Knowledge Distillation with Multi-granularity Mixture of Priors for Image Super-Resolution
2404.02573
0
0

Abstract
Knowledge distillation (KD) is a promising yet challenging model compression technique that transfers rich learning representations from a well-performing but cumbersome teacher model to a compact student model. Previous methods for image super-resolution (SR) mostly compare the feature maps directly or after standardizing the dimensions with basic algebraic operations (e.g. average, dot-product). However, the intrinsic semantic differences among feature maps are overlooked, which are caused by the disparate expressive capacity between the networks. This work presents MiPKD, a multi-granularity mixture of prior KD framework, to facilitate efficient SR model through the feature mixture in a unified latent space and stochastic network block mixture. Extensive experiments demonstrate the effectiveness of the proposed MiPKD method.
Create account to get full access
Overview
- This paper proposes a knowledge distillation model for image super-resolution that uses a mixture of priors at multiple granularity levels.
- The model aims to compress a large and complex teacher model into a smaller and more efficient student model while maintaining high performance.
- The multi-granularity mixture of priors helps the student model learn important features and patterns from the teacher model at different scales.
Plain English Explanation
Image super-resolution is the process of taking a low-resolution image and generating a higher-resolution version of it. This is a challenging task that requires advanced AI models. The authors of this paper have developed a way to make these models more efficient and practical to use.
The key idea is to take a large and powerful "teacher" model that can perform high-quality super-resolution, and distill its knowledge into a smaller and simpler "student" model. This process of knowledge distillation allows the student model to learn the important patterns and features from the teacher, without needing all the complexity of the original model.
To make this knowledge transfer work well, the authors use a mixture of "priors" - essentially, different ways of looking at and representing the image features. These priors are applied at multiple scales or granularity levels, so the student model can learn both the high-level and low-level aspects of super-resolution.
The end result is a compact student model that can deliver impressive super-resolution performance, while being much faster and more efficient to run than the original teacher model. This makes the technology more practical for real-world applications like enhancing photos on mobile devices.
Technical Explanation
The core of the proposed approach is a knowledge distillation framework that transfers knowledge from a large teacher model to a smaller student model. The teacher model is a state-of-the-art super-resolution model with high performance but high complexity.
To distill this knowledge effectively, the authors introduce a "multi-granularity mixture of priors" that helps the student model learn salient features at different scales. Specifically, they use a combination of:
- Pixel-level priors that capture low-level details
- Patch-level priors that capture mid-level textures and patterns
- Image-level priors that capture high-level semantic information
These priors are incorporated into the distillation loss function, encouraging the student model to match the teacher's outputs at multiple granularity levels.
The student model architecture consists of lightweight convolutional and attention-based modules that can efficiently learn and apply these multi-scale priors. Extensive experiments on benchmark super-resolution datasets demonstrate that the student model can achieve performance on par with the teacher, while being significantly more compact and computationally efficient.
Critical Analysis
The authors have thoroughly evaluated their proposed knowledge distillation approach and demonstrated its effectiveness for image super-resolution. The use of multi-granularity priors is a novel and intuitive way to guide the student model's learning, helping it capture both low-level details and high-level semantics from the teacher.
One potential limitation is that the approach may not generalize as well to other computer vision tasks beyond super-resolution. The specific design of the multi-granularity priors and student model architecture were tailored to the super-resolution problem.
Additionally, the paper does not provide much insight into the computational and memory footprint differences between the teacher and student models. While the student model is claimed to be more efficient, the exact tradeoffs are not quantified in detail.
Further research could explore applying this multi-granularity distillation technique to other vision tasks, as well as analyzing the model complexity and speed metrics more extensively. Investigating the transferability of the learned priors across different domains could also yield interesting findings.
Conclusion
This paper presents a compelling approach for compressing large and complex super-resolution models into more efficient student models through knowledge distillation. The key innovation is the use of a multi-granularity mixture of priors, which allows the student to effectively learn important features at multiple scales from the teacher.
