Dual Correction Strategy for Ranking Distillation in Top-N Recommender System
2109.03459
0
0
🐍
Abstract
Knowledge Distillation (KD), which transfers the knowledge of a well-trained large model (teacher) to a small model (student), has become an important area of research for practical deployment of recommender systems. Recently, Relaxed Ranking Distillation (RRD) has shown that distilling the ranking information in the recommendation list significantly improves the performance. However, the method still has limitations in that 1) it does not fully utilize the prediction errors of the student model, which makes the training not fully efficient, and 2) it only distills the user-side ranking information, which provides an insufficient view under the sparse implicit feedback. This paper presents Dual Correction strategy for Distillation (DCD), which transfers the ranking information from the teacher model to the student model in a more efficient manner. Most importantly, DCD uses the discrepancy between the teacher model and the student model predictions to decide which knowledge to be distilled. By doing so, DCD essentially provides the learning guidance tailored to correcting what the student model has failed to accurately predict. This process is applied for transferring the ranking information from the user-side as well as the item-side to address sparse implicit user feedback. Our experiments show that the proposed method outperforms the state-of-the-art baselines, and ablation studies validate the effectiveness of each component.
Create account to get full access
Overview
- The paper presents a new method called Dual Correction strategy for Distillation (DCD) to improve knowledge distillation for recommender systems.
- Knowledge distillation is a technique that transfers the knowledge of a large, well-trained model (teacher) to a smaller model (student) to enable practical deployment.
- The authors identify limitations in the state-of-the-art method Relaxed Ranking Distillation (RRD) and propose DCD to address them.
Plain English Explanation
Knowledge distillation is a way to take the knowledge learned by a large, powerful AI model and transfer it to a smaller, more practical model. This is important for real-world applications like recommender systems, where the large model may be too complex to deploy efficiently.
The Relaxed Ranking Distillation (RRD) method has shown that focusing on transferring the ranking information (the order of recommendations) from the teacher to the student model can significantly improve performance. However, RRD has some limitations:
- It doesn't fully utilize the errors made by the student model, so the training process is not as efficient as it could be.
- It only transfers the ranking information from the user's perspective, which is not enough to address the sparsity of implicit user feedback (when users don't explicitly rate or review items).
The new DCD method addresses these issues by:
- Using the differences between the teacher's and student's predictions to guide the distillation process and focus on the areas where the student is struggling.
- Transferring ranking information from both the user's and the item's perspectives to better handle sparse user feedback.
Technical Explanation
The key innovation of the DCD method is its "dual correction" approach. Firstly, DCD uses the discrepancy between the teacher model's and student model's predictions to determine which knowledge should be distilled. This helps the student model learn more efficiently by focusing on the areas where it is making mistakes.
Secondly, DCD transfers ranking information from both the user-side and the item-side. This provides a more comprehensive view of the recommendation task, which is important for addressing the sparsity of implicit user feedback.
The authors evaluate DCD against state-of-the-art baselines, including Relaxed Ranking Distillation (RRD), Accurate Knowledge Distillation for N-Best Re-ranking, and Toward Student-Oriented Teacher Network Training. The results show that DCD outperforms these methods, validating the effectiveness of its dual correction approach.
Critical Analysis
The authors have identified an important limitation in the existing knowledge distillation methods for recommender systems and have proposed a novel solution to address it. The dual correction approach of DCD, which utilizes the student model's prediction errors and considers both user-side and item-side ranking information, is a thoughtful and well-designed innovation.
However, the paper does not discuss the potential computational overhead or training time overhead introduced by the dual correction process. It would be helpful to understand the trade-offs between the performance gains and the added complexity.
Additionally, the authors could have explored how DCD might perform in more diverse recommendation scenarios, such as data upcycling or sequential recommendation tasks. Investigating the generalizability of DCD would strengthen the conclusions and insights.
Conclusion
The DCD method presented in this paper is a significant advancement in the field of knowledge distillation for recommender systems. By addressing the limitations of existing approaches, DCD can help enable the practical deployment of powerful recommendation models while maintaining high performance.
