A Continual Relation Extraction Approach for Knowledge Graph Completeness
2404.17593
0
0
Abstract
Representing unstructured data in a structured form is most significant for information system management to analyze and interpret it. To do this, the unstructured data might be converted into Knowledge Graphs, by leveraging an information extraction pipeline whose main tasks are named entity recognition and relation extraction. This thesis aims to develop a novel continual relation extraction method to identify relations (interconnections) between entities in a data stream coming from the real world. Domain-specific data of this thesis is corona news from German and Austrian newspapers.
Create account to get full access
Overview
- This paper presents a continual relation extraction approach for improving the completeness of knowledge graphs.
- The proposed method continuously extracts new relations from text data and incorporates them into the knowledge graph, without forgetting previously learned relations.
- The approach addresses the challenge of knowledge graph incompleteness by continuously expanding the graph with new information.
Plain English Explanation
Knowledge graphs are digital representations of real-world entities and the relationships between them. They are useful for various applications, such as improving recall in large language models and fine-grained named entity recognition in COVID-19 news. However, knowledge graphs are often incomplete, meaning they are missing many important facts and relationships.
The researchers in this paper have developed a new method to continuously update and expand knowledge graphs. Their approach involves continuously extracting new relations from text data and adding them to the knowledge graph, without forgetting the relations that were previously learned. This helps to make the knowledge graph more complete and up-to-date over time.
The key idea is to use a machine learning model that can continuously learn new relations from text, while also retaining its knowledge of past relations. This is a challenging task, as machine learning models can often "forget" old information when learning new things. The researchers have developed a novel approach to address this problem, which allows the model to continuously expand the knowledge graph without losing its existing knowledge.
Technical Explanation
The paper proposes a continual relation extraction (CRE) approach to address the challenge of knowledge graph incompleteness. The CRE model is designed to continuously extract new relations from text data and incorporate them into the knowledge graph, without forgetting previously learned relations.
The CRE model is built upon a structure-aware text-to-graph model and utilizes structural and textual embeddings to represent entities and relations. The model is trained in a continual learning setting, where it is exposed to a sequence of text corpora containing new relations.
To address the challenge of catastrophic forgetting, where the model forgets previously learned information when learning new tasks, the researchers employ rehearsal-based continual learning techniques. This involves periodically replaying a subset of the previously learned relations during training, which helps the model maintain its knowledge of past relations while continuously expanding the knowledge graph.
The paper evaluates the CRE model on several benchmark datasets and demonstrates its effectiveness in continuously expanding the knowledge graph without significantly degrading its performance on previously learned relations.
Critical Analysis
The paper presents a novel and promising approach to address the challenge of knowledge graph incompleteness. The continual relation extraction method is a valuable contribution to the field, as it provides a way to continuously update knowledge graphs with new information without losing past knowledge.
One potential limitation of the approach is that it relies on the availability of text data containing new relations. In practice, the relevance and quality of the text data used for continual learning may vary, which could impact the performance of the CRE model.
Additionally, the paper does not discuss the scalability of the proposed approach. As knowledge graphs grow larger and more complex, the computational and memory requirements of the continual learning process may become a challenge.
Further research could explore ways to make the CRE model more efficient and robust, such as by investigating more advanced continual learning techniques or by incorporating additional sources of information, such as retrieval-augmented generation or collaborative modeling, to improve the quality and coverage of the extracted relations.
Conclusion
This paper presents a continual relation extraction approach to address the problem of knowledge graph incompleteness. The proposed method continuously extracts new relations from text data and incorporates them into the knowledge graph, without forgetting previously learned relations.
The key contribution of this work is the development of a machine learning model that can continuously expand the knowledge graph while maintaining its existing knowledge. This is a significant advancement in the field of knowledge graph completion, as it provides a way to keep knowledge graphs up-to-date and comprehensive over time.
The potential applications of this research are far-reaching, as knowledge graphs are used in a wide range of applications, from improving recall in large language models to fine-grained named entity recognition in COVID-19 news. By continuously expanding the knowledge graph, the CRE approach can help to improve the performance and capabilities of these applications, ultimately leading to better tools and technologies for various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers
Xiaoyan Zhao, Yang Deng, Min Yang, Lingzhi Wang, Rui Zhang, Hong Cheng, Wai Lam, Ying Shen, Ruifeng Xu
0
0
Relation extraction (RE) involves identifying the relations between entities from underlying content. RE serves as the foundation for many natural language processing (NLP) and information retrieval applications, such as knowledge graph completion and question answering. In recent years, deep neural networks have dominated the field of RE and made noticeable progress. Subsequently, the large pre-trained language models have taken the state-of-the-art RE to a new level. This survey provides a comprehensive review of existing deep learning techniques for RE. First, we introduce RE resources, including datasets and evaluation metrics. Second, we propose a new taxonomy to categorize existing works from three perspectives, i.e., text representation, context encoding, and triplet prediction. Third, we discuss several important challenges faced by RE and summarize potential techniques to tackle these challenges. Finally, we outline some promising future directions and prospects in this field. This survey is expected to facilitate researchers' collaborative efforts to address the challenges of real-world RE systems.