The demonstrated performance of the student model, combined with its improved efficiency, suggests this technique could have significant practical value for deploying high-quality super-resolution in real-world applications, such as enhancing photos on mobile devices. The general principles of this work could also inspire further research into efficient and effective model compression methods for other computer vision tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
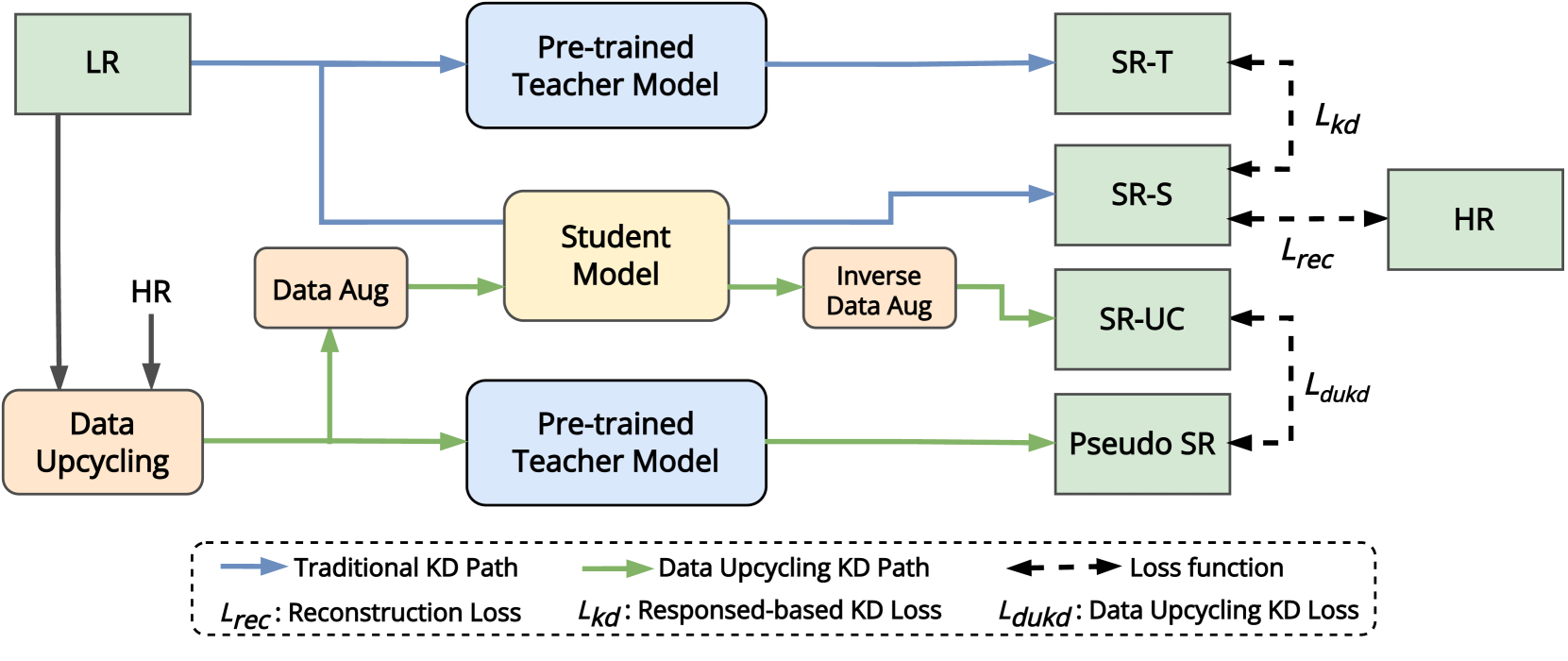
Data Upcycling Knowledge Distillation for Image Super-Resolution
Yun Zhang, Wei Li, Simiao Li, Hanting Chen, Zhijun Tu, Wenjia Wang, Bingyi Jing, Shaohui Lin, Jie Hu
0
0
Knowledge distillation (KD) compresses deep neural networks by transferring task-related knowledge from cumbersome pre-trained teacher models to compact student models. However, current KD methods for super-resolution (SR) networks overlook the nature of SR task that the outputs of the teacher model are noisy approximations to the ground-truth distribution of high-quality images (GT), which shades the teacher model's knowledge to result in limited KD effects. To utilize the teacher model beyond the GT upper-bound, we present the Data Upcycling Knowledge Distillation (DUKD), to transfer the teacher model's knowledge to the student model through the upcycled in-domain data derived from training data. Besides, we impose label consistency regularization to KD for SR by the paired invertible augmentations to improve the student model's performance and robustness. Comprehensive experiments demonstrate that the DUKD method significantly outperforms previous arts on several SR tasks.
