Knowledge acquisition for dialogue agents using reinforcement learning on graph representations

0
Sign in to get full access
Overview
- This paper explores using reinforcement learning on graph representations to enable dialogue agents to acquire knowledge.
- The researchers develop a novel framework that combines knowledge graphs, pretrained language models, and reinforcement learning to improve dialogue agents' ability to engage in informative and coherent conversations.
- Key contributions include a graph-based knowledge representation, a reinforcement learning approach for optimizing dialogue policies, and empirical results demonstrating the effectiveness of the proposed system.
Plain English Explanation
The researchers in this paper are working on improving the knowledge and conversational abilities of AI dialogue agents. Dialogue agents are computer programs designed to engage in back-and-forth conversations with humans, like chatbots or virtual assistants.
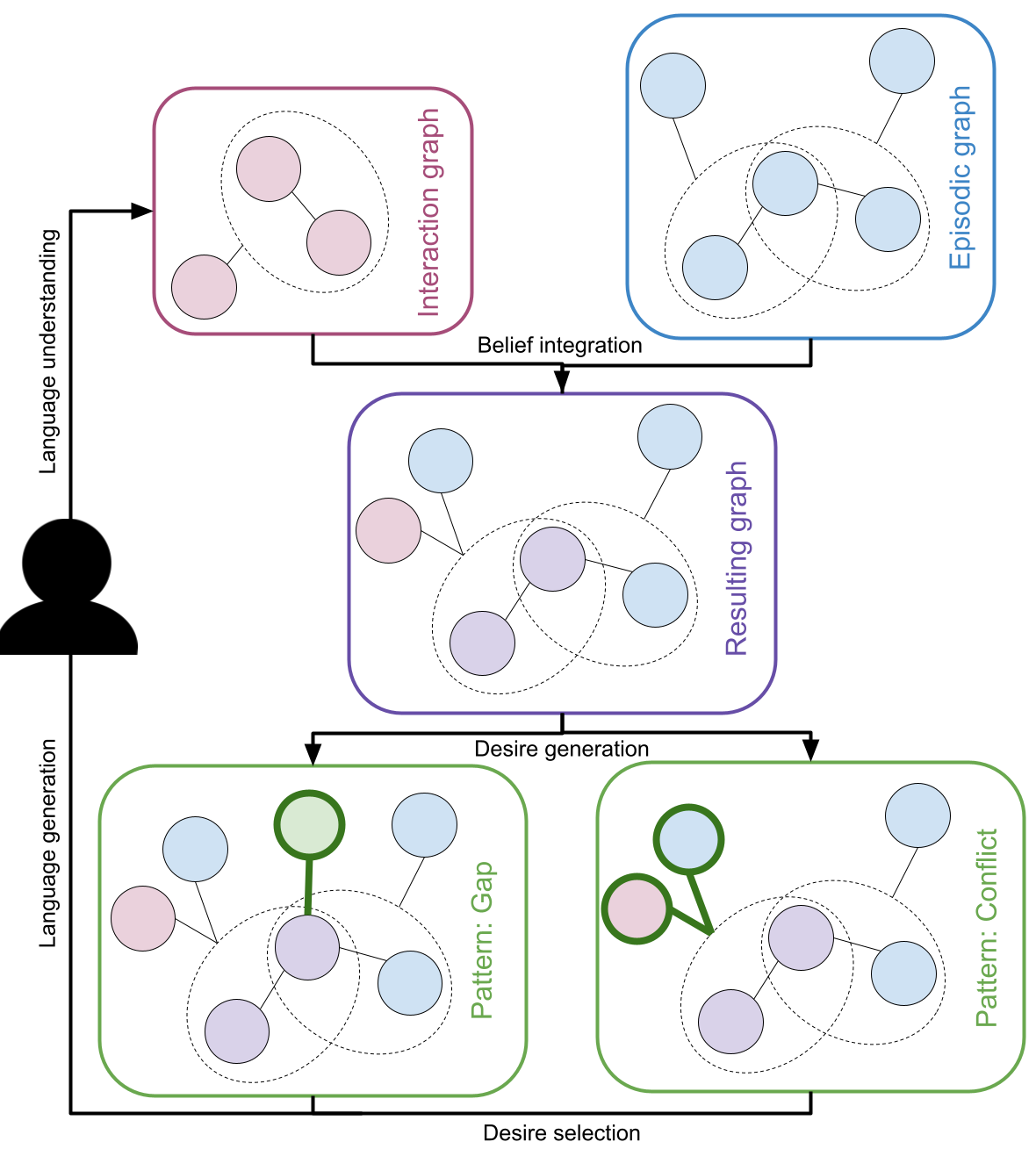
One of the major challenges for these agents is acquiring and maintaining a broad base of knowledge that they can draw upon to have meaningful, informative conversations. The researchers explore using a knowledge graph - a structured way of representing information as interconnected concepts - as a way for the agents to organize and reason about their knowledge.
