A Knowledge-Enhanced Disease Diagnosis Method Based on Prompt Learning and BERT Integration

0

Sign in to get full access
Overview
- This paper presents a knowledge-enhanced disease diagnosis method that combines prompt learning and BERT integration.
- The goal is to improve disease diagnosis accuracy by leveraging medical knowledge in addition to text-based patient data.
- The method involves using prompts to guide a BERT-based language model to integrate relevant medical knowledge during the diagnosis process.
Plain English Explanation
The researchers developed a new approach to help doctors diagnose diseases more accurately. Traditionally, doctors have relied on the information patients provide, like their symptoms and medical history. This new method aims to also incorporate medical knowledge that doctors have learned, in order to make better diagnoses.
The key idea is to use prompt learning - providing the AI system with guiding questions or instructions - to help it understand and apply relevant medical knowledge when analyzing a patient's case. This is combined with a BERT language model, which is trained on a large amount of text data and can pick up on important patterns and relationships.
By blending the patient information with medical knowledge through prompt learning, the researchers hope the system can make more accurate disease diagnoses, similar to how a knowledgeable doctor would approach a case. This could potentially help healthcare providers make better decisions and provide better care for patients.
Technical Explanation
The paper proposes a knowledge-enhanced disease diagnosis method that combines prompt learning and BERT integration. The key components are:
-
Prompt Engineering: The researchers design prompts that guide the language model to incorporate relevant medical knowledge during the diagnosis process. These prompts frame the task in a way that encourages the model to draw connections between the patient information and medical concepts.
-
BERT Integration: The system uses a BERT-based language model that has been pre-trained on a large corpus of text data, including medical literature. This provides the model with a strong foundation of general and domain-specific knowledge.
-
Knowledge Fusion: The prompts are used to condition the BERT model, allowing it to selectively retrieve and apply the most relevant medical knowledge to the given patient case. This knowledge-enhanced diagnosis approach aims to improve classification accuracy compared to using just the patient text data alone.
The researchers evaluate their method on a disease diagnosis dataset and report improvements over baseline BERT models that do not use the prompt learning approach. This demonstrates the potential of combining language models with targeted medical knowledge to enhance healthcare decision support systems.
Critical Analysis
The paper provides a promising approach to improving disease diagnosis by integrating medical knowledge with language models. However, a few potential limitations and areas for further research are worth considering:
-
Dataset Generalization: The evaluation is conducted on a single dataset, so it's unclear how well the method would generalize to a wider range of medical conditions and patient populations. Further testing on diverse datasets would be helpful.
-
Prompt Design: The effectiveness of the prompt learning aspect relies heavily on the quality and relevance of the prompts engineered by the researchers. Developing systematic prompt design methodologies could improve the generalizability of the approach.
-
Explainability: As with many AI-based systems, the internal reasoning of the knowledge-enhanced diagnosis model may not be fully transparent. Exploring ways to increase the explainability of the decisions could build trust and facilitate integration into clinical workflows.
-
Real-world Validation: While the paper demonstrates improvements in a controlled experimental setting, evaluating the method's performance in real-world clinical environments with practicing healthcare providers would be an important next step.
Overall, this research represents a promising step towards enhancing biomedical knowledge discovery for diseases and developing more intelligent disease diagnosis assistants. Further advancements in this direction could lead to significant improvements in healthcare outcomes.
Conclusion
The proposed knowledge-enhanced disease diagnosis method combines prompt learning and BERT integration to leverage medical knowledge and improve the accuracy of disease classification. By guiding a language model to selectively apply relevant medical concepts, the system can make more informed decisions compared to approaches that rely solely on patient text data.