The dual correction strategy, which leverages the student model's prediction errors and transfers ranking information from both user and item perspectives, is a innovative and effective solution. The authors' experimental results demonstrate the superiority of DCD over state-of-the-art baselines, suggesting that it could be a valuable tool for researchers and practitioners working on recommender systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
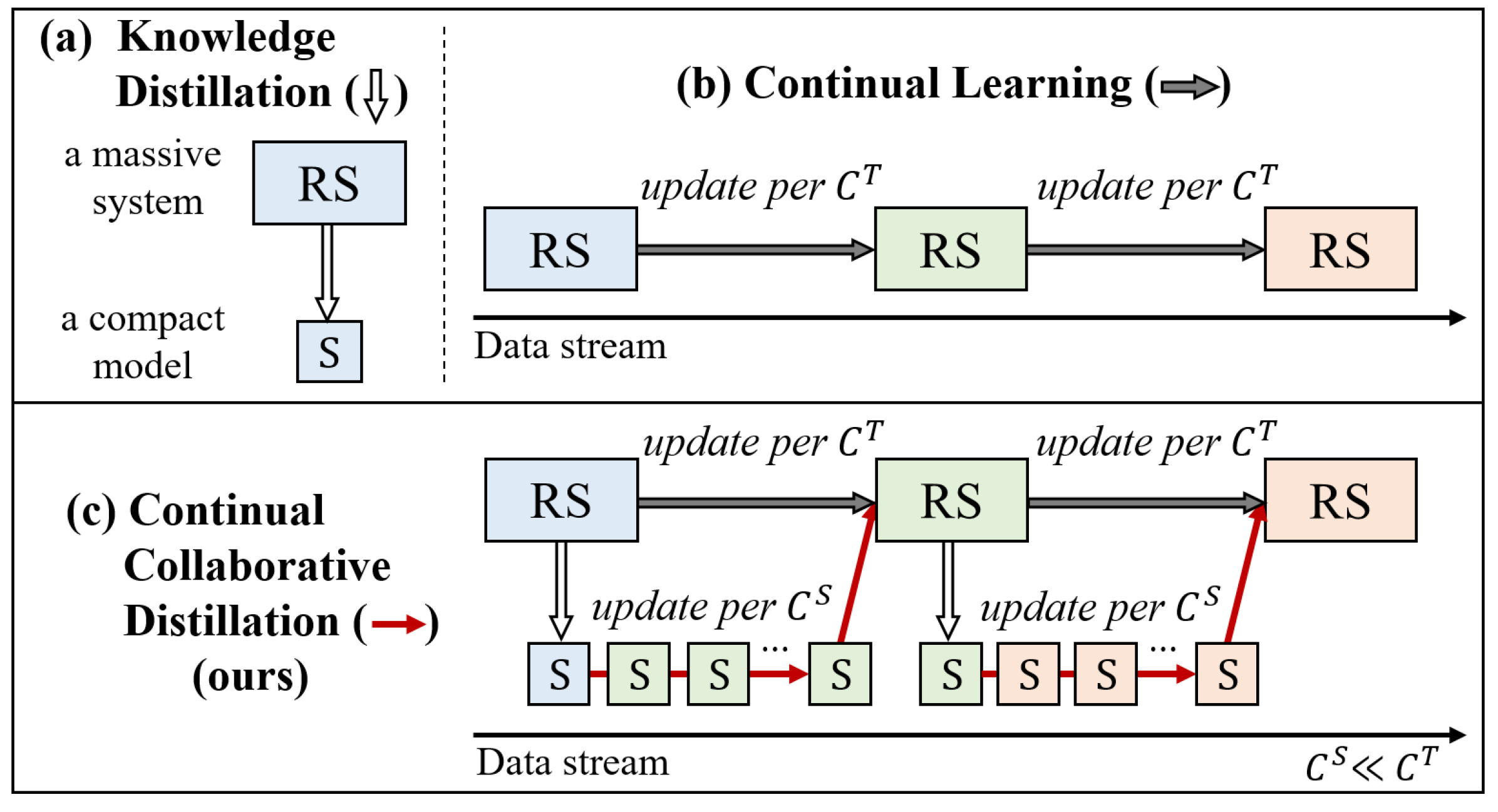
Continual Collaborative Distillation for Recommender System
Gyuseok Lee, SeongKu Kang, Wonbin Kweon, Hwanjo Yu
0
0
Knowledge distillation (KD) has emerged as a promising technique for addressing the computational challenges associated with deploying large-scale recommender systems. KD transfers the