4/30/2024

MTKD: Multi-Teacher Knowledge Distillation for Image Super-Resolution
Yuxuan Jiang, Chen Feng, Fan Zhang, David Bull
0
0
Knowledge distillation (KD) has emerged as a promising technique in deep learning, typically employed to enhance a compact student network through learning from their high-performance but more complex teacher variant. When applied in the context of image super-resolution, most KD approaches are modified versions of methods developed for other computer vision tasks, which are based on training strategies with a single teacher and simple loss functions. In this paper, we propose a novel Multi-Teacher Knowledge Distillation (MTKD) framework specifically for image super-resolution. It exploits the advantages of multiple teachers by combining and enhancing the outputs of these teacher models, which then guides the learning process of the compact student network. To achieve more effective learning performance, we have also developed a new wavelet-based loss function for MTKD, which can better optimize the training process by observing differences in both the spatial and frequency domains. We fully evaluate the effectiveness of the proposed method by comparing it to five commonly used KD methods for image super-resolution based on three popular network architectures. The results show that the proposed MTKD method achieves evident improvements in super-resolution performance, up to 0.46dB (based on PSNR), over state-of-the-art KD approaches across different network structures. The source code of MTKD will be made available here for public evaluation.
4/16/2024
✨
Robust feature knowledge distillation for enhanced performance of lightweight crack segmentation models
Zhaohui Chen, Elyas Asadi Shamsabadi, Sheng Jiang, Luming Shen, Daniel Dias-da-Costa
0
0
Vision-based crack detection faces deployment challenges due to the size of robust models and edge device limitations. These can be addressed with lightweight models trained with knowledge distillation (KD). However, state-of-the-art (SOTA) KD methods compromise anti-noise robustness. This paper develops Robust Feature Knowledge Distillation (RFKD), a framework to improve robustness while retaining the precision of light models for crack segmentation. RFKD distils knowledge from a teacher model's logit layers and intermediate feature maps while leveraging mixed clean and noisy images to transfer robust patterns to the student model, improving its precision, generalisation, and anti-noise performance. To validate the proposed RFKD, a lightweight crack segmentation model, PoolingCrack Tiny (PCT), with only 0.5 M parameters, is also designed and used as the student to run the framework. The results show a significant enhancement in noisy images, with RFKD reaching a 62% enhanced mean Dice score (mDS) compared to SOTA KD methods.
4/10/2024
🖼️
Multi-Task Multi-Scale Contrastive Knowledge Distillation for Efficient Medical Image Segmentation
Risab Biswas
0
0
This thesis aims to investigate the feasibility of knowledge transfer between neural networks for medical image segmentation tasks, specifically focusing on the transfer from a larger multi-task Teacher network to a smaller Student network. In the context of medical imaging, where the data volumes are often limited, leveraging knowledge from a larger pre-trained network could be useful. The primary objective is to enhance the performance of a smaller student model by incorporating knowledge representations acquired by a teacher model that adopts a multi-task pre-trained architecture trained on CT images, to a more resource-efficient student network, which can essentially be a smaller version of the same, trained on a mere 50% of the data than that of the teacher model. To facilitate knowledge transfer between the two models, we devised an architecture incorporating multi-scale feature distillation and supervised contrastive learning. Our study aims to improve the student model's performance by integrating knowledge representations from the teacher model. We investigate whether this approach is particularly effective in scenarios with limited computational resources and limited training data availability. To assess the impact of multi-scale feature distillation, we conducted extensive experiments. We also conducted a detailed ablation study to determine whether it is essential to distil knowledge at various scales, including low-level features from encoder layers, for effective knowledge transfer. In addition, we examine different losses in the knowledge distillation process to gain insights into their effects on overall performance.
6/6/2024