Enhancing Source Code Classification Effectiveness via Prompt Learning Incorporating Knowledge Features

0
Sign in to get full access
Overview
- This paper proposes a novel approach called "CodePrompt" to improve source code-related classification tasks using prompt learning and knowledge features.
- The key ideas are to leverage language models and incorporate domain-specific knowledge to enhance the performance of source code classification models.
- The authors demonstrate the effectiveness of their approach on several benchmarks, showing improvements over existing techniques.
Plain English Explanation
The researchers developed a new method called "CodePrompt" to make it easier for machine learning models to classify different types of source code. Source code is the set of instructions that tell a computer how to perform a specific task, and it can be written in many different programming languages.
Often, machine learning models struggle to accurately classify source code because it can be complex and technical. The CodePrompt approach aims to address this by combining language models (which are good at understanding natural language) with additional knowledge about programming concepts and code structure.
The key insight is that providing the model with relevant background information, like common programming patterns or definitions of coding terms, can help it better understand and classify the source code. The researchers tested their method on several standard datasets and found that it outperformed existing techniques.
This work is important because accurate classification of source code has many practical applications, like automatically organizing and searching large code repositories, or providing better tools for software developers. By making classification models more robust, the CodePrompt approach could unlock new capabilities in areas like code analysis and software engineering.
Technical Explanation
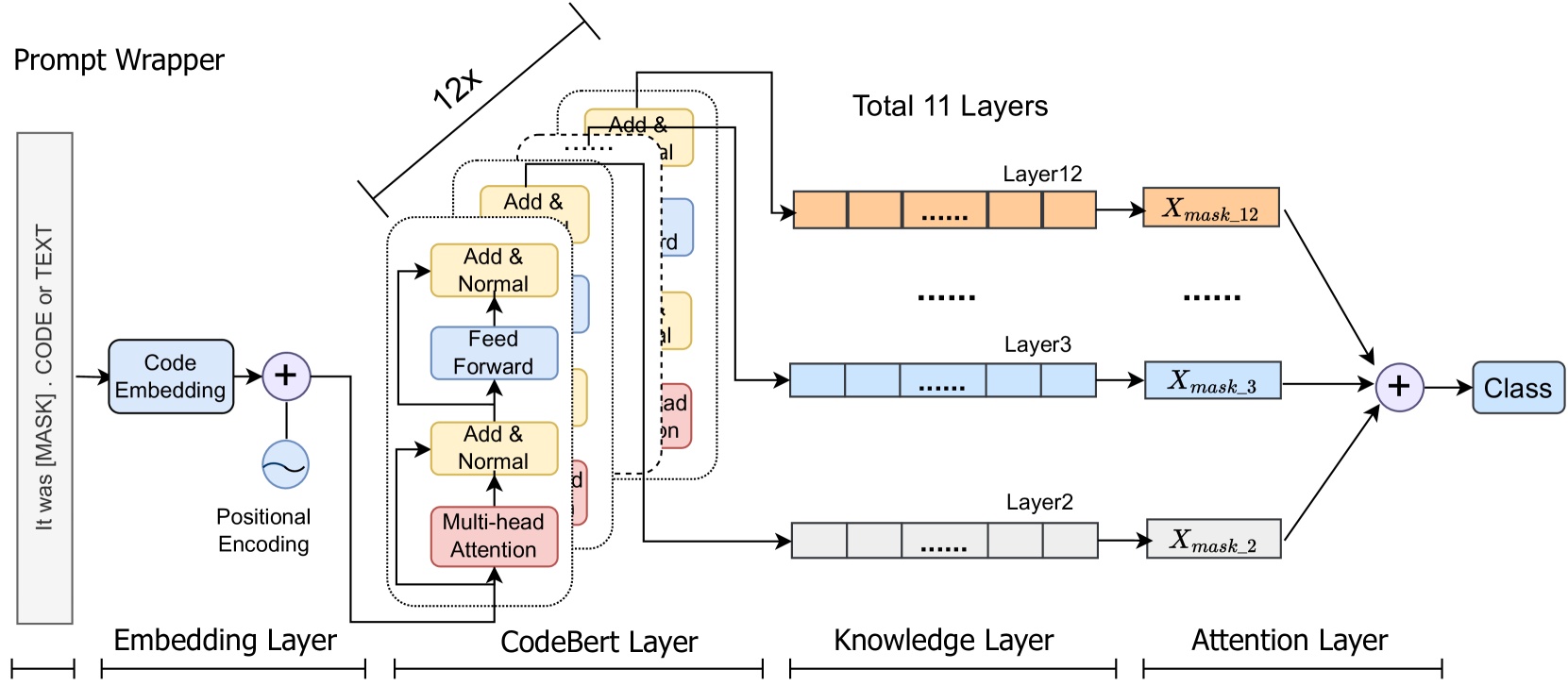
The core idea of the CodePrompt method is to leverage large language models (like BERT or GPT) and combine them with domain-specific knowledge features to improve the performance of source code classification tasks. The authors hypothesize that incorporating relevant programming concepts and code structures can help the model better understand and categorize different types of source code.
The CodePrompt architecture consists of three main components:
- Prompt Engineering: The authors design prompts that incorporate programming-related knowledge, such as definitions of coding terms, common code patterns, and programming language features. These prompts are used to condition the language model and guide its understanding of the input source code.
- Knowledge Features: In addition to the raw source code, the model is also provided with a set of knowledge features that capture relevant domain information. This includes variables like code length, variable names, function calls, and other structural attributes.
- Classifier Head: The final component is a classification layer that takes the language model's output and the knowledge features as input, and produces the predicted class label for the source code.