While the initial results are promising, further research is needed to assess the method's generalizability, explainability, and real-world clinical viability. Nonetheless, this work represents an important step towards enhancing source code classification effectiveness and developing more intelligent healthcare decision support systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!A Knowledge-Enhanced Disease Diagnosis Method Based on Prompt Learning and BERT Integration
Zhang Zheng
This paper proposes a knowledge-enhanced disease diagnosis method based on a prompt learning framework. The method retrieves structured knowledge from external knowledge graphs related to clinical cases, encodes it, and injects it into the prompt templates to enhance the language model's understanding and reasoning capabilities for the task.We conducted experiments on three public datasets: CHIP-CTC, IMCS-V2-NER, and KUAKE-QTR. The results show that the proposed method significantly outperforms existing models across multiple evaluation metrics, with an F1 score improvement of 2.4% on the CHIP-CTC dataset, 3.1% on the IMCS-V2-NER dataset,and 4.2% on the KUAKE-QTR dataset. Additionally,ablation studies confirmed the critical role of the knowledge injection module,as the removal of this module resulted in a significant drop in F1 score. The experimental results demonstrate that the proposed method not only effectively improves the accuracy of disease diagnosis but also enhances the interpretability of the predictions, providing more reliable support and evidence for clinical diagnosis.
Read more9/17/2024

0
Towards Knowledge-Infused Automated Disease Diagnosis Assistant
Mohit Tomar, Abhisek Tiwari, Sriparna Saha
With the advancement of internet communication and telemedicine, people are increasingly turning to the web for various healthcare activities. With an ever-increasing number of diseases and symptoms, diagnosing patients becomes challenging. In this work, we build a diagnosis assistant to assist doctors, which identifies diseases based on patient-doctor interaction. During diagnosis, doctors utilize both symptomatology knowledge and diagnostic experience to identify diseases accurately and efficiently. Inspired by this, we investigate the role of medical knowledge in disease diagnosis through doctor-patient interaction. We propose a two-channel, knowledge-infused, discourse-aware disease diagnosis model (KI-DDI), where the first channel encodes patient-doctor communication using a transformer-based encoder, while the other creates an embedding of symptom-disease using a graph attention network (GAT). In the next stage, the conversation and knowledge graph embeddings are infused together and fed to a deep neural network for disease identification. Furthermore, we first develop an empathetic conversational medical corpus comprising conversations between patients and doctors, annotated with intent and symptoms information. The proposed model demonstrates a significant improvement over the existing state-of-the-art models, establishing the crucial roles of (a) a doctor's effort for additional symptom extraction (in addition to patient self-report) and (b) infusing medical knowledge in identifying diseases effectively. Many times, patients also show their medical conditions, which acts as crucial evidence in diagnosis. Therefore, integrating visual sensory information would represent an effective avenue for enhancing the capabilities of diagnostic assistants.
Read more5/21/2024

0
Enhancing Biomedical Knowledge Discovery for Diseases: An End-To-End Open-Source Framework
Christos Theodoropoulos, Andrei Catalin Coman, James Henderson, Marie-Francine Moens
The ever-growing volume of biomedical publications creates a critical need for efficient knowledge discovery. In this context, we introduce an open-source end-to-end framework designed to construct knowledge around specific diseases directly from raw text. To facilitate research in disease-related knowledge discovery, we create two annotated datasets focused on Rett syndrome and Alzheimer's disease, enabling the identification of semantic relations between biomedical entities. Extensive benchmarking explores various ways to represent relations and entity representations, offering insights into optimal modeling strategies for semantic relation detection and highlighting language models' competence in knowledge discovery. We also conduct probing experiments using different layer representations and attention scores to explore transformers' ability to capture semantic relations.
