Knowledge Graph-Enhanced Large Language Models via Path Selection
2406.13862
0
0

Abstract
Large Language Models (LLMs) have shown unprecedented performance in various real-world applications. However, they are known to generate factually inaccurate outputs, a.k.a. the hallucination problem. In recent years, incorporating external knowledge extracted from Knowledge Graphs (KGs) has become a promising strategy to improve the factual accuracy of LLM-generated outputs. Nevertheless, most existing explorations rely on LLMs themselves to perform KG knowledge extraction, which is highly inflexible as LLMs can only provide binary judgment on whether a certain knowledge (e.g., a knowledge path in KG) should be used. In addition, LLMs tend to pick only knowledge with direct semantic relationship with the input text, while potentially useful knowledge with indirect semantics can be ignored. In this work, we propose a principled framework KELP with three stages to handle the above problems. Specifically, KELP is able to achieve finer granularity of flexible knowledge extraction by generating scores for knowledge paths with input texts via latent semantic matching. Meanwhile, knowledge paths with indirect semantic relationships with the input text can also be considered via trained encoding between the selected paths in KG and the input text. Experiments on real-world datasets validate the effectiveness of KELP.
Create account to get full access
Overview
- This paper presents a method for enhancing large language models with knowledge from a knowledge graph via a path selection approach.
- The key idea is to use the knowledge graph to guide the language model's reasoning process, enabling it to draw on relevant facts and relationships to improve its performance on tasks like question answering.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing that it outperforms baseline language models without access to the knowledge graph.
Plain English Explanation
Large language models like GPT-3 have become incredibly powerful at tasks like generating human-like text. However, these models can sometimes struggle to reason about specific facts and relationships, which is where knowledge graphs come in. A knowledge graph is a structured database that represents real-world entities and the relationships between them.
The key insight of this paper is that by leveraging the information in a knowledge graph, we can guide the language model to make more informed and relevant inferences. The approach works by first identifying the most important paths through the knowledge graph that are relevant to the current task, such as answering a specific question. The language model can then use these paths to draw on relevant facts and relationships, leading to better performance.
For example, if the question is "Who is the president of the United States?", the knowledge graph could help the language model identify the relevant path connecting the entity "United States" to the entity "president", allowing it to confidently provide the correct answer.
Technical Explanation
The core of the authors' approach is a path selection mechanism that identifies the most relevant paths through the knowledge graph for a given input. This is done by first encoding the input and the knowledge graph using separate neural networks, then using an attention-based approach to select the most important paths.
Specifically, the authors use a BERT-based encoder to represent the input text, and a graph neural network to encode the knowledge graph. They then employ a path selector module that takes the encoded input and knowledge graph as input and outputs a probability distribution over the possible paths.
During training, the path selector is optimized to choose paths that lead to the correct answer or output for the given task. At inference time, the selected paths are used to guide the language model's reasoning process, allowing it to draw on relevant facts and relationships from the knowledge graph.
The authors evaluate their approach on several benchmark datasets for question answering and fact retrieval, and show that it outperforms baseline models that do not have access to the knowledge graph. They also provide ablation studies and analyses to better understand the contributions of the different components of their system.
Critical Analysis
One potential limitation of the approach is that it relies on the availability of a high-quality knowledge graph, which may not always be easy to obtain or maintain. The authors acknowledge this and suggest that future work could explore ways to automatically construct or expand knowledge graphs from textual data.
Additionally, the path selection mechanism, while effective, adds some complexity to the overall system. It would be interesting to see if simpler or more efficient approaches to integrating knowledge graphs with language models could achieve similar performance improvements.
Finally, the authors do not extensively explore the potential biases or limitations of the knowledge graphs used in their experiments. It's possible that the knowledge graphs could reflect societal biases or have gaps in their coverage, which could in turn impact the performance of the language model.
Overall, this paper represents an important step forward in the integration of structured knowledge and large language models, and the authors' path selection approach is a promising direction for further research in this area.
Conclusion
This paper presents a novel approach for enhancing large language models with knowledge from a knowledge graph. By using a path selection mechanism to identify the most relevant paths through the knowledge graph, the authors are able to guide the language model's reasoning process and improve its performance on tasks like question answering.
