Knowledge Distillation Approaches for Accurate and Efficient Recommender System

0
💬
Sign in to get full access
Overview
- The paper introduces novel knowledge distillation (KD) methods for recommender systems to improve the performance of compact models.
- KD is a technique where a smaller "student" model is trained to mimic a larger "teacher" model, allowing the student to benefit from the teacher's knowledge.
- Previous research has not extensively explored KD for recommendation and ranking problems, which this paper aims to address.
- The proposed KD methods are categorized based on the type of knowledge being transferred: latent knowledge (user/item representations) and ranking knowledge (recommendation results).
Plain English Explanation
In machine learning, there is often a tradeoff between the accuracy of a model and its efficiency (e.g., size, speed). Knowledge distillation is a technique that allows a smaller, more efficient "student" model to learn from a larger, more accurate "teacher" model. This helps the student model perform better without sacrificing too much efficiency.
The authors of this paper noticed that knowledge distillation has not been well-studied for recommendation and ranking problems, where the goal is to suggest relevant items to users. They propose several new methods to distill different types of knowledge from a teacher model to a student model in the context of recommender systems:
-
Latent knowledge: The authors develop techniques to transfer the underlying representations of users and items learned by the teacher model to the student model. This helps the student learn the teacher's understanding of users' niche preferences and how different items are related.
-
Ranking knowledge: The authors formulate the distillation process as a problem of matching the ranking of recommended items produced by the teacher and student models. This allows the student to learn the teacher's ranking strategy, which is an important aspect of recommendation systems.
By using these distillation methods, the authors aim to create more efficient recommender models that can still perform well, providing a better balance between accuracy and computational cost. This could be particularly useful for deploying recommendation systems on resource-constrained devices or in large-scale applications.
Technical Explanation
The paper proposes several novel knowledge distillation methods for recommender systems:
Latent knowledge distillation:
- User/item representation transfer: The authors develop two methods to transfer the latent representations of users and items learned by the teacher model to the student model. This helps the student model capture the teacher's understanding of niche user preferences and item relationships.
- Relation-aware distillation: The authors introduce a new method that selectively transfers the essential user-item relations in the latent representation space, considering the limited capacity of the student model.
Ranking knowledge distillation:
- Listwise ranking distillation: The authors formulate the distillation process as a ranking matching problem and transfer the ranking knowledge from the teacher to the student using a listwise learning strategy.
- Heterogeneous model compression: The authors present a framework to compress the ranking knowledge of multiple heterogeneous recommendation models into a single student model, addressing the computational burden of model ensembling.
The authors validate the effectiveness of their proposed methods through extensive experiments, demonstrating improved accuracy-efficiency tradeoffs for the student recommendation models.
Critical Analysis
The paper makes a valuable contribution by exploring knowledge distillation techniques for recommendation and ranking problems, which have not been well-studied in the past. The proposed methods for transferring latent knowledge and ranking knowledge are novel and show promising results.
However, the paper does not discuss potential limitations or caveats of the proposed approaches. For example, the methods may be sensitive to the choice of teacher and student models, or the distillation process could be prone to certain biases. Additionally, the paper does not explore the scalability of the frameworks, especially the heterogeneous model compression approach, which could be an important consideration for real-world recommender systems.
Further research could investigate the robustness of the distillation methods, their generalizability to different recommendation domains, and the tradeoffs between the various distillation strategies. Analyzing the impact of the distillation process on the interpretability and fairness of the student models could also be an interesting direction for future work.
Conclusion
This paper presents innovative knowledge distillation methods for improving the performance of compact recommendation models. By transferring latent knowledge and ranking knowledge from larger teacher models, the authors demonstrate how to achieve better accuracy-efficiency tradeoffs for recommender systems.