knowledge of a massive teacher system to a compact student model, to reduce the huge computational burdens for inference while retaining high accuracy. The existing KD studies primarily focus on one-time distillation in static environments, leaving a substantial gap in their applicability to real-world scenarios dealing with continuously incoming users, items, and their interactions. In this work, we delve into a systematic approach to operating the teacher-student KD in a non-stationary data stream. Our goal is to enable efficient deployment through a compact student, which preserves the high performance of the massive teacher, while effectively adapting to continuously incoming data. We propose Continual Collaborative Distillation (CCD) framework, where both the teacher and the student continually and collaboratively evolve along the data stream. CCD facilitates the student in effectively adapting to new data, while also enabling the teacher to fully leverage accumulated knowledge. We validate the effectiveness of CCD through extensive quantitative, ablative, and exploratory experiments on two real-world datasets. We expect this research direction to contribute to narrowing the gap between existing KD studies and practical applications, thereby enhancing the applicability of KD in real-world systems.
6/27/2024
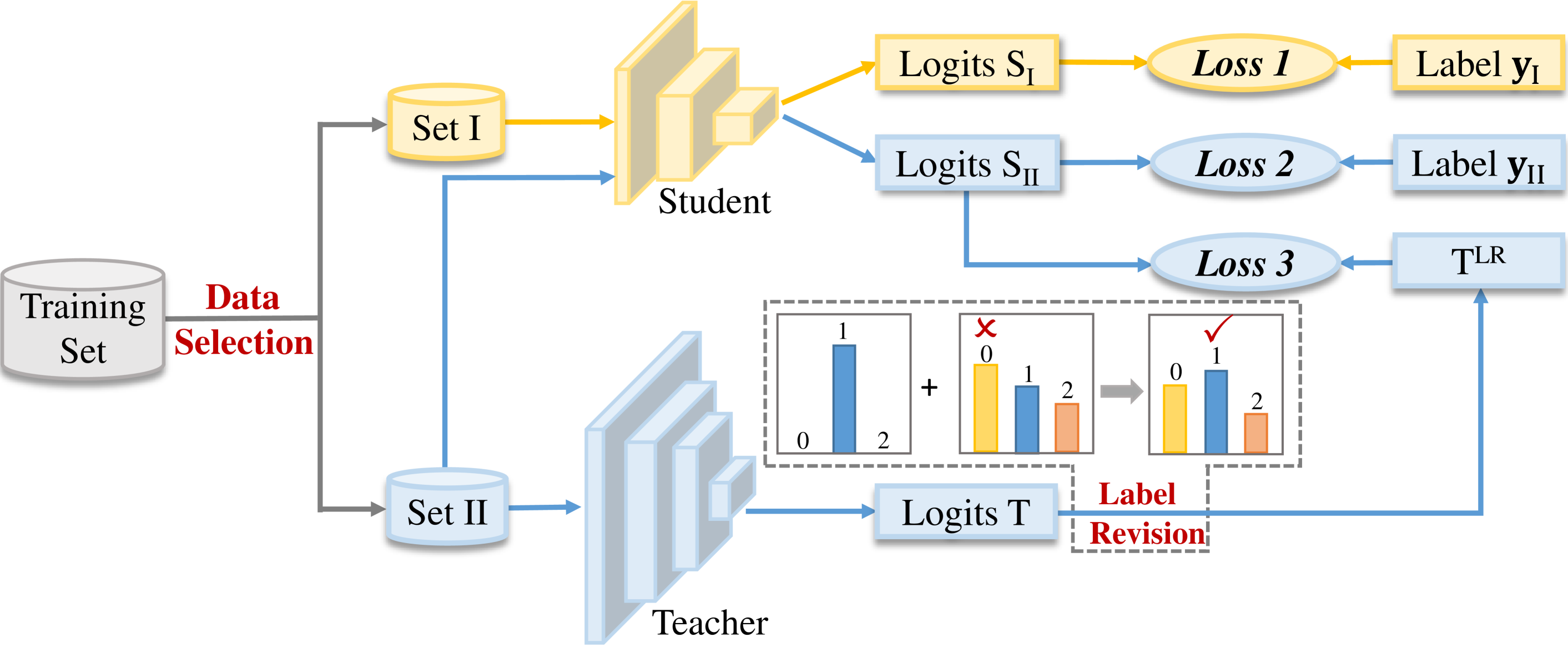
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024
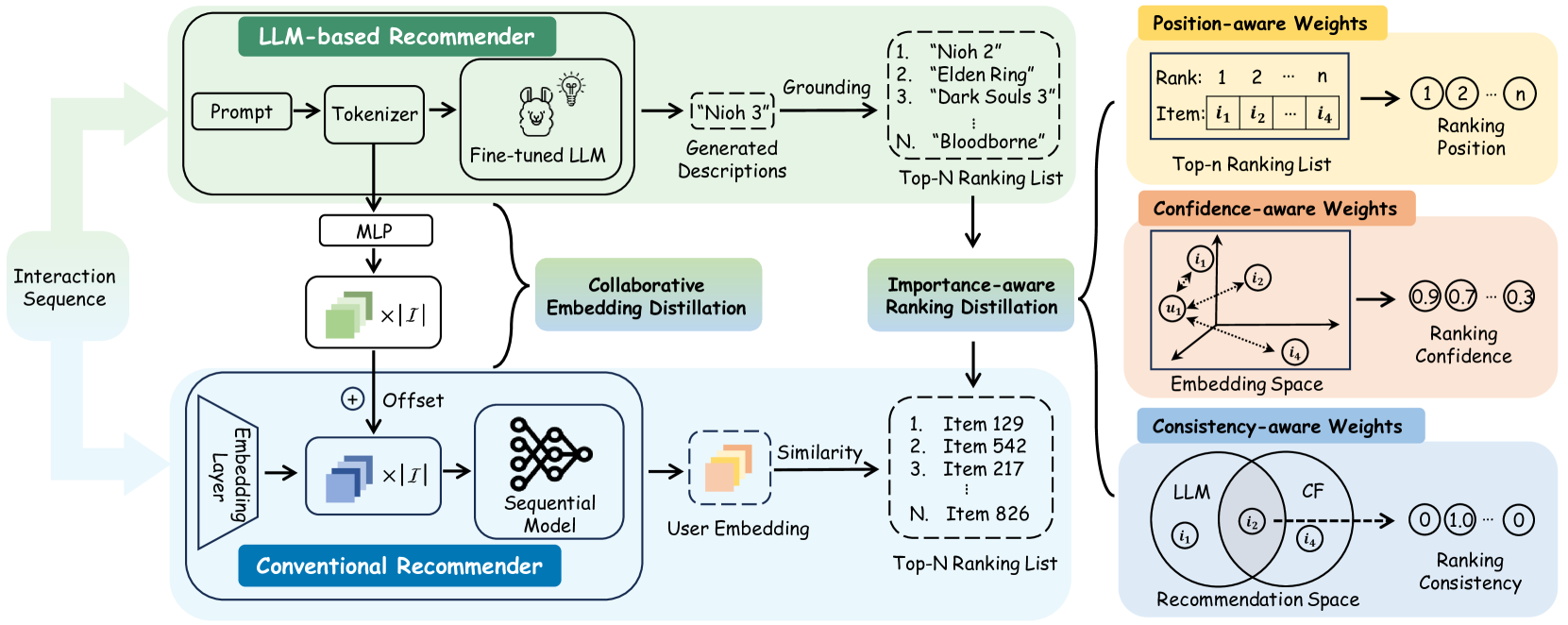
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, Jiawei Chen
0
0
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
5/6/2024