The results demonstrate the potential benefits of combining the world knowledge captured in knowledge graphs with the powerful text generation capabilities of large language models. As research in this area continues to evolve, we may see increasingly sophisticated systems that can seamlessly integrate structured and unstructured knowledge to tackle a wide range of natural language understanding and generation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
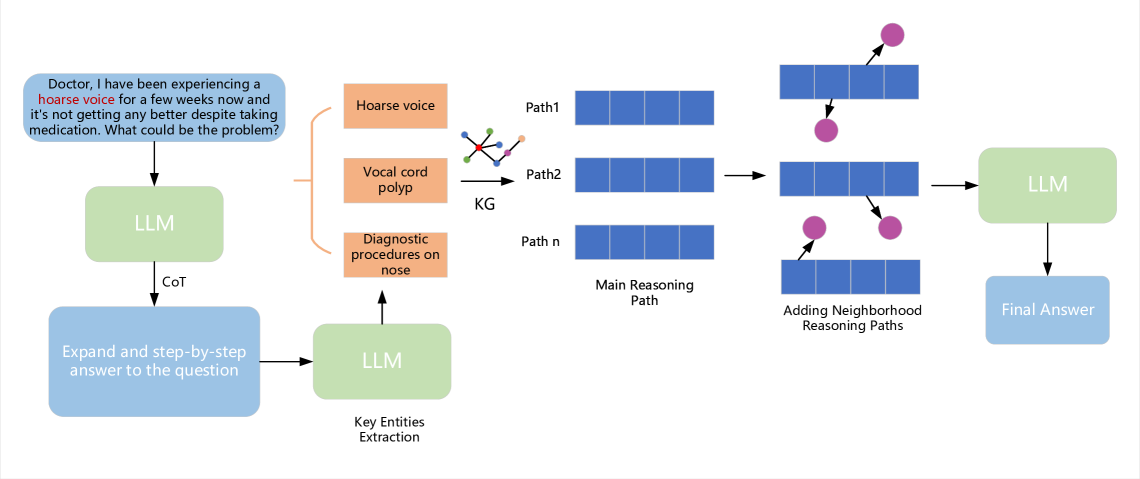
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
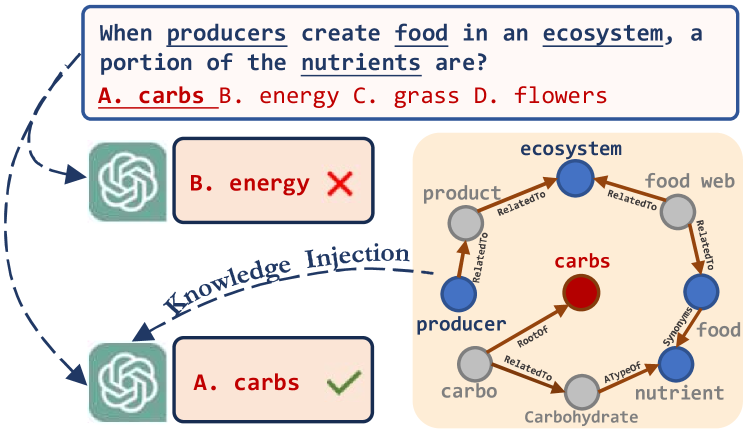
KnowGPT: Knowledge Graph based Prompting for Large Language Models
Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, Xiao Huang
0
0
Large Language Models (LLMs) have demonstrated remarkable capabilities in many real-world applications. Nonetheless, LLMs are often criticized for their tendency to produce hallucinations, wherein the models fabricate incorrect statements on tasks beyond their knowledge and perception. To alleviate this issue, researchers have explored leveraging the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles. However, most state-of-the-art LLMs are closed-source, making it challenging to develop a prompting framework that can efficiently and effectively integrate KGs into LLMs with hard prompts only. Generally, existing KG-enhanced LLMs usually suffer from three critical issues, including huge search space, high API costs, and laborious prompt engineering, that impede their widespread application in practice. To this end, we introduce a novel Knowledge Graph based PrompTing framework, namely KnowGPT, to enhance LLMs with domain knowledge. KnowGPT contains a knowledge extraction module to extract the most informative knowledge from KGs, and a context-aware prompt construction module to automatically convert extracted knowledge into effective prompts. Experiments on three benchmarks demonstrate that KnowGPT significantly outperforms all competitors. Notably, KnowGPT achieves a 92.6% accuracy on OpenbookQA leaderboard, comparable to human-level performance.