The proposed techniques could have significant practical implications, enabling the deployment of high-performing recommendation models on resource-constrained devices or in large-scale applications. The paper serves as an important step in advancing the state-of-the-art in knowledge distillation for recommendation and ranking problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Knowledge Distillation Approaches for Accurate and Efficient Recommender System
SeongKu Kang
Despite its breakthrough in classification problems, Knowledge distillation (KD) to recommendation models and ranking problems has not been studied well in the previous literature. This dissertation is devoted to developing knowledge distillation methods for recommender systems to fully improve the performance of a compact model. We propose novel distillation methods designed for recommender systems. The proposed methods are categorized according to their knowledge sources as follows: (1) Latent knowledge: we propose two methods that transfer latent knowledge of user/item representation. They effectively transfer knowledge of niche tastes with a balanced distillation strategy that prevents the KD process from being biased towards a small number of large preference groups. Also, we propose a new method that transfers user/item relations in the representation space. The proposed method selectively transfers essential relations considering the limited capacity of the compact model. (2) Ranking knowledge: we propose three methods that transfer ranking knowledge from the recommendation results. They formulate the KD process as a ranking matching problem and transfer the knowledge via a listwise learning strategy. Further, we present a new learning framework that compresses the ranking knowledge of heterogeneous recommendation models. The proposed framework is developed to ease the computational burdens of model ensemble which is a dominant solution for many recommendation applications. We validate the benefit of our proposed methods and frameworks through extensive experiments. To summarize, this dissertation sheds light on knowledge distillation approaches for a better accuracy-efficiency trade-off of the recommendation models.
Read more7/22/2024

0
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
Nikhil Khani, Shuo Yang, Aniruddh Nath, Yang Liu, Pendo Abbo, Li Wei, Shawn Andrews, Maciej Kula, Jarrod Kahn, Zhe Zhao, Lichan Hong, Ed Chi
Knowledge Distillation (KD) is a powerful approach for compressing a large model into a smaller, more efficient model, particularly beneficial for latency-sensitive applications like recommender systems. However, current KD research predominantly focuses on Computer Vision (CV) and NLP tasks, overlooking unique data characteristics and challenges inherent to recommender systems. This paper addresses these overlooked challenges, specifically: (1) mitigating data distribution shifts between teacher and student models, (2) efficiently identifying optimal teacher configurations within time and budgetary constraints, and (3) enabling computationally efficient and rapid sharing of teacher labels to support multiple students. We present a robust KD system developed and rigorously evaluated on multiple large-scale personalized video recommendation systems within Google. Our live experiment results demonstrate significant improvements in student model performance while ensuring consistent and reliable generation of high quality teacher labels from a continuous data stream of data.