The authors evaluate their CodePrompt approach on several standard benchmarks for source code classification, including tasks like identifying the programming language, code functionality, and code difficulty level. They compare against various baselines, including models that use only the raw source code, as well as prior work that incorporates some domain knowledge.
The results show that the CodePrompt method consistently outperforms these baselines, demonstrating the value of combining large language models with targeted domain knowledge to improve classification performance. The authors provide detailed analyses and ablation studies to better understand the contributions of the different components.
Critical Analysis
The CodePrompt approach presents a compelling way to leverage the power of language models and domain knowledge for source code classification tasks. The authors make a strong case for the importance of incorporating relevant programming concepts and code structures to help the model better understand and categorize different types of source code.
One potential limitation of the work is the reliance on manually-designed prompts and knowledge features. While this allows for the direct incorporation of domain expertise, it may be difficult to scale or generalize the approach to new tasks or datasets. An interesting direction for future research could be to explore more automated or dynamic ways of generating the prompts and selecting the relevant knowledge features.
Additionally, the paper does not delve deeply into the characteristics or limitations of the language models themselves. It would be valuable to understand how the choice of base model (e.g., BERT vs. GPT) or the model size might impact the performance and generalization of the CodePrompt approach.
Overall, this work represents an important step forward in improving the performance of source code classification models. The CodePrompt approach demonstrates the potential of combining large language models with domain-specific knowledge, and the insights from this research could inspire further advancements in the field of program understanding and analysis.
Conclusion
The CodePrompt paper presents a novel method for improving source code-related classification tasks by leveraging language models and incorporating domain-specific knowledge features. The key contribution is the demonstration that providing relevant programming concepts and code structures can significantly boost the performance of classification models compared to using just the raw source code.
This work has important implications for a variety of applications in software engineering and program analysis, such as automatic code organization, code search, and developer assistance tools. By making classification models more robust and accurate, the CodePrompt approach could unlock new capabilities in these domains and help streamline the software development process.
While the current implementation relies on manual prompt engineering and feature selection, future research could explore more automated or adaptive ways of incorporating domain knowledge. Investigating the interplay between language model choices and the CodePrompt architecture is another promising direction for extending this work.
Overall, the CodePrompt paper represents an exciting step forward in the field of source code understanding, showcasing the potential of combining large language models with domain-specific knowledge to tackle complex programming-related tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Source Code Classification Effectiveness via Prompt Learning Incorporating Knowledge Features
Yong Ma, Senlin Luo, Yu-Ming Shang, Yifei Zhang, Zhengjun Li
Researchers have investigated the potential of leveraging pre-trained language models, such as CodeBERT, to enhance source code-related tasks. Previous methodologies have relied on CodeBERT's '[CLS]' token as the embedding representation of input sequences for task performance, necessitating additional neural network layers to enhance feature representation, which in turn increases computational expenses. These approaches have also failed to fully leverage the comprehensive knowledge inherent within the source code and its associated text, potentially limiting classification efficacy. We propose CodeClassPrompt, a text classification technique that harnesses prompt learning to extract rich knowledge associated with input sequences from pre-trained models, thereby eliminating the need for additional layers and lowering computational costs. By applying an attention mechanism, we synthesize multi-layered knowledge into task-specific features, enhancing classification accuracy. Our comprehensive experimentation across four distinct source code-related tasks reveals that CodeClassPrompt achieves competitive performance while significantly reducing computational overhead.
Read more8/21/2024
🏷️
0
Retrieval-Enhanced Visual Prompt Learning for Few-shot Classification
Jintao Rong, Hao Chen, Tianxiao Chen, Linlin Ou, Xinyi Yu, Yifan Liu
Prompt learning has become a popular approach for adapting large vision-language models, such as CLIP, to downstream tasks. Typically, prompt learning relies on a fixed prompt token or an input-conditional token to fit a small amount of data under full supervision. While this paradigm can generalize to a certain range of unseen classes, it may struggle when domain gap increases, such as in fine-grained classification and satellite image segmentation. To address this limitation, we propose Retrieval-enhanced Prompt learning (RePrompt), which introduces retrieval mechanisms to cache the knowledge representations from downstream tasks. we first construct a retrieval database from training examples, or from external examples when available. We then integrate this retrieval-enhanced mechanism into various stages of a simple prompt learning baseline. By referencing similar samples in the training set, the enhanced model is better able to adapt to new tasks with few samples. Our extensive experiments over 15 vision datasets, including 11 downstream tasks with few-shot setting and 4 domain generalization benchmarks, demonstrate that RePrompt achieves considerably improved performance. Our proposed approach provides a promising solution to the challenges faced by prompt learning when domain gap increases. The code and models will be available.
Read more6/19/2024
0
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
Read more4/1/2024

0
New!A Knowledge-Enhanced Disease Diagnosis Method Based on Prompt Learning and BERT Integration
Zhang Zheng
This paper proposes a knowledge-enhanced disease diagnosis method based on a prompt learning framework. The method retrieves structured knowledge from external knowledge graphs related to clinical cases, encodes it, and injects it into the prompt templates to enhance the language model's understanding and reasoning capabilities for the task.We conducted experiments on three public datasets: CHIP-CTC, IMCS-V2-NER, and KUAKE-QTR. The results show that the proposed method significantly outperforms existing models across multiple evaluation metrics, with an F1 score improvement of 2.4% on the CHIP-CTC dataset, 3.1% on the IMCS-V2-NER dataset,and 4.2% on the KUAKE-QTR dataset. Additionally,ablation studies confirmed the critical role of the knowledge injection module,as the removal of this module resulted in a significant drop in F1 score. The experimental results demonstrate that the proposed method not only effectively improves the accuracy of disease diagnosis but also enhances the interpretability of the predictions, providing more reliable support and evidence for clinical diagnosis.
Read more9/17/2024