Knowledge Graphs and Pre-trained Language Models enhanced Representation Learning for Conversational Recommender Systems
2312.10967
0
0

Abstract
Conversational recommender systems (CRS) utilize natural language interactions and dialogue history to infer user preferences and provide accurate recommendations. Due to the limited conversation context and background knowledge, existing CRSs rely on external sources such as knowledge graphs to enrich the context and model entities based on their inter-relations. However, these methods ignore the rich intrinsic information within entities. To address this, we introduce the Knowledge-Enhanced Entity Representation Learning (KERL) framework, which leverages both the knowledge graph and a pre-trained language model to improve the semantic understanding of entities for CRS. In our KERL framework, entity textual descriptions are encoded via a pre-trained language model, while a knowledge graph helps reinforce the representation of these entities. We also employ positional encoding to effectively capture the temporal information of entities in a conversation. The enhanced entity representation is then used to develop a recommender component that fuses both entity and contextual representations for more informed recommendations, as well as a dialogue component that generates informative entity-related information in the response text. A high-quality knowledge graph with aligned entity descriptions is constructed to facilitate our study, namely the Wiki Movie Knowledge Graph (WikiMKG). The experimental results show that KERL achieves state-of-the-art results in both recommendation and response generation tasks.
Create account to get full access
Overview
- This paper explores how knowledge graphs and pre-trained language models can enhance representation learning for conversational recommender systems.
- The researchers propose a novel framework that leverages knowledge graphs and pre-trained language models to improve the performance of conversational recommender systems.
- The key contributions include developing a knowledge graph-based representation learning approach and incorporating it into a pre-trained language model for enhanced recommendation capabilities.
Plain English Explanation
The paper focuses on improving the way conversational recommender systems work by using two powerful AI tools: knowledge graphs and pre-trained language models. Knowledge graphs are structured databases that contain information about real-world entities and how they are related. Pre-trained language models are AI systems that have been trained on a huge amount of text data, allowing them to understand and generate human language very effectively.
The researchers developed a new framework that combines these two technologies to create more intelligent conversational recommender systems. The idea is that by incorporating knowledge graphs and pre-trained language models, the recommender system can better understand the context and meaning behind a user's requests, and provide more relevant and personalized recommendations.
For example, if a user asks the system for a restaurant recommendation, the knowledge graph could provide information about the user's preferences, dietary restrictions, and past dining experiences. The pre-trained language model could then use this contextual knowledge to have a more natural, human-like conversation with the user and suggest restaurants that are a good fit.
Overall, this research aims to make conversational recommender systems smarter and more effective by leveraging the power of knowledge graphs and pre-trained language models. The key innovation is finding ways to seamlessly integrate these two technologies to enhance the system's understanding and decision-making capabilities.
Technical Explanation
The paper proposes a novel framework that combines knowledge graphs and pre-trained language models to improve the performance of conversational recommender systems.
The core of the framework is a knowledge graph-based representation learning approach. The researchers first construct a knowledge graph from various data sources, such as user profiles, item information, and interaction logs. They then develop a knowledge graph completion technique to enrich the knowledge graph with additional relevant information.
Next, they integrate this knowledge graph-based representation with a pre-trained language model to create a more powerful recommendation engine. The language model is fine-tuned on the conversational data, allowing it to engage in more natural and contextual dialogue with users. The knowledge graph-based representations are then seamlessly incorporated into the language model to enhance its understanding of user preferences and item attributes.
Through extensive experiments, the researchers demonstrate that this framework outperforms several state-of-the-art conversational recommender systems on various evaluation metrics, such as recommendation accuracy, diversity, and user satisfaction. The knowledge graph-enhanced representation learning approach proves to be a key factor in the improved performance.
Critical Analysis
The paper presents a compelling approach to enhancing conversational recommender systems, but there are a few potential limitations and areas for further research:
-
The effectiveness of the framework may be highly dependent on the quality and completeness of the underlying knowledge graph. If the knowledge graph is incomplete or contains inaccurate information, this could negatively impact the system's performance.
-
The paper does not explicitly discuss the scalability of the framework, particularly in terms of handling large-scale knowledge graphs and conversation data. As the size of the data increases, the computational complexity and resource requirements may become a challenge.
-
The authors focus primarily on improving recommendation accuracy and diversity, but there may be other important factors to consider, such as user trust, transparency, and explainability. Further research could explore how the knowledge graph-based approach can be extended to address these aspects.