6/5/2024
💬
Multi-hop Question Answering over Knowledge Graphs using Large Language Models
Abir Chakraborty
0
0
Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.
5/1/2024
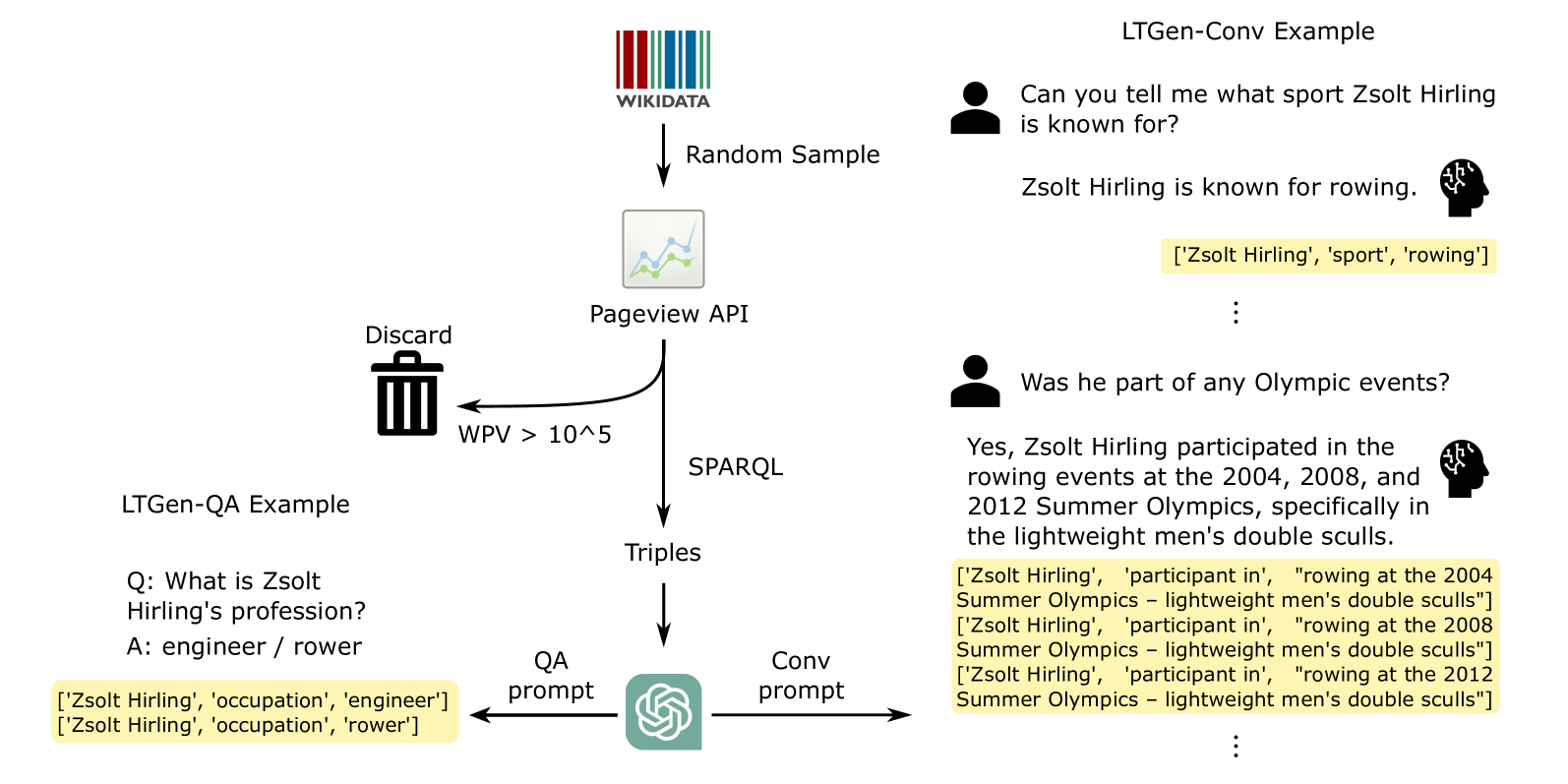
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
Wenyu Huang, Guancheng Zhou, Mirella Lapata, Pavlos Vougiouklis, Sebastien Montella, Jeff Z. Pan
0
0
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
5/13/2024