Knowledge Graph Extension by Entity Type Recognition

0
👁️
Sign in to get full access
Overview
- This paper presents a novel approach to integrating semantic and structural knowledge into a knowledge graph for entity representation.
- The researchers propose an automated construction of theme-specific knowledge graphs from unstructured text data.
- The work also explores continual relation extraction to improve knowledge graph completeness.
- Additionally, the paper discusses accelerating medical knowledge discovery through automated knowledge graph construction.
- The research describes an automatic knowledge graph construction for judicial cases.
Plain English Explanation
The paper focuses on improving the way computers understand and represent information by building more comprehensive knowledge graphs. Knowledge graphs are digital maps that connect different pieces of information, like a web of related facts and concepts.
The researchers propose new methods to automatically create these knowledge graphs from unstructured text data, such as documents and articles. This is important because a lot of valuable information exists in text form that computers struggle to fully comprehend.
The key ideas are:
-
Integrating both the meaning (semantics) and the structure of information into the knowledge graph. This helps the computer grasp the full context and relationships between different pieces of data.
-
Continuously updating the knowledge graph as new information becomes available. This ensures the graph stays current and complete, rather than becoming outdated.
-
Applying these techniques to specific domains, like medical research and legal cases, to accelerate knowledge discovery and organization in those fields.
By building more sophisticated knowledge graphs, the researchers aim to enable computers to better understand the world and assist humans in tasks like research, analysis, and decision-making. This could lead to breakthroughs in areas like scientific discovery, medical treatment, and legal reasoning.
Technical Explanation
The paper presents an integrated approach to incorporating both semantic and structural knowledge into knowledge graph entity representations.
The researchers first describe an automated method for constructing theme-specific knowledge graphs from unstructured text data. This involves extracting relevant entities, relations, and attributes, and organizing them into a coherent graph structure.
To address knowledge graph incompleteness, the paper introduces a continual relation extraction approach. This continuously identifies new relations between entities as more information becomes available, expanding the knowledge graph over time.
The work also explores accelerating medical knowledge discovery by automating the construction of medical knowledge graphs from scientific literature.
Finally, the researchers demonstrate an automatic knowledge graph construction method for judicial cases, showcasing the broader applicability of their techniques.
Critical Analysis
The paper presents a comprehensive approach to enhancing knowledge graph construction and maintenance, addressing important limitations in existing methods. However, the researchers acknowledge that their techniques are still subject to certain caveats and limitations.
For example, the automated extraction of entities, relations, and attributes from unstructured text may not always be perfectly accurate, leading to potential errors or biases in the resulting knowledge graph. Additionally, the continual relation extraction process relies on the availability of new information, which may not be consistently provided over time.
Further research could explore ways to improve the robustness and reliability of the automated knowledge graph construction, perhaps by incorporating human validation or leveraging advanced natural language processing techniques. Evaluating the performance and practical impact of these methods in real-world scenarios would also be valuable.
Conclusion
This paper proposes innovative solutions to the challenges of building comprehensive and up-to-date knowledge graphs from diverse data sources. By integrating semantic and structural knowledge, enabling continual relation extraction, and applying these techniques to specific domains, the researchers have made significant strides towards more powerful and versatile knowledge representation.
The potential implications of this work are far-reaching, as improved knowledge graphs could drive breakthroughs in fields like scientific research, medical diagnosis, legal decision-making, and beyond. As computers become better equipped to understand and reason about the world, the opportunities for accelerating human knowledge and discovery are vast.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Knowledge Graph Extension by Entity Type Recognition
Daqian Shi
Knowledge graphs have emerged as a sophisticated advancement and refinement of semantic networks, and their deployment is one of the critical methodologies in contemporary artificial intelligence. The construction of knowledge graphs is a multifaceted process involving various techniques, where researchers aim to extract the knowledge from existing resources for the construction since building from scratch entails significant labor and time costs. However, due to the pervasive issue of heterogeneity, the description diversity across different knowledge graphs can lead to mismatches between concepts, thereby impacting the efficacy of knowledge extraction. This Ph.D. study focuses on automatic knowledge graph extension, i.e., properly extending the reference knowledge graph by extracting and integrating concepts from one or more candidate knowledge graphs. We propose a novel knowledge graph extension framework based on entity type recognition. The framework aims to achieve high-quality knowledge extraction by aligning the schemas and entities across different knowledge graphs, thereby enhancing the performance of the extension. This paper elucidates three major contributions: (i) we propose an entity type recognition method exploiting machine learning and property-based similarities to enhance knowledge extraction; (ii) we introduce a set of assessment metrics to validate the quality of the extended knowledge graphs; (iii) we develop a platform for knowledge graph acquisition, management, and extension to benefit knowledge engineers practically. Our evaluation comprehensively demonstrated the feasibility and effectiveness of the proposed extension framework and its functionalities through quantitative experiments and case studies.
Read more5/7/2024