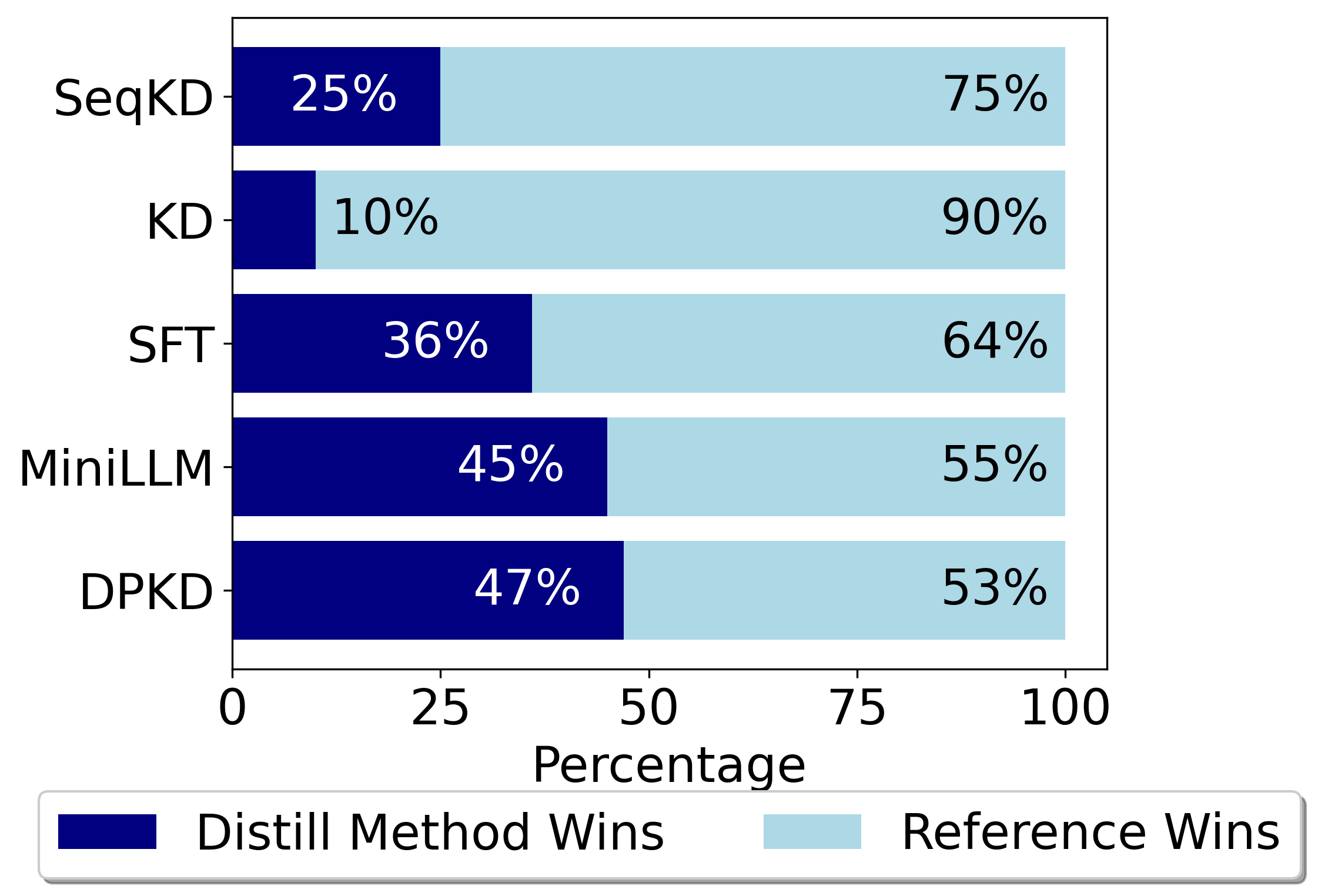
New!Direct Preference Knowledge Distillation for Large Language Models
Yixing Li, Yuxian Gu, Li Dong, Dequan Wang, Yu Cheng, Furu Wei
0
0
In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models. However, existing KD methods face limitations and challenges in distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence. It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function. We re-formulate KD of LLMs into two stages: first optimizing and objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs. We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrate the broad applicability and effectiveness of our DPKD approach. Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage. Code and data are available at https://aka.ms/dpkd.
7/1/2024