonly-used numerical methods in robotics. Besides, a Contact Region Recognition Network (CRRNet) is also proposed to robustly determine the contact regions using a single-view video. Experimental results demonstrate that our method outperforms the state-of-the-art on benchmark BEHAVE. Additionally, our approach shows good portability and can be seamlessly integrated into other methods for optimizations.
Read more7/22/2024