Data Upcycling Knowledge Distillation for Image Super-Resolution
2309.14162
0
0
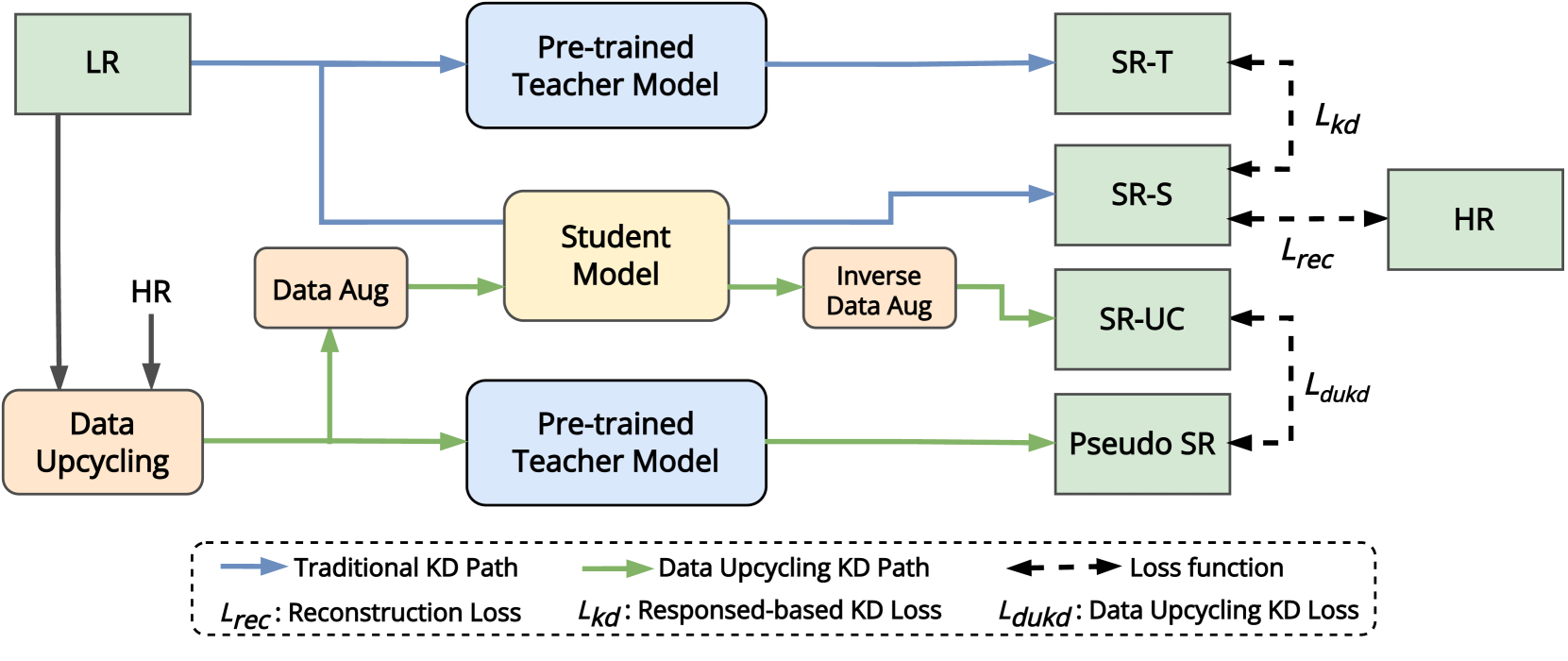
Abstract
Knowledge distillation (KD) compresses deep neural networks by transferring task-related knowledge from cumbersome pre-trained teacher models to compact student models. However, current KD methods for super-resolution (SR) networks overlook the nature of SR task that the outputs of the teacher model are noisy approximations to the ground-truth distribution of high-quality images (GT), which shades the teacher model's knowledge to result in limited KD effects. To utilize the teacher model beyond the GT upper-bound, we present the Data Upcycling Knowledge Distillation (DUKD), to transfer the teacher model's knowledge to the student model through the upcycled in-domain data derived from training data. Besides, we impose label consistency regularization to KD for SR by the paired invertible augmentations to improve the student model's performance and robustness. Comprehensive experiments demonstrate that the DUKD method significantly outperforms previous arts on several SR tasks.
Create account to get full access
Overview
- This paper introduces a new approach called "Data Upcycling Knowledge Distillation" for improving image super-resolution, which is the process of enhancing the resolution and quality of low-resolution images.
- The key idea is to leverage knowledge from pre-trained models to improve the performance of smaller, more efficient super-resolution models.