-
The paper does not provide much insight into the specific techniques used for knowledge graph completion and language model fine-tuning. More details on these key components of the framework would be helpful for a deeper understanding of the underlying methods.
Despite these potential limitations, the overall approach presented in the paper is a promising direction for enhancing conversational recommender systems. The strategic integration of knowledge graphs and pre-trained language models demonstrates the power of combining multiple AI technologies to tackle complex real-world problems.
Conclusion
This paper introduces a novel framework that leverages knowledge graphs and pre-trained language models to improve the performance of conversational recommender systems. The key innovation is the development of a knowledge graph-based representation learning approach that is seamlessly integrated into a pre-trained language model, enabling the system to better understand user preferences and provide more relevant and personalized recommendations.
The experimental results show that this framework outperforms several state-of-the-art conversational recommender systems, highlighting the potential of this approach to enhance the user experience and effectiveness of conversational AI systems. While there are some areas for further research and refinement, this work represents an important step forward in the field of conversational recommender systems and the broader intersection of knowledge representation, natural language processing, and recommendation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

KEHRL: Learning Knowledge-Enhanced Language Representations with Hierarchical Reinforcement Learning
Dongyang Li, Taolin Zhang, Longtao Huang, Chengyu Wang, Xiaofeng He, Hui Xue
0
0
Knowledge-enhanced pre-trained language models (KEPLMs) leverage relation triples from knowledge graphs (KGs) and integrate these external data sources into language models via self-supervised learning. Previous works treat knowledge enhancement as two independent operations, i.e., knowledge injection and knowledge integration. In this paper, we propose to learn Knowledge-Enhanced language representations with Hierarchical Reinforcement Learning (KEHRL), which jointly addresses the problems of detecting positions for knowledge injection and integrating external knowledge into the model in order to avoid injecting inaccurate or irrelevant knowledge. Specifically, a high-level reinforcement learning (RL) agent utilizes both internal and prior knowledge to iteratively detect essential positions in texts for knowledge injection, which filters out less meaningful entities to avoid diverting the knowledge learning direction. Once the entity positions are selected, a relevant triple filtration module is triggered to perform low-level RL to dynamically refine the triples associated with polysemic entities through binary-valued actions. Experiments validate KEHRL's effectiveness in probing factual knowledge and enhancing the model's performance on various natural language understanding tasks.
6/26/2024

New!Large Language Model Enhanced Knowledge Representation Learning: A Survey
Xin Wang, Zirui Chen, Haofen Wang, Leong Hou U, Zhao Li, Wenbin Guo
0
0
The integration of Large Language Models (LLMs) with Knowledge Representation Learning (KRL) signifies a pivotal advancement in the field of artificial intelligence, enhancing the ability to capture and utilize complex knowledge structures. This synergy leverages the advanced linguistic and contextual understanding capabilities of LLMs to improve the accuracy, adaptability, and efficacy of KRL, thereby expanding its applications and potential. Despite the increasing volume of research focused on embedding LLMs within the domain of knowledge representation, a thorough review that examines the fundamental components and processes of these enhanced models is conspicuously absent. Our survey addresses this by categorizing these models based on three distinct Transformer architectures, and by analyzing experimental data from various KRL downstream tasks to evaluate the strengths and weaknesses of each approach. Finally, we identify and explore potential future research directions in this emerging yet underexplored domain, proposing pathways for continued progress.
7/2/2024
💬
Learning Structure and Knowledge Aware Representation with Large Language Models for Concept Recommendation
Qingyao Li, Wei Xia, Kounianhua Du, Qiji Zhang, Weinan Zhang, Ruiming Tang, Yong Yu
0
0
Concept recommendation aims to suggest the next concept for learners to study based on their knowledge states and the human knowledge system. While knowledge states can be predicted using knowledge tracing models, previous approaches have not effectively integrated the human knowledge system into the process of designing these educational models. In the era of rapidly evolving Large Language Models (LLMs), many fields have begun using LLMs to generate and encode text, introducing external knowledge. However, integrating LLMs into concept recommendation presents two urgent challenges: 1) How to construct text for concepts that effectively incorporate the human knowledge system? 2) How to adapt non-smooth, anisotropic text encodings effectively for concept recommendation? In this paper, we propose a novel Structure and Knowledge Aware Representation learning framework for concept Recommendation (SKarREC). We leverage factual knowledge from LLMs as well as the precedence and succession relationships between concepts obtained from the knowledge graph to construct textual representations of concepts. Furthermore, we propose a graph-based adapter to adapt anisotropic text embeddings to the concept recommendation task. This adapter is pre-trained through contrastive learning on the knowledge graph to get a smooth and structure-aware concept representation. Then, it's fine-tuned through the recommendation task, forming a text-to-knowledge-to-recommendation adaptation pipeline, which effectively constructs a structure and knowledge-aware concept representation. Our method does a better job than previous adapters in transforming text encodings for application in concept recommendation. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed approach.
