Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
2405.06524
0
0
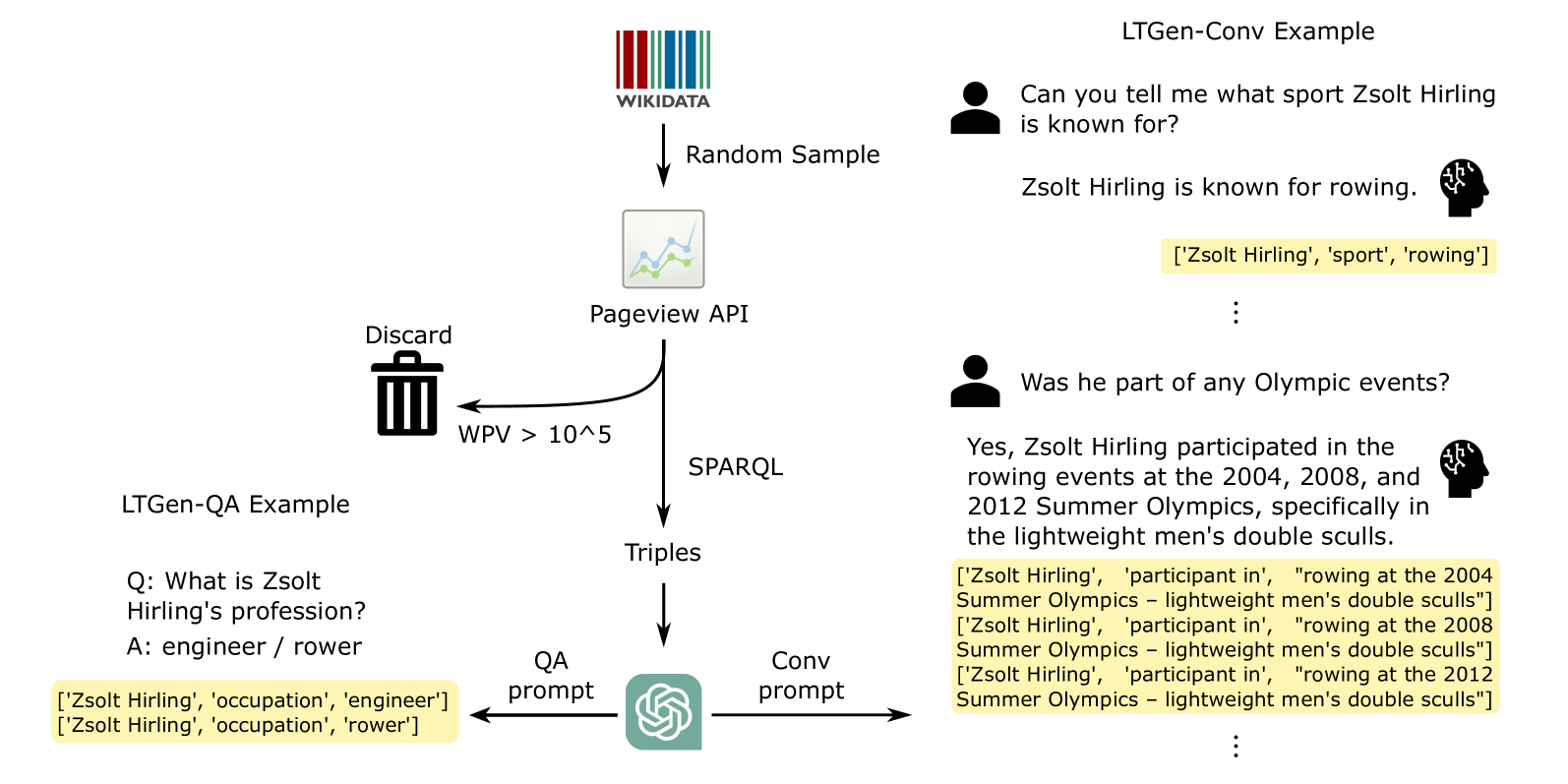
Abstract
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can be prompted with knowledge graphs to improve their ability to answer questions involving long-tail facts.
- The researchers investigate techniques for effectively integrating structured knowledge from knowledge graphs into the LLM prompting process to boost performance on complex, multi-hop questions.
- The paper presents experimental results demonstrating that this approach can help LLMs overcome their limitations in reasoning about long-tail facts and outperform state-of-the-art question answering models.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, they can struggle with answering questions that require knowledge of uncommon or "long-tail" facts. This is because LLMs are trained on broad internet data, which may not cover these more obscure facts in depth.
To address this issue, the researchers in this paper explore ways to prompt LLMs using knowledge graphs - structured databases of facts and relationships. By incorporating relevant knowledge graph information into the prompts given to LLMs, the models can access more targeted and complete information to reason about complex, multi-step questions involving long-tail facts.
For example, imagine a question about the birthplace of a lesser-known historical figure. An LLM trained on broad internet data may not have comprehensive information about this person's biography. But by including relevant knowledge graph data in the prompt, the LLM can draw on more specific details to answer the question accurately.
The paper demonstrates through experiments that this knowledge graph-enhanced prompting approach can significantly improve LLM performance on challenging question-answering tasks involving long-tail facts. This suggests that strategic integration of structured knowledge can help overcome a key limitation of large language models and enhance their real-world utility.
Technical Explanation
The paper explores techniques for prompting large language models with knowledge graphs for question answering involving long-tail facts. The researchers investigate ways to effectively incorporate structured knowledge from knowledge graphs into the LLM prompting process to boost performance on complex, multi-hop questions.