- The authors demonstrate that this approach can achieve state-of-the-art results on standard image super-resolution benchmarks while using fewer parameters and being computationally more efficient.
Plain English Explanation
Imagine you have a blurry, low-resolution photo that you want to make clearer and sharper. Traditional methods for doing this can be computationally expensive and require a lot of training data.
This paper presents a new technique that aims to solve this problem more efficiently. The core idea is to "distill" or transfer the knowledge from larger, more powerful AI models that have been trained on a lot of data, and use that knowledge to train smaller, more lightweight super-resolution models.
This allows the smaller models to achieve high-quality results without needing to be trained on as much data themselves. It's like taking the "secret sauce" from expert chefs and using it to teach junior chefs how to make gourmet meals more easily.
The authors show that this "data upcycling" approach leads to state-of-the-art performance on standard image super-resolution benchmarks, while using fewer parameters and being more computationally efficient than previous methods. This could make high-quality image upscaling more accessible and practical for a wider range of applications.
Technical Explanation
The paper proposes a "Data Upcycling Knowledge Distillation" (DUKD) framework for image super-resolution. The key components are:
- Teacher Model: A large, high-capacity "teacher" model is first trained on a large dataset to learn a high-quality super-resolution function.
- Student Model: A smaller, more efficient "student" model is then trained to mimic the behavior of the teacher model, rather than being trained from scratch on the original data.
- Knowledge Distillation: The student model is trained to match the output feature maps and predictions of the teacher model, in addition to the ground truth high-resolution images. This allows the student to learn an efficient approximation of the teacher's super-resolution capability.
The authors experiment with different architectures for the teacher and student models, as well as various knowledge distillation techniques. They evaluate the approach on standard image super-resolution benchmarks and demonstrate state-of-the-art results, while using significantly fewer parameters and being more computationally efficient than prior methods.
Critical Analysis
A key strength of this approach is its ability to leverage the knowledge of large, high-quality models to train smaller, more efficient super-resolution models. This could make high-quality image upscaling more accessible, as the computational and data requirements are reduced.
However, the paper does not address the potential limitations of this approach. For example, the performance of the student model is still dependent on the quality of the teacher model, and issues with the teacher model could be propagated to the student. Additionally, the paper does not explore the sensitivity of the approach to the choice of teacher and student architectures, or the impact of different knowledge distillation techniques.
Further research could investigate these areas, as well as explore the applicability of the "data upcycling" concept to other computer vision tasks beyond super-resolution. Rigorous testing on a wider range of datasets and real-world scenarios would also help validate the practical utility of this approach.
Conclusion
This paper presents an innovative "Data Upcycling Knowledge Distillation" framework for image super-resolution that leverages the knowledge of large, pre-trained models to train smaller, more efficient super-resolution models. The authors demonstrate state-of-the-art results on standard benchmarks, while using significantly fewer parameters and being more computationally efficient than previous methods.
This approach has the potential to make high-quality image upscaling more accessible and practical for a wide range of applications, from photography to video processing to medical imaging. By reducing the computational and data requirements, the "data upcycling" concept could unlock new opportunities for deploying advanced computer vision technologies in resource-constrained environments.
Overall, this research represents an important step forward in the field of image super-resolution, and the ideas presented could have broader implications for knowledge transfer and efficient model design in other areas of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Knowledge Distillation with Multi-granularity Mixture of Priors for Image Super-Resolution
Simiao Li, Yun Zhang, Wei Li, Hanting Chen, Wenjia Wang, Bingyi Jing, Shaohui Lin, Jie Hu
0
0
Knowledge distillation (KD) is a promising yet challenging model compression technique that transfers rich learning representations from a well-performing but cumbersome teacher model to a compact student model. Previous methods for image super-resolution (SR) mostly compare the feature maps directly or after standardizing the dimensions with basic algebraic operations (e.g. average, dot-product). However, the intrinsic semantic differences among feature maps are overlooked, which are caused by the disparate expressive capacity between the networks. This work presents MiPKD, a multi-granularity mixture of prior KD framework, to facilitate efficient SR model through the feature mixture in a unified latent space and stochastic network block mixture. Extensive experiments demonstrate the effectiveness of the proposed MiPKD method.
