Multi-Task Multi-Scale Contrastive Knowledge Distillation for Efficient Medical Image Segmentation
2406.03173
0
0
🖼️
Abstract
This thesis aims to investigate the feasibility of knowledge transfer between neural networks for medical image segmentation tasks, specifically focusing on the transfer from a larger multi-task Teacher network to a smaller Student network. In the context of medical imaging, where the data volumes are often limited, leveraging knowledge from a larger pre-trained network could be useful. The primary objective is to enhance the performance of a smaller student model by incorporating knowledge representations acquired by a teacher model that adopts a multi-task pre-trained architecture trained on CT images, to a more resource-efficient student network, which can essentially be a smaller version of the same, trained on a mere 50% of the data than that of the teacher model. To facilitate knowledge transfer between the two models, we devised an architecture incorporating multi-scale feature distillation and supervised contrastive learning. Our study aims to improve the student model's performance by integrating knowledge representations from the teacher model. We investigate whether this approach is particularly effective in scenarios with limited computational resources and limited training data availability. To assess the impact of multi-scale feature distillation, we conducted extensive experiments. We also conducted a detailed ablation study to determine whether it is essential to distil knowledge at various scales, including low-level features from encoder layers, for effective knowledge transfer. In addition, we examine different losses in the knowledge distillation process to gain insights into their effects on overall performance.
Create account to get full access
Overview
- This thesis investigates the feasibility of knowledge transfer between neural networks for medical image segmentation tasks.
- The focus is on transferring knowledge from a larger multi-task Teacher network to a smaller Student network.
- The primary goal is to enhance the performance of the smaller student model by incorporating knowledge representations from the larger pre-trained teacher model.
- The proposed approach involves multi-scale feature distillation and supervised contrastive learning to facilitate knowledge transfer.
Plain English Explanation
The researchers wanted to see if they could take what a large and complex neural network had learned about analyzing medical images and use that knowledge to improve a smaller, more efficient network. In the medical field, the available data for training these models is often limited, so being able to leverage knowledge from a larger pre-trained network could be very useful.
The key idea is to have a "teacher" network that has been trained on a lot of medical images and has developed a deep understanding of how to analyze them. Then, they try to transfer that knowledge to a smaller "student" network that can be trained on just a fraction of the data. This way, the student network can benefit from the teacher's expertise without needing as much data or computing power.
To do this, the researchers designed a special architecture that combines multi-scale feature distillation and supervised contrastive learning. This allows the student network to learn both high-level and low-level features from the teacher, helping it perform better on the medical image segmentation task.
Technical Explanation
The researchers developed an architecture that incorporates multi-scale feature distillation and supervised contrastive learning to facilitate knowledge transfer from the larger teacher network to the smaller student network.
The multi-scale feature distillation component allows the student network to learn both high-level and low-level features from the teacher model. This is achieved by extracting features at different stages of the teacher's encoder and using them to guide the training of the student's encoder. The researchers hypothesized that this multi-scale approach would be more effective than just distilling features from the final layer of the teacher.
In addition, the supervised contrastive learning component helps the student network learn more discriminative representations by encouraging it to pull together samples from the same class and push apart samples from different classes. This is done by computing similarities between the student's feature representations and the teacher's feature representations.
The researchers conducted extensive experiments to assess the impact of multi-scale feature distillation and to explore the effects of different loss functions in the knowledge distillation process. They also performed a detailed ablation study to determine the importance of distilling knowledge at various scales, including low-level features from the encoder layers.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper. For instance, they mention that the effectiveness of the proposed approach may be influenced by factors such as the complexity of the teacher network, the dataset size, and the task difficulty. Additionally, they suggest exploring more sophisticated knowledge distillation techniques, such as target-aware transformers or multi-teacher knowledge distillation, to further enhance the performance of the student network.
While the researchers provide a comprehensive evaluation of their approach, it would be valuable to see how it performs in more diverse medical imaging scenarios, such as different modalities or disease types. Additionally, a comparison to other knowledge transfer techniques, such as contrastive knowledge distillation, could offer additional insights into the strengths and limitations of the proposed method.
Conclusion
This thesis presents a novel approach to knowledge transfer between neural networks for medical image segmentation tasks. By leveraging multi-scale feature distillation and supervised contrastive learning, the researchers demonstrate the ability to enhance the performance of a smaller student network by incorporating knowledge representations from a larger pre-trained teacher network.