5/22/2024
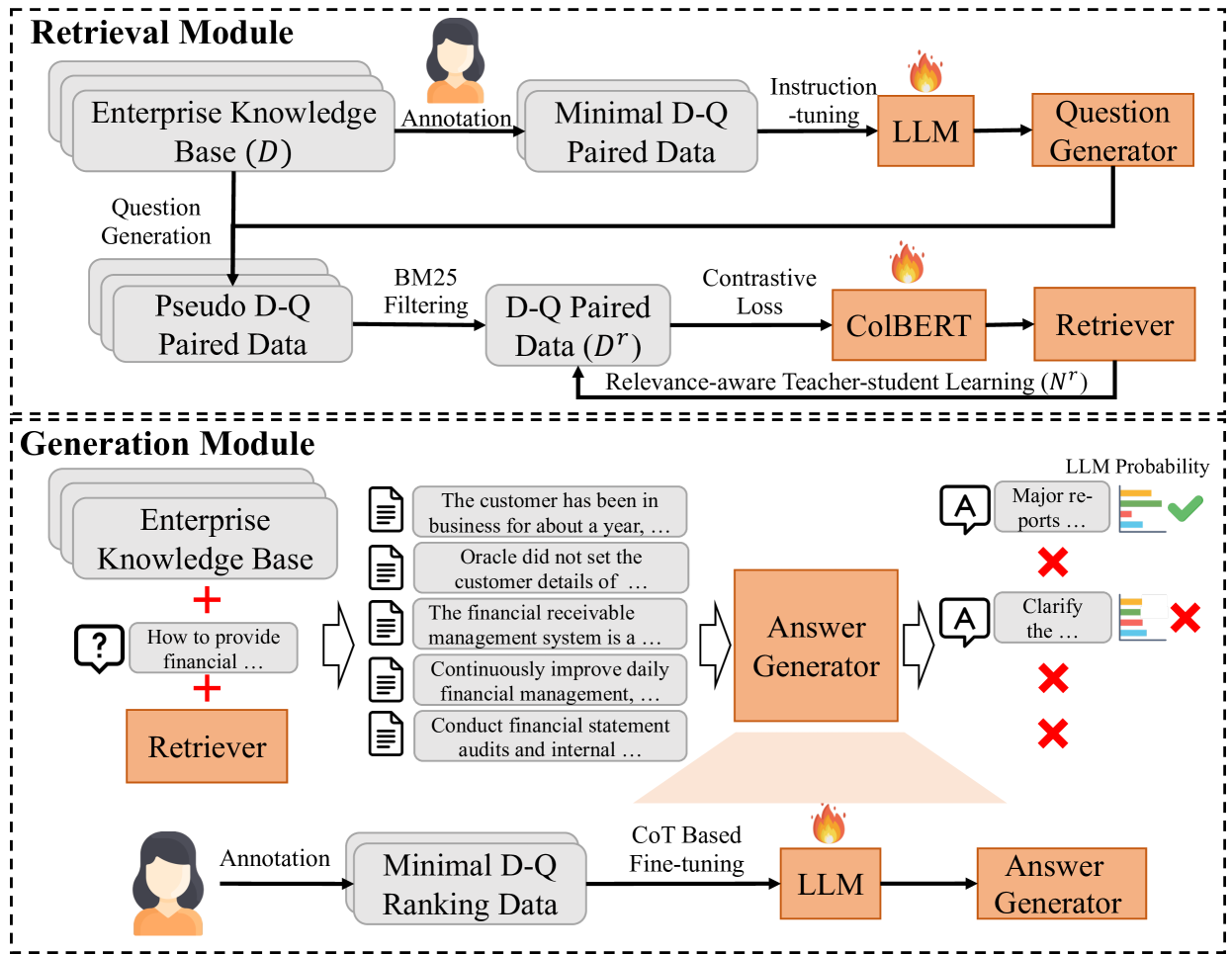
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024