Knowledge Sharing and Transfer via Centralized Reward Agent for Multi-Task Reinforcement Learning

0

Sign in to get full access
Overview
- This paper proposes a centralized reward agent approach for multi-task reinforcement learning to enable effective knowledge sharing and transfer.
- The goal is to improve the learning efficiency and performance of agents across multiple tasks by leveraging a shared reward function and knowledge.
- The authors demonstrate the effectiveness of their approach through experiments on various reinforcement learning environments.
Plain English Explanation
The paper explores a new way to help artificial intelligence (AI) agents learn more efficiently when faced with multiple tasks. Typically, AI agents are trained separately for each task, which can be time-consuming and inefficient.
The researchers' idea is to have a centralized reward agent that can oversee the learning of multiple AI agents and help them share knowledge and insights between tasks. This centralized agent would learn a shared reward function that captures the key objectives common across the different tasks.
By having this centralized system, the individual AI agents can leverage the shared knowledge and reward function to learn more quickly and perform better on their assigned tasks. The authors show through experiments that this approach leads to significant improvements in learning efficiency and overall performance compared to training agents independently.
The key insight is that by facilitating knowledge sharing and transfer between tasks, the AI agents can build upon each other's experiences rather than having to start from scratch every time. This mirrors how humans are able to apply lessons learned in one domain to excel in related areas.
Technical Explanation
The paper introduces a centralized reward agent that oversees the training of multiple reinforcement learning agents operating in different environments or tasks.
The central agent learns a shared reward function that captures the key objectives common across the tasks. This shared reward function is then used to guide the training of the individual agents, allowing them to leverage knowledge and insights from one task to improve performance on others.
The authors evaluate their approach on a variety of reinforcement learning environments, including classic control tasks, robotics manipulation, and video games. The results demonstrate significant improvements in sample efficiency and asymptotic performance compared to training agents independently without the centralized reward agent.
The key technical contributions include:
- Centralized Reward Agent Architecture: The design of the centralized agent that learns the shared reward function and guides the training of individual task-specific agents.
- Multi-Task Knowledge Sharing: Mechanisms for the individual agents to effectively share and transfer knowledge through the centralized reward function.
- Empirical Evaluation: Thorough experimental validation of the approach across diverse reinforcement learning environments.
Critical Analysis
The paper presents a promising approach for enabling more efficient multi-task reinforcement learning by facilitating knowledge sharing and transfer through a centralized reward agent. The experimental results are convincing and demonstrate significant performance improvements over independent training.
However, the authors acknowledge some limitations of their approach, such as the potential complexity of learning a suitable shared reward function and the need for careful task selection and relationship modeling to enable effective knowledge transfer.
Additionally, the paper does not delve into the scalability of the centralized agent as the number of tasks or agents grows, which could be an important consideration for real-world applications.
Further research could explore ways to make the shared reward function learning more robust and efficient, as well as investigate techniques for automatically discovering task relationships and similarities to enable more widespread knowledge transfer.
Conclusion
This paper presents an innovative approach to multi-task reinforcement learning that leverages a centralized reward agent to facilitate knowledge sharing and transfer among individual task-specific agents. By learning a shared reward function, the centralized agent is able to guide the agents towards common objectives, leading to significant improvements in learning efficiency and overall performance.
The findings of this research have the potential to advance the field of reinforcement learning, enabling AI systems to learn more effectively across a diverse set of tasks and applications. This could lead to more versatile and capable AI agents that can adapt and generalize their knowledge to new challenges, much like how humans are able to apply lessons learned in one domain to excel in related areas.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Knowledge Sharing and Transfer via Centralized Reward Agent for Multi-Task Reinforcement Learning
Haozhe Ma, Zhengding Luo, Thanh Vinh Vo, Kuankuan Sima, Tze-Yun Leong
Reward shaping is effective in addressing the sparse-reward challenge in reinforcement learning by providing immediate feedback through auxiliary informative rewards. Based on the reward shaping strategy, we propose a novel multi-task reinforcement learning framework, that integrates a centralized reward agent (CRA) and multiple distributed policy agents. The CRA functions as a knowledge pool, which aims to distill knowledge from various tasks and distribute it to individual policy agents to improve learning efficiency. Specifically, the shaped rewards serve as a straightforward metric to encode knowledge. This framework not only enhances knowledge sharing across established tasks but also adapts to new tasks by transferring valuable reward signals. We validate the proposed method on both discrete and continuous domains, demonstrating its robustness in multi-task sparse-reward settings and its effective transferability to unseen tasks.
Read more8/21/2024
0
Highly Efficient Self-Adaptive Reward Shaping for Reinforcement Learning
Haozhe Ma, Zhengding Luo, Thanh Vinh Vo, Kuankuan Sima, Tze-Yun Leong
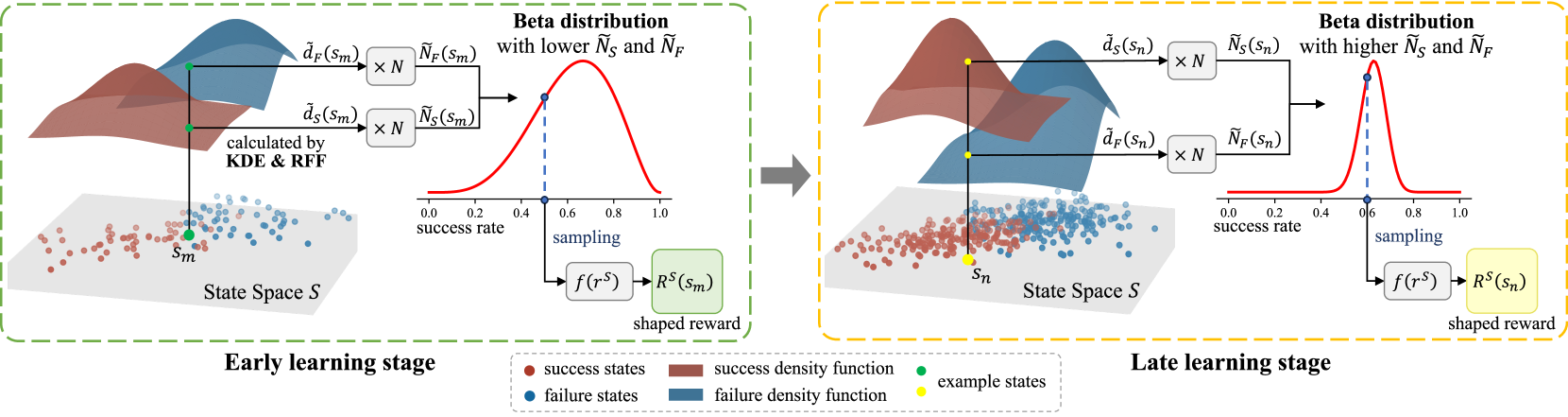
Reward shaping addresses the challenge of sparse rewards in reinforcement learning by constructing denser and more informative reward signals. To achieve self-adaptive and highly efficient reward shaping, we propose a novel method that incorporates success rates derived from historical experiences into shaped rewards. Our approach utilizes success rates sampled from Beta distributions, which dynamically evolve from uncertain to reliable values as more data is collected. Initially, the self-adaptive success rates exhibit more randomness to encourage exploration. Over time, they become more certain to enhance exploitation, thus achieving a better balance between exploration and exploitation. We employ Kernel Density Estimation (KDE) combined with Random Fourier Features (RFF) to derive the Beta distributions, resulting in a computationally efficient implementation in high-dimensional continuous state spaces. This method provides a non-parametric and learning-free approach. The proposed method is evaluated on a wide range of continuous control tasks with sparse and delayed rewards, demonstrating significant improvements in sample efficiency and convergence stability compared to relevant baselines.
Read more8/9/2024