The proposed approach involves constructing prompts that weave in relevant knowledge graph information - such as entities, relationships, and attributes - to complement the LLM's broad but potentially incomplete textual knowledge. This allows the model to reason about long-tail facts by drawing on more targeted and comprehensive knowledge sources.
The paper presents experimental results demonstrating that this knowledge graph-enhanced prompting can significantly improve LLM performance on challenging question-answering tasks compared to state-of-the-art baselines. The findings suggest that strategically integrating structured knowledge can help large language models overcome their limitations in reasoning about long-tail facts and enhance their ability to answer complex, real-world queries.
Critical Analysis
The paper provides a compelling approach for leveraging knowledge graphs to guide large language models in answering questions involving long-tail facts. However, the researchers acknowledge several important caveats and limitations:
- The experiments focus on a curated set of benchmark datasets, and further evaluation is needed to assess the generalizability of the findings to a broader range of real-world question-answering scenarios.
- The paper does not explore the tradeoffs between the additional complexity of the knowledge graph-enhanced prompting approach and any potential impacts on model inference time or computational efficiency.
- While the results demonstrate improvements in long-tail fact reasoning, the authors do not provide a detailed analysis of the types of long-tail facts the approach is most effective at handling.
Additionally, one might question whether over-reliance on knowledge graphs could inadvertently introduce biases or blind spots into the LLM's reasoning if the knowledge graphs themselves have incomplete or skewed coverage of certain domains. Careful consideration of such potential issues would be important for deploying this technology in high-stakes applications.
Conclusion
This paper presents a promising approach for enhancing large language models' ability to reason about long-tail facts by prompting them with relevant knowledge graph information. The experimental results demonstrate the potential of this technique to improve LLM performance on complex, multi-hop question-answering tasks.
While the work highlights important caveats and areas for further research, the core ideas suggest that the strategic integration of structured knowledge can help overcome a key limitation of large language models and expand their real-world utility. As LLMs continue to advance, continued exploration of knowledge-infused prompting strategies could lead to significant advancements in AI-powered question answering and other language understanding applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Head-to-Tail: How Knowledgeable are Large Language Models (LLMs)? A.K.A. Will LLMs Replace Knowledge Graphs?
Kai Sun, Yifan Ethan Xu, Hanwen Zha, Yue Liu, Xin Luna Dong
0
0
Since the recent prosperity of Large Language Models (LLMs), there have been interleaved discussions regarding how to reduce hallucinations from LLM responses, how to increase the factuality of LLMs, and whether Knowledge Graphs (KGs), which store the world knowledge in a symbolic form, will be replaced with LLMs. In this paper, we try to answer these questions from a new angle: How knowledgeable are LLMs? To answer this question, we constructed Head-to-Tail, a benchmark that consists of 18K question-answer (QA) pairs regarding head, torso, and tail facts in terms of popularity. We designed an automated evaluation method and a set of metrics that closely approximate the knowledge an LLM confidently internalizes. Through a comprehensive evaluation of 16 publicly available LLMs, we show that existing LLMs are still far from being perfect in terms of their grasp of factual knowledge, especially for facts of torso-to-tail entities.
4/4/2024
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024
KnowGPT: Knowledge Graph based Prompting for Large Language Models
Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, Xiao Huang
0
0
Large Language Models (LLMs) have demonstrated remarkable capabilities in many real-world applications. Nonetheless, LLMs are often criticized for their tendency to produce hallucinations, wherein the models fabricate incorrect statements on tasks beyond their knowledge and perception. To alleviate this issue, researchers have explored leveraging the factual knowledge in knowledge graphs (KGs) to ground the LLM's responses in established facts and principles. However, most state-of-the-art LLMs are closed-source, making it challenging to develop a prompting framework that can efficiently and effectively integrate KGs into LLMs with hard prompts only. Generally, existing KG-enhanced LLMs usually suffer from three critical issues, including huge search space, high API costs, and laborious prompt engineering, that impede their widespread application in practice. To this end, we introduce a novel Knowledge Graph based PrompTing framework, namely KnowGPT, to enhance LLMs with domain knowledge. KnowGPT contains a knowledge extraction module to extract the most informative knowledge from KGs, and a context-aware prompt construction module to automatically convert extracted knowledge into effective prompts. Experiments on three benchmarks demonstrate that KnowGPT significantly outperforms all competitors. Notably, KnowGPT achieves a 92.6% accuracy on OpenbookQA leaderboard, comparable to human-level performance.
6/5/2024
💬
Multi-hop Question Answering over Knowledge Graphs using Large Language Models
Abir Chakraborty
0
0
Knowledge graphs (KGs) are large datasets with specific structures representing large knowledge bases (KB) where each node represents a key entity and relations amongst them are typed edges. Natural language queries formed to extract information from a KB entail starting from specific nodes and reasoning over multiple edges of the corresponding KG to arrive at the correct set of answer nodes. Traditional approaches of question answering on KG are based on (a) semantic parsing (SP), where a logical form (e.g., S-expression, SPARQL query, etc.) is generated using node and edge embeddings and then reasoning over these representations or tuning language models to generate the final answer directly, or (b) information-retrieval based that works by extracting entities and relations sequentially. In this work, we evaluate the capability of (LLMs) to answer questions over KG that involve multiple hops. We show that depending upon the size and nature of the KG we need different approaches to extract and feed the relevant information to an LLM since every LLM comes with a fixed context window. We evaluate our approach on six KGs with and without the availability of example-specific sub-graphs and show that both the IR and SP-based methods can be adopted by LLMs resulting in an extremely competitive performance.
5/1/2024