Read more9/9/2024
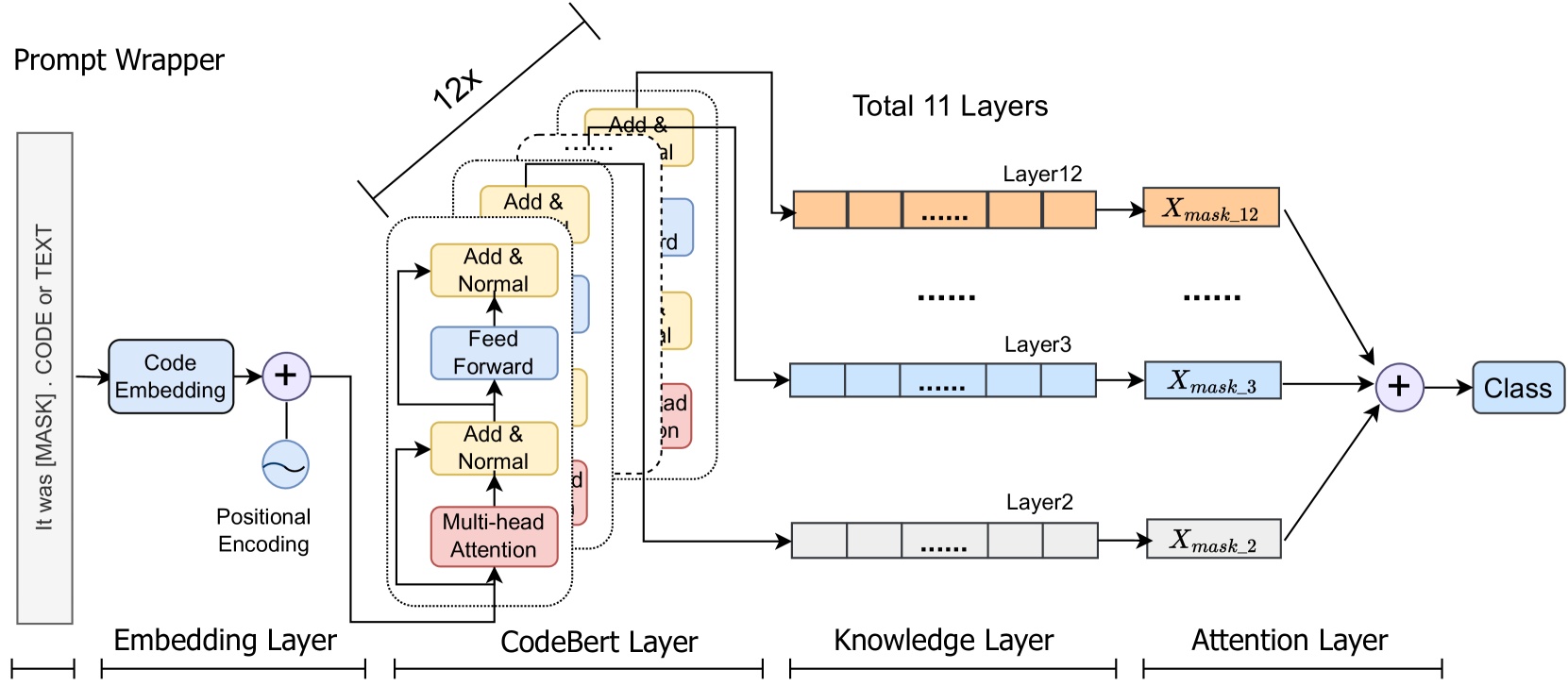
0
Enhancing Source Code Classification Effectiveness via Prompt Learning Incorporating Knowledge Features
Yong Ma, Senlin Luo, Yu-Ming Shang, Yifei Zhang, Zhengjun Li
Researchers have investigated the potential of leveraging pre-trained language models, such as CodeBERT, to enhance source code-related tasks. Previous methodologies have relied on CodeBERT's '[CLS]' token as the embedding representation of input sequences for task performance, necessitating additional neural network layers to enhance feature representation, which in turn increases computational expenses. These approaches have also failed to fully leverage the comprehensive knowledge inherent within the source code and its associated text, potentially limiting classification efficacy. We propose CodeClassPrompt, a text classification technique that harnesses prompt learning to extract rich knowledge associated with input sequences from pre-trained models, thereby eliminating the need for additional layers and lowering computational costs. By applying an attention mechanism, we synthesize multi-layered knowledge into task-specific features, enhancing classification accuracy. Our comprehensive experimentation across four distinct source code-related tasks reveals that CodeClassPrompt achieves competitive performance while significantly reducing computational overhead.
Read more8/21/2024