0
Comprehensive Overview of Reward Engineering and Shaping in Advancing Reinforcement Learning Applications
Sinan Ibrahim, Mostafa Mostafa, Ali Jnadi, Pavel Osinenko
The aim of Reinforcement Learning (RL) in real-world applications is to create systems capable of making autonomous decisions by learning from their environment through trial and error. This paper emphasizes the importance of reward engineering and reward shaping in enhancing the efficiency and effectiveness of reinforcement learning algorithms. Reward engineering involves designing reward functions that accurately reflect the desired outcomes, while reward shaping provides additional feedback to guide the learning process, accelerating convergence to optimal policies. Despite significant advancements in reinforcement learning, several limitations persist. One key challenge is the sparse and delayed nature of rewards in many real-world scenarios, which can hinder learning progress. Additionally, the complexity of accurately modeling real-world environments and the computational demands of reinforcement learning algorithms remain substantial obstacles. On the other hand, recent advancements in deep learning and neural networks have significantly improved the capability of reinforcement learning systems to handle high-dimensional state and action spaces, enabling their application to complex tasks such as robotics, autonomous driving, and game playing. This paper provides a comprehensive review of the current state of reinforcement learning, focusing on the methodologies and techniques used in reward engineering and reward shaping. It critically analyzes the limitations and recent advancements in the field, offering insights into future research directions and potential applications in various domains.
Read more8/21/2024
0
Efficient Reinforcement Learning via Large Language Model-based Search
Siddhant Bhambri, Amrita Bhattacharjee, Huan Liu, Subbarao Kambhampati
Reinforcement Learning (RL) suffers from sample inefficiency in sparse reward domains, and the problem is pronounced if there are stochastic transitions. To improve the sample efficiency, reward shaping is a well-studied approach to introduce intrinsic rewards that can help the RL agent converge to an optimal policy faster. However, designing a useful reward shaping function specific to each problem is challenging, even for domain experts. They would either have to rely on task-specific domain knowledge or provide an expert demonstration independently for each task. Given, that Large Language Models (LLMs) have rapidly gained prominence across a magnitude of natural language tasks, we aim to answer the following question: Can we leverage LLMs to construct a reward shaping function that can boost the sample efficiency of an RL agent? In this work, we aim to leverage off-the-shelf LLMs to generate a guide policy by solving a simpler deterministic abstraction of the original problem that can then be used to construct the reward shaping function for the downstream RL agent. Given the ineffectiveness of directly prompting LLMs, we propose MEDIC: a framework that augments LLMs with a Model-based feEDback critIC, which verifies LLM-generated outputs, to generate a possibly sub-optimal but valid plan for the abstract problem. Our experiments across domains from the BabyAI environment suite show 1) the effectiveness of augmenting LLMs with MEDIC, 2) a significant improvement in the sample complexity of PPO and A2C-based RL agents when guided by our LLM-generated plan, and finally, 3) pave the direction for further explorations of how these models can be used to augment existing RL pipelines.
Read more5/27/2024