4/4/2024

MTKD: Multi-Teacher Knowledge Distillation for Image Super-Resolution
Yuxuan Jiang, Chen Feng, Fan Zhang, David Bull
0
0
Knowledge distillation (KD) has emerged as a promising technique in deep learning, typically employed to enhance a compact student network through learning from their high-performance but more complex teacher variant. When applied in the context of image super-resolution, most KD approaches are modified versions of methods developed for other computer vision tasks, which are based on training strategies with a single teacher and simple loss functions. In this paper, we propose a novel Multi-Teacher Knowledge Distillation (MTKD) framework specifically for image super-resolution. It exploits the advantages of multiple teachers by combining and enhancing the outputs of these teacher models, which then guides the learning process of the compact student network. To achieve more effective learning performance, we have also developed a new wavelet-based loss function for MTKD, which can better optimize the training process by observing differences in both the spatial and frequency domains. We fully evaluate the effectiveness of the proposed method by comparing it to five commonly used KD methods for image super-resolution based on three popular network architectures. The results show that the proposed MTKD method achieves evident improvements in super-resolution performance, up to 0.46dB (based on PSNR), over state-of-the-art KD approaches across different network structures. The source code of MTKD will be made available here for public evaluation.
4/16/2024
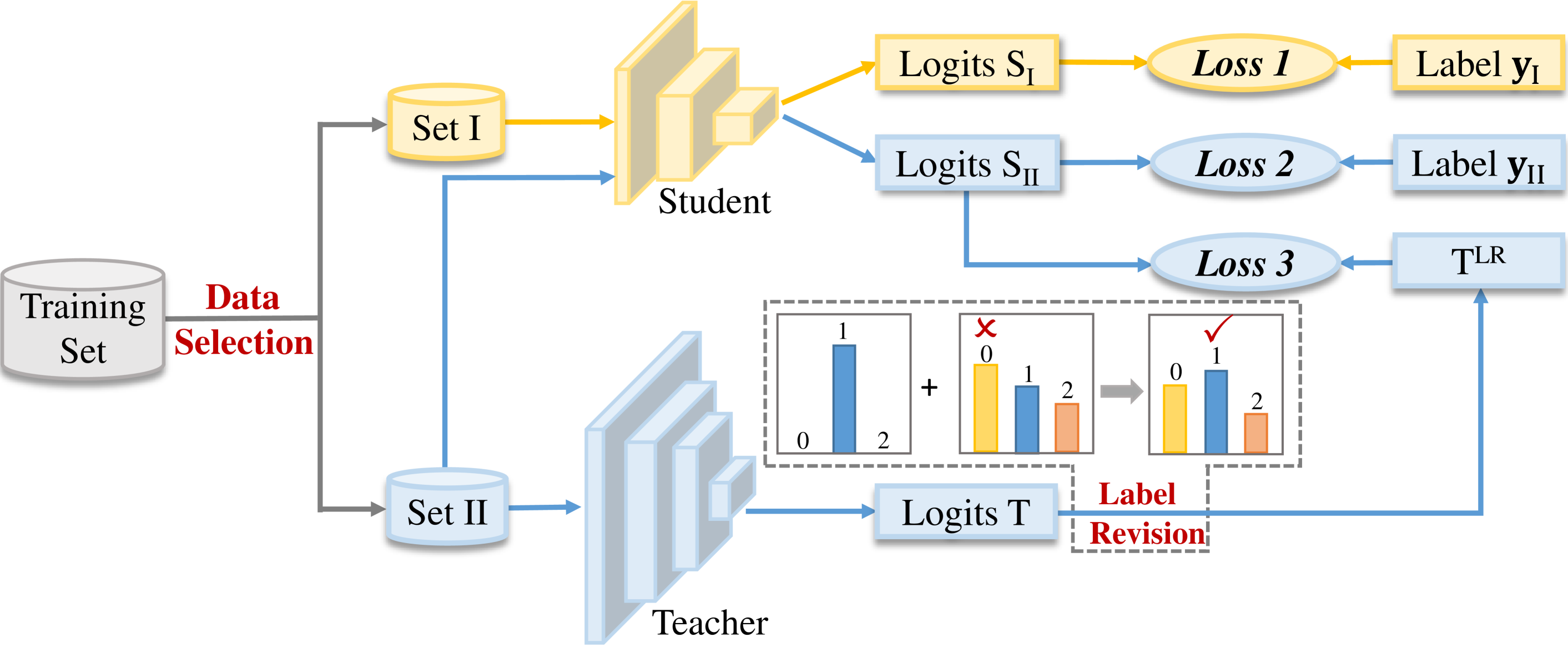
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024
🔮
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jordy Van Landeghem, Subhajit Maity, Ayan Banerjee, Matthew Blaschko, Marie-Francine Moens, Josep Llad'os, Sanket Biswas
0
0
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
6/13/2024