Read more8/28/2024
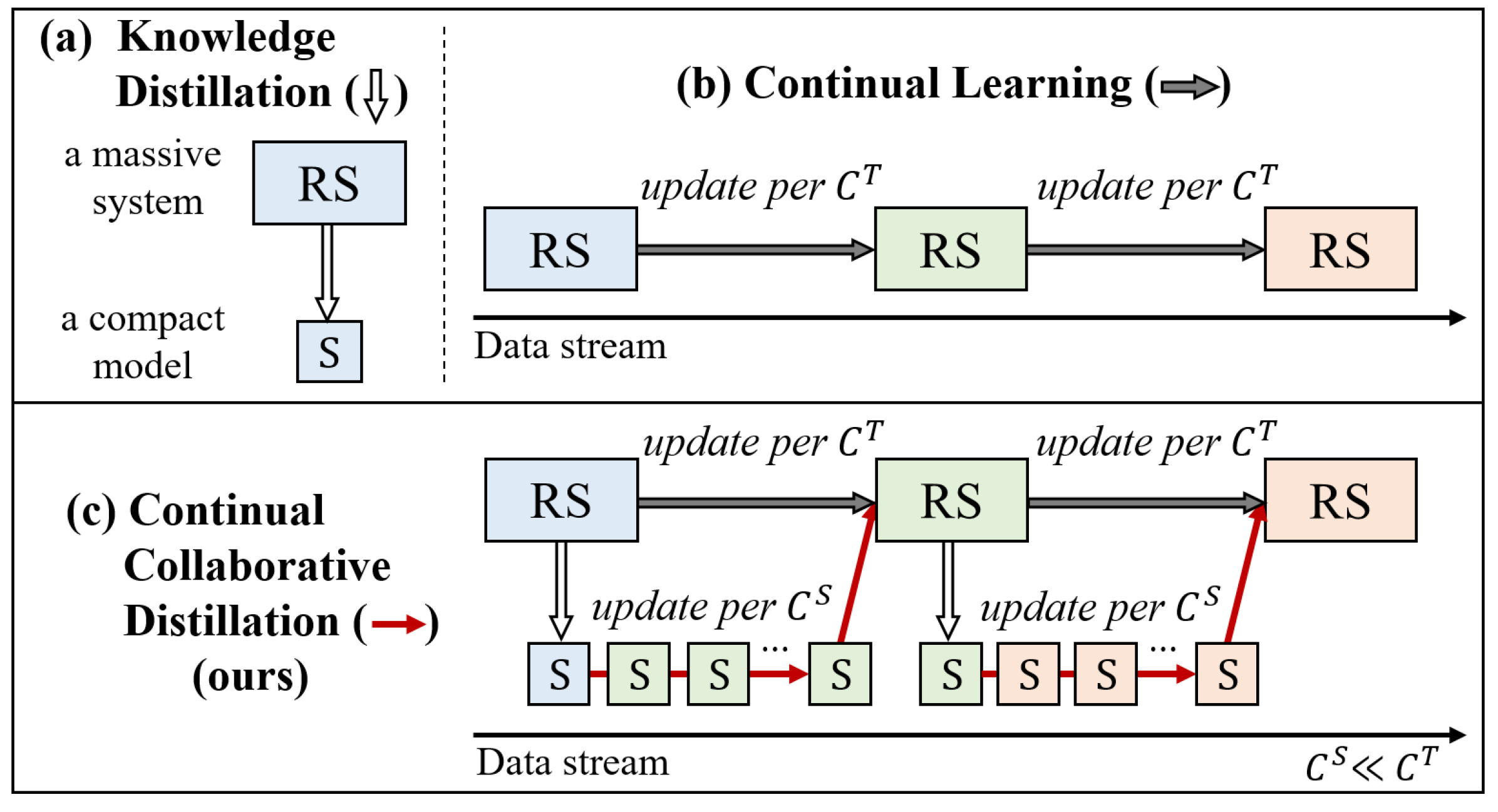
0
Continual Collaborative Distillation for Recommender System
Gyuseok Lee, SeongKu Kang, Wonbin Kweon, Hwanjo Yu
Knowledge distillation (KD) has emerged as a promising technique for addressing the computational challenges associated with deploying large-scale recommender systems. KD transfers the knowledge of a massive teacher system to a compact student model, to reduce the huge computational burdens for inference while retaining high accuracy. The existing KD studies primarily focus on one-time distillation in static environments, leaving a substantial gap in their applicability to real-world scenarios dealing with continuously incoming users, items, and their interactions. In this work, we delve into a systematic approach to operating the teacher-student KD in a non-stationary data stream. Our goal is to enable efficient deployment through a compact student, which preserves the high performance of the massive teacher, while effectively adapting to continuously incoming data. We propose Continual Collaborative Distillation (CCD) framework, where both the teacher and the student continually and collaboratively evolve along the data stream. CCD facilitates the student in effectively adapting to new data, while also enabling the teacher to fully leverage accumulated knowledge. We validate the effectiveness of CCD through extensive quantitative, ablative, and exploratory experiments on two real-world datasets. We expect this research direction to contribute to narrowing the gap between existing KD studies and practical applications, thereby enhancing the applicability of KD in real-world systems.
Read more6/27/2024
🐍
0
Dual Correction Strategy for Ranking Distillation in Top-N Recommender System
Youngjune Lee, Kee-Eung Kim
Knowledge Distillation (KD), which transfers the knowledge of a well-trained large model (teacher) to a small model (student), has become an important area of research for practical deployment of recommender systems. Recently, Relaxed Ranking Distillation (RRD) has shown that distilling the ranking information in the recommendation list significantly improves the performance. However, the method still has limitations in that 1) it does not fully utilize the prediction errors of the student model, which makes the training not fully efficient, and 2) it only distills the user-side ranking information, which provides an insufficient view under the sparse implicit feedback. This paper presents Dual Correction strategy for Distillation (DCD), which transfers the ranking information from the teacher model to the student model in a more efficient manner. Most importantly, DCD uses the discrepancy between the teacher model and the student model predictions to decide which knowledge to be distilled. By doing so, DCD essentially provides the learning guidance tailored to correcting what the student model has failed to accurately predict. This process is applied for transferring the ranking information from the user-side as well as the item-side to address sparse implicit user feedback. Our experiments show that the proposed method outperforms the state-of-the-art baselines, and ablation studies validate the effectiveness of each component.
Read more5/16/2024