6/26/2024
🔮
Relations Prediction for Knowledge Graph Completion using Large Language Models
Sakher Khalil Alqaaidi, Krzysztof Kochut
0
0
Knowledge Graphs have been widely used to represent facts in a structured format. Due to their large scale applications, knowledge graphs suffer from being incomplete. The relation prediction task obtains knowledge graph completion by assigning one or more possible relations to each pair of nodes. In this work, we make use of the knowledge graph node names to fine-tune a large language model for the relation prediction task. By utilizing the node names only we enable our model to operate sufficiently in the inductive settings. Our experiments show that we accomplish new scores on a widely used knowledge graph benchmark.
5/7/2024
⛏️
Knowledge-Driven Cross-Document Relation Extraction
Monika Jain, Raghava Mutharaju, Kuldeep Singh, Ramakanth Kavuluru
0
0
Relation extraction (RE) is a well-known NLP application often treated as a sentence- or document-level task. However, a handful of recent efforts explore it across documents or in the cross-document setting (CrossDocRE). This is distinct from the single document case because different documents often focus on disparate themes, while text within a document tends to have a single goal. Linking findings from disparate documents to identify new relationships is at the core of the popular literature-based knowledge discovery paradigm in biomedicine and other domains. Current CrossDocRE efforts do not consider domain knowledge, which are often assumed to be known to the reader when documents are authored. Here, we propose a novel approach, KXDocRE, that embed domain knowledge of entities with input text for cross-document RE. Our proposed framework has three main benefits over baselines: 1) it incorporates domain knowledge of entities along with documents' text; 2) it offers interpretability by producing explanatory text for predicted relations between entities 3) it improves performance over the prior methods.
6/19/2024
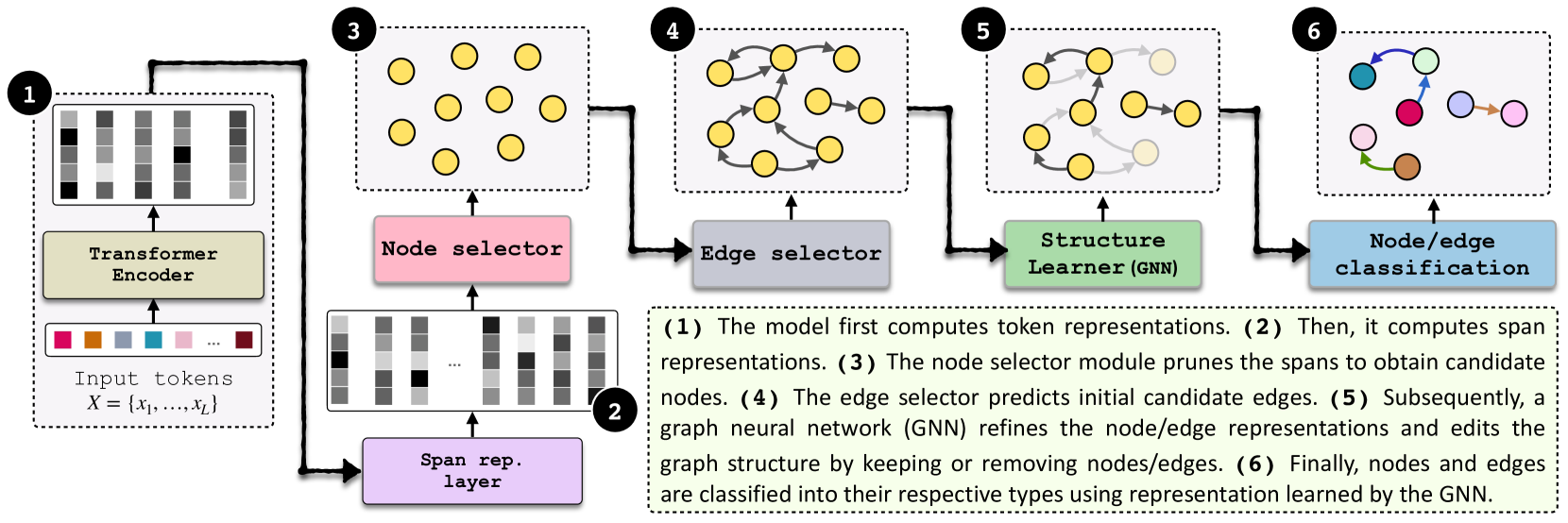
GraphER: A Structure-aware Text-to-Graph Model for Entity and Relation Extraction
Urchade Zaratiana, Nadi Tomeh, Niama El Khbir, Pierre Holat, Thierry Charnois
0
0
Information extraction (IE) is an important task in Natural Language Processing (NLP), involving the extraction of named entities and their relationships from unstructured text. In this paper, we propose a novel approach to this task by formulating it as graph structure learning (GSL). By formulating IE as GSL, we enhance the model's ability to dynamically refine and optimize the graph structure during the extraction process. This formulation allows for better interaction and structure-informed decisions for entity and relation prediction, in contrast to previous models that have separate or untied predictions for these tasks. When compared against state-of-the-art baselines on joint entity and relation extraction benchmarks, our model, GraphER, achieves competitive results.
4/22/2024