0
KAE: A Property-based Method for Knowledge Graph Alignment and Extension
Daqian Shi, Xiaoyue Li, Fausto Giunchiglia
A common solution to the semantic heterogeneity problem is to perform knowledge graph (KG) extension exploiting the information encoded in one or more candidate KGs, where the alignment between the reference KG and candidate KGs is considered the critical procedure. However, existing KG alignment methods mainly rely on entity type (etype) label matching as a prerequisite, which is poorly performing in practice or not applicable in some cases. In this paper, we design a machine learning-based framework for KG extension, including an alternative novel property-based alignment approach that allows aligning etypes on the basis of the properties used to define them. The main intuition is that it is properties that intentionally define the etype, and this definition is independent of the specific label used to name an etype, and of the specific hierarchical schema of KGs. Compared with the state-of-the-art, the experimental results show the validity of the KG alignment approach and the superiority of the proposed KG extension framework, both quantitatively and qualitatively.
Read more7/9/2024
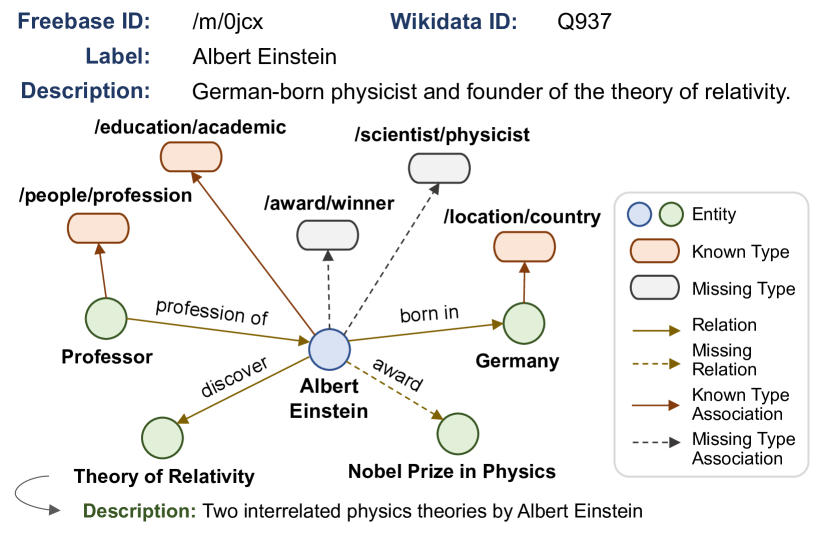
0
The Integration of Semantic and Structural Knowledge in Knowledge Graph Entity Typing
Muzhi Li, Minda Hu, Irwin King, Ho-fung Leung
The Knowledge Graph Entity Typing (KGET) task aims to predict missing type annotations for entities in knowledge graphs. Recent works only utilize the textit{textbf{structural knowledge}} in the local neighborhood of entities, disregarding textit{textbf{semantic knowledge}} in the textual representations of entities, relations, and types that are also crucial for type inference. Additionally, we observe that the interaction between semantic and structural knowledge can be utilized to address the false-negative problem. In this paper, we propose a novel textbf{underline{S}}emantic and textbf{underline{S}}tructure-aware KG textbf{underline{E}}ntity textbf{underline{T}}yping~{(SSET)} framework, which is composed of three modules. First, the textit{Semantic Knowledge Encoding} module encodes factual knowledge in the KG with a Masked Entity Typing task. Then, the textit{Structural Knowledge Aggregation} module aggregates knowledge from the multi-hop neighborhood of entities to infer missing types. Finally, the textit{Unsupervised Type Re-ranking} module utilizes the inference results from the two models above to generate type predictions that are robust to false-negative samples. Extensive experiments show that SSET significantly outperforms existing state-of-the-art methods.
Read more4/15/2024

0
Generalized knowledge-enhanced framework for biomedical entity and relation extraction
Minh Nguyen, Phuong Le
In recent years, there has been an increasing number of frameworks developed for biomedical entity and relation extraction. This research effort aims to address the accelerating growth in biomedical publications and the intricate nature of biomedical texts, which are written for mainly domain experts. To handle these challenges, we develop a novel framework that utilizes external knowledge to construct a task-independent and reusable background knowledge graph for biomedical entity and relation extraction. The design of our model is inspired by how humans learn domain-specific topics. In particular, humans often first acquire the most basic and common knowledge regarding a field to build the foundational knowledge and then use that as a basis for extending to various specialized topics. Our framework employs such common-knowledge-sharing mechanism to build a general neural-network knowledge graph that is learning transferable to different domain-specific biomedical texts effectively. Experimental evaluations demonstrate that our model, equipped with this generalized and cross-transferable knowledge base, achieves competitive performance benchmarks, including BioRelEx for binding interaction detection and ADE for Adverse Drug Effect identification.
Read more8/14/2024