Robust Knowledge Transfer in Tiered Reinforcement Learning

0
🔄
Sign in to get full access
Overview
- This paper studies a parallel transfer learning framework called Tiered Reinforcement Learning, where the goal is to transfer knowledge from a low-tier (source) task to a high-tier (target) task.
- Unlike previous work, the authors do not assume the low-tier and high-tier tasks share the same dynamics or reward functions, and focus on robust knowledge transfer without prior knowledge on the task similarity.
- The authors identify a necessary condition called "Optimal Value Dominance" and propose novel online learning algorithms that can achieve constant regret on partial states for the high-tier task, while keeping near-optimal regret for the low-tier task.
- The authors also study the setting with multiple low-tier tasks and propose a novel transfer source selection mechanism to ensemble information from all low-tier tasks, allowing for provable benefits on a much larger state-action space.
Plain English Explanation
In this research, the authors are studying a way to transfer knowledge from one reinforcement learning task (the "low-tier" or "source" task) to another, more complex task (the "high-tier" or "target" task). The goal is to help the high-tier task learn more efficiently by using what was learned in the low-tier task, even if the two tasks are quite different.
Unlike previous work, the authors don't assume the low-tier and high-tier tasks are very similar. Instead, they focus on finding a way to transfer knowledge robustly, without needing to know how similar the tasks are beforehand.
The key insight they identify is something called "Optimal Value Dominance" - a condition that allows the knowledge transfer to work well. Based on this, they develop new learning algorithms that can perform well on the high-tier task, achieving good results without having to explore as much. At the same time, the algorithms can also maintain near-optimal performance on the low-tier task, without sacrificing its own learning.
The authors also look at the case where there are multiple low-tier tasks to learn from. They propose a novel way to combine the knowledge from all these tasks to further boost the performance on the high-tier task, allowing the benefits to scale to much larger state and action spaces.
Technical Explanation
The paper introduces the Tiered Reinforcement Learning setting, where the goal is to transfer knowledge from a low-tier (source) task to a high-tier (target) task in a parallel learning framework. Unlike prior work, the authors do not assume the low-tier and high-tier tasks share the same dynamics or reward functions, and focus on robust knowledge transfer without prior knowledge on task similarity.
The authors identify a necessary condition called "Optimal Value Dominance" (OVD), which essentially states that the optimal value function of the high-tier task must be upper bounded by some linear combination of the optimal value functions of the low-tier tasks. Under this condition, the authors propose novel online learning algorithms:
- For the high-tier task, the algorithm can achieve constant regret on partial states depending on the task similarity, and retain near-optimal regret when the two tasks are dissimilar.
- For the low-tier task, the algorithm can keep near-optimal regret without making any sacrifices.
The authors also study the setting with multiple low-tier tasks and propose a novel transfer source selection mechanism. This mechanism can ensemble the information from all low-tier tasks, allowing for provable benefits on a much larger state-action space compared to the single low-tier task setting.
The key technical innovations include:
- Formulating the parallel transfer learning problem without assuming task similarity
- Identifying the Optimal Value Dominance condition as a necessary requirement
- Developing online learning algorithms that can achieve desirable regret guarantees for both the high-tier and low-tier tasks
- Extending the framework to handle multiple low-tier tasks with a novel transfer source selection mechanism
Critical Analysis
The paper presents a compelling approach to parallel transfer learning in reinforcement learning, addressing an important practical challenge of knowledge transfer between tasks with different dynamics and rewards. The authors' focus on robust transfer without prior knowledge of task similarity is a valuable contribution, as it relaxes assumptions made in previous work.
One potential limitation is the reliance on the Optimal Value Dominance (OVD) condition, which may not always hold in practice. The authors acknowledge this and suggest that further research is needed to explore alternative conditions or ways to relax the OVD constraint.
Additionally, the paper primarily focuses on the theoretical analysis and regret guarantees of the proposed algorithms. While the theoretical results are strong, it would be valuable to see empirical evaluations of the algorithms on relevant real-world or benchmark reinforcement learning tasks to assess their practical performance and applicability.
Another area for further research could be extending the framework to handle more complex task relationships, such as hierarchical or multi-agent settings, which are common in real-world applications.
Overall, this paper presents a promising approach to parallel transfer learning in reinforcement learning and lays the groundwork for further advancements in this important area of research.
Conclusion
This paper introduces the Tiered Reinforcement Learning setting, a parallel transfer learning framework for efficiently transferring knowledge from a low-tier (source) task to a high-tier (target) task. The authors focus on the challenging case where the low-tier and high-tier tasks do not share the same dynamics or reward functions, and propose novel online learning algorithms that can achieve strong regret guarantees for both tasks.
The key contributions include the identification of the Optimal Value Dominance condition, the development of efficient algorithms that can leverage this condition, and the extension to the multi-low-tier-task setting with a novel transfer source selection mechanism. While the theoretical results are promising, further research is needed to explore alternative conditions, empirically evaluate the methods, and extend the framework to handle more complex task relationships.
Overall, this work represents an important step forward in parallel transfer learning for reinforcement learning, with the potential to significantly improve the efficiency and applicability of reinforcement learning systems in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Robust Knowledge Transfer in Tiered Reinforcement Learning
Jiawei Huang, Niao He
In this paper, we study the Tiered Reinforcement Learning setting, a parallel transfer learning framework, where the goal is to transfer knowledge from the low-tier (source) task to the high-tier (target) task to reduce the exploration risk of the latter while solving the two tasks in parallel. Unlike previous work, we do not assume the low-tier and high-tier tasks share the same dynamics or reward functions, and focus on robust knowledge transfer without prior knowledge on the task similarity. We identify a natural and necessary condition called the ``Optimal Value Dominance'' for our objective. Under this condition, we propose novel online learning algorithms such that, for the high-tier task, it can achieve constant regret on partial states depending on the task similarity and retain near-optimal regret when the two tasks are dissimilar, while for the low-tier task, it can keep near-optimal without making sacrifice. Moreover, we further study the setting with multiple low-tier tasks, and propose a novel transfer source selection mechanism, which can ensemble the information from all low-tier tasks and allow provable benefits on a much larger state-action space.
Read more6/14/2024