The findings suggest that this approach can be particularly useful in scenarios where computational resources and training data are limited, which is often the case in the medical imaging domain. The insights gained from this research could have significant implications for developing efficient and effective deep learning models for medical image analysis, potentially improving clinical decision-making and patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
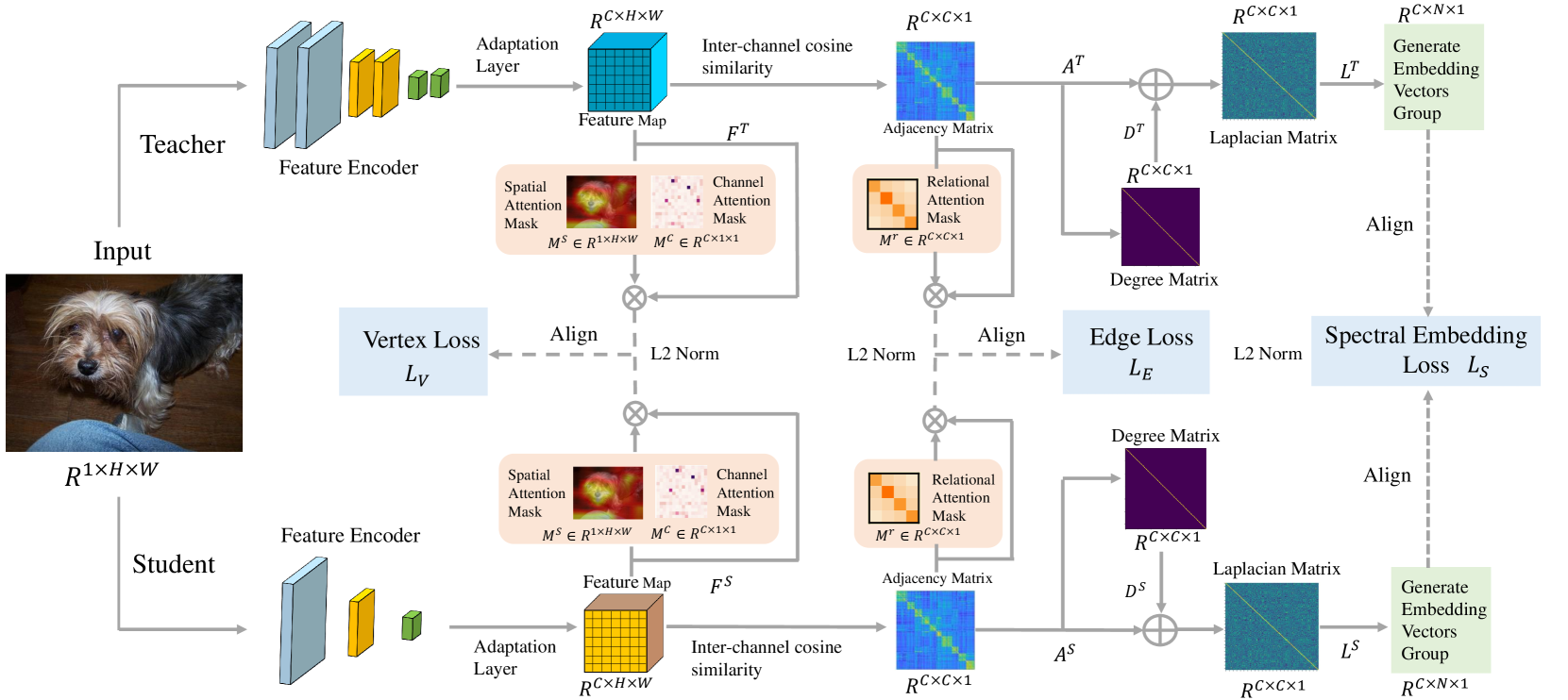
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
0
0
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
5/17/2024
📈
Multiple Teachers-Meticulous Student: A Domain Adaptive Meta-Knowledge Distillation Model for Medical Image Classification
Shahabedin Nabavi, Kian Anvari Hamedani, Mohsen Ebrahimi Moghaddam, Ahmad Ali Abin, Alejandro F. Frangi
0
0
Background: Image classification can be considered one of the key pillars of medical image analysis. Deep learning (DL) faces challenges that prevent its practical applications despite the remarkable improvement in medical image classification. The data distribution differences can lead to a drop in the efficiency of DL, known as the domain shift problem. Besides, requiring bulk annotated data for model training, the large size of models, and the privacy-preserving of patients are other challenges of using DL in medical image classification. This study presents a strategy that can address the mentioned issues simultaneously. Method: The proposed domain adaptive model based on knowledge distillation can classify images by receiving limited annotated data of different distributions. The designed multiple teachers-meticulous student model trains a student network that tries to solve the challenges by receiving the parameters of several teacher networks. The proposed model was evaluated using six available datasets of different distributions by defining the respiratory motion artefact detection task. Results: The results of extensive experiments using several datasets show the superiority of the proposed model in addressing the domain shift problem and lack of access to bulk annotated data. Besides, the privacy preservation of patients by receiving only the teacher network parameters instead of the original data and consolidating the knowledge of several DL models into a model with almost similar performance are other advantages of the proposed model. Conclusions: The proposed model can pave the way for practical clinical applications of deep classification methods by achieving the mentioned objectives simultaneously.
4/10/2024
✨
Knowledge Distillation via the Target-aware Transformer
Sihao Lin, Hongwei Xie, Bing Wang, Kaicheng Yu, Xiaojun Chang, Xiaodan Liang, Gang Wang
0
0
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
4/9/2024

MTKD: Multi-Teacher Knowledge Distillation for Image Super-Resolution
Yuxuan Jiang, Chen Feng, Fan Zhang, David Bull
0
0
Knowledge distillation (KD) has emerged as a promising technique in deep learning, typically employed to enhance a compact student network through learning from their high-performance but more complex teacher variant. When applied in the context of image super-resolution, most KD approaches are modified versions of methods developed for other computer vision tasks, which are based on training strategies with a single teacher and simple loss functions. In this paper, we propose a novel Multi-Teacher Knowledge Distillation (MTKD) framework specifically for image super-resolution. It exploits the advantages of multiple teachers by combining and enhancing the outputs of these teacher models, which then guides the learning process of the compact student network. To achieve more effective learning performance, we have also developed a new wavelet-based loss function for MTKD, which can better optimize the training process by observing differences in both the spatial and frequency domains. We fully evaluate the effectiveness of the proposed method by comparing it to five commonly used KD methods for image super-resolution based on three popular network architectures. The results show that the proposed MTKD method achieves evident improvements in super-resolution performance, up to 0.46dB (based on PSNR), over state-of-the-art KD approaches across different network structures. The source code of MTKD will be made available here for public evaluation.
4/16/2024