They also use reinforcement learning, a type of machine learning where the agent learns by trial-and-error, receiving rewards or penalties based on the quality of its responses. This allows the agent to continuously improve its conversational skills and learn the best ways to leverage its knowledge graph.
The key innovation here is combining these knowledge graph and reinforcement learning approaches in a unified framework. This gives the dialogue agent a powerful way to acquire new knowledge and negotiate optimal strategies for using that knowledge in conversations. The researchers demonstrate that this produces more informative and coherent dialogues compared to other methods.
Technical Explanation
The researchers propose a novel framework for enabling dialogue agents to acquire knowledge using reinforcement learning on graph representations. At the core of their approach is a knowledge graph - a structured way of representing information as a network of interconnected concepts and relationships.
The agent's knowledge is encoded in this graph, and the researchers use a pre-trained language model to enrich the graph with additional semantic information. This gives the agent a rich, structured representation of its knowledge to draw upon during conversations.
To optimize the agent's dialogue policies, the researchers employ a reinforcement learning approach. The agent takes actions (i.e., generates responses) during a conversation and receives rewards or penalties based on the quality of those responses. Over many conversations, the agent learns to take actions that maximize its reward, resulting in more informative and coherent dialogues.
A key aspect of their framework is how the knowledge graph is integrated with the reinforcement learning process. The agent uses the knowledge graph to reason about the most relevant information to include in its responses, and the reinforcement learning signal helps it learn the best ways to leverage that knowledge.
The researchers evaluate their approach on several dialogue tasks and compare it to other knowledge-enhanced dialogue systems. Their results demonstrate significant improvements in measures of informativeness, coherence, and task completion, validating the effectiveness of their graph-based reinforcement learning framework.
Critical Analysis
The researchers present a compelling approach for enhancing dialogue agents' knowledge and conversational abilities. By combining knowledge graphs, pre-trained language models, and reinforcement learning, they create a powerful framework that allows agents to continuously acquire new knowledge and optimize their dialogue policies.
One potential limitation mentioned in the paper is that the knowledge graph construction and enrichment process relies on external sources, which could introduce biases or incompleteness. The researchers note the need for further work on more autonomous knowledge acquisition, where the agent can discover and integrate new knowledge on its own.
Additionally, the reinforcement learning approach, while effective, could be sensitive to the specific reward functions and may not generalize well to entirely novel conversational domains. Exploring more general negotiation strategies could be an interesting direction for future research.
Overall, this paper makes a valuable contribution to the field of conversational AI by demonstrating a promising approach for enabling dialogue agents to learn and enhance their knowledge-based communication skills. The researchers have laid the groundwork for further advancements in this area, which could have significant implications for the development of more capable and engaging dialogue systems.
Conclusion
This paper presents a novel framework for enabling dialogue agents to acquire knowledge using reinforcement learning on graph representations. By combining knowledge graphs, pre-trained language models, and reinforcement learning, the researchers have developed a powerful system that allows agents to continuously expand their knowledge and optimize their dialogue policies.
The key innovations include the graph-based knowledge representation, the reinforcement learning approach for policy optimization, and the integration of these components into a unified framework. The empirical results demonstrate the effectiveness of this approach, with significant improvements in measures of informativeness, coherence, and task completion compared to other knowledge-enhanced dialogue systems.
While the researchers identify some potential limitations, such as the need for more autonomous knowledge acquisition and the potential sensitivity of the reinforcement learning approach, this work represents an important step forward in the development of more capable and engaging dialogue agents. As the field of conversational AI continues to evolve, the insights and techniques presented in this paper will likely inspire further advancements in this critical area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Knowledge acquisition for dialogue agents using reinforcement learning on graph representations
Selene Baez Santamaria, Shihan Wang, Piek Vossen
We develop an artificial agent motivated to augment its knowledge base beyond its initial training. The agent actively participates in dialogues with other agents, strategically acquiring new information. The agent models its knowledge as an RDF knowledge graph, integrating new beliefs acquired through conversation. Responses in dialogue are generated by identifying graph patterns around these new integrated beliefs. We show that policies can be learned using reinforcement learning to select effective graph patterns during an interaction, without relying on explicit user feedback. Within this context, our study is a proof of concept for leveraging users as effective sources of information.
Read more7/1/2024
🏅
0
Knowledge Graph Reasoning with Self-supervised Reinforcement Learning
Ying Ma, Owen Burns, Mingqiu Wang, Gang Li, Nan Du, Laurent El Shafey, Liqiang Wang, Izhak Shafran, Hagen Soltau
Reinforcement learning (RL) is an effective method of finding reasoning pathways in incomplete knowledge graphs (KGs). To overcome the challenges of a large action space, a self-supervised pre-training method is proposed to warm up the policy network before the RL training stage. To alleviate the distributional mismatch issue in general self-supervised RL (SSRL), in our supervised learning (SL) stage, the agent selects actions based on the policy network and learns from generated labels; this self-generation of labels is the intuition behind the name self-supervised. With this training framework, the information density of our SL objective is increased and the agent is prevented from getting stuck with the early rewarded paths. Our self-supervised RL (SSRL) method improves the performance of RL by pairing it with the wide coverage achieved by SL during pretraining, since the breadth of the SL objective makes it infeasible to train an agent with that alone. We show that our SSRL model meets or exceeds current state-of-the-art results on all Hits@k and mean reciprocal rank (MRR) metrics on four large benchmark KG datasets. This SSRL method can be used as a plug-in for any RL architecture for a KGR task. We adopt two RL architectures, i.e., MINERVA and MultiHopKG as our baseline RL models and experimentally show that our SSRL model consistently outperforms both baselines on all of these four KG reasoning tasks. Full code for the paper available at https://github.com/owenonline/Knowledge-Graph-Reasoning-with-Self-supervised-Reinforcement-Learning.
Read more5/24/2024

0
Reinforcement Learning Approach for Integrating Compressed Contexts into Knowledge Graphs
Ngoc Quach, Qi Wang, Zijun Gao, Qifeng Sun, Bo Guan, Lillian Floyd
The widespread use of knowledge graphs in various fields has brought about a challenge in effectively integrating and updating information within them. When it comes to incorporating contexts, conventional methods often rely on rules or basic machine learning models, which may not fully grasp the complexity and fluidity of context information. This research suggests an approach based on reinforcement learning (RL), specifically utilizing Deep Q Networks (DQN) to enhance the process of integrating contexts into knowledge graphs. By considering the state of the knowledge graph as environment states defining actions as operations for integrating contexts and using a reward function to gauge the improvement in knowledge graph quality post-integration, this method aims to automatically develop strategies for optimal context integration. Our DQN model utilizes networks as function approximators, continually updating Q values to estimate the action value function, thus enabling effective integration of intricate and dynamic context information. Initial experimental findings show that our RL method outperforms techniques in achieving precise context integration across various standard knowledge graph datasets, highlighting the potential and effectiveness of reinforcement learning in enhancing and managing knowledge graphs.
Read more4/22/2024
🚀
0
Leveraging Knowledge Graph Embedding for Effective Conversational Recommendation
Yunwen Xia, Hui Fang, Jie Zhang, Chong Long
Conversational recommender system (CRS), which combines the techniques of dialogue system and recommender system, has obtained increasing interest recently. In contrast to traditional recommender system, it learns the user preference better through interactions (i.e. conversations), and then further boosts the recommendation performance. However, existing studies on CRS ignore to address the relationship among attributes, users, and items effectively, which might lead to inappropriate questions and inaccurate recommendations. In this view, we propose a knowledge graph based conversational recommender system (referred as KG-CRS). Specifically, we first integrate the user-item graph and item-attribute graph into a dynamic graph, i.e., dynamically changing during the dialogue process by removing negative items or attributes. We then learn informative embedding of users, items, and attributes by also considering propagation through neighbors on the graph. Extensive experiments on three real datasets validate the superiority of our method over the state-of-the-art approaches in terms of both the recommendation and conversation tasks.
Read more8/6/2024