0
Knowledge Transfer for Cross-Domain Reinforcement Learning: A Systematic Review
Sergio A. Serrano, Jose Martinez-Carranza, L. Enrique Sucar
Reinforcement Learning (RL) provides a framework in which agents can be trained, via trial and error, to solve complex decision-making problems. Learning with little supervision causes RL methods to require large amounts of data, which renders them too expensive for many applications (e.g. robotics). By reusing knowledge from a different task, knowledge transfer methods present an alternative to reduce the training time in RL. Given how severe data scarcity can be, there has been a growing interest for methods capable of transferring knowledge across different domains (i.e. problems with different representation) due to the flexibility they offer. This review presents a unifying analysis of methods focused on transferring knowledge across different domains. Through a taxonomy based on a transfer-approach categorization, and a characterization of works based on their data-assumption requirements, the objectives of this article are to 1) provide a comprehensive and systematic revision of knowledge transfer methods for the cross-domain RL setting, 2) categorize and characterize these methods to provide an analysis based on relevant features such as their transfer approach and data requirements, and 3) discuss the main challenges regarding cross-domain knowledge transfer, as well as ideas of future directions worth exploring to address these problems.
Read more4/30/2024
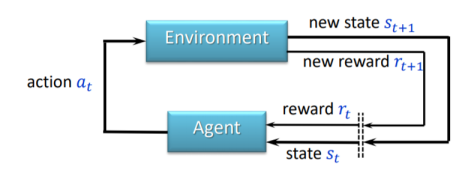
0
Exploration in Knowledge Transfer Utilizing Reinforcement Learning
Adam Jedliv{c}ka, Tatiana Valentine Guy
The contribution focuses on the problem of exploration within the task of knowledge transfer. Knowledge transfer refers to the useful application of the knowledge gained while learning the source task in the target task. The intended benefit of knowledge transfer is to speed up the learning process of the target task. The article aims to compare several exploration methods used within a deep transfer learning algorithm, particularly Deep Target Transfer $Q$-learning. The methods used are $epsilon$-greedy, Boltzmann, and upper confidence bound exploration. The aforementioned transfer learning algorithms and exploration methods were tested on the virtual drone problem. The results have shown that the upper confidence bound algorithm performs the best out of these options. Its sustainability to other applications is to be checked.
Read more7/16/2024

0
Towards the Transferability of Rewards Recovered via Regularized Inverse Reinforcement Learning
Andreas Schlaginhaufen, Maryam Kamgarpour
Inverse reinforcement learning (IRL) aims to infer a reward from expert demonstrations, motivated by the idea that the reward, rather than the policy, is the most succinct and transferable description of a task [Ng et al., 2000]. However, the reward corresponding to an optimal policy is not unique, making it unclear if an IRL-learned reward is transferable to new transition laws in the sense that its optimal policy aligns with the optimal policy corresponding to the expert's true reward. Past work has addressed this problem only under the assumption of full access to the expert's policy, guaranteeing transferability when learning from two experts with the same reward but different transition laws that satisfy a specific rank condition [Rolland et al., 2022]. In this work, we show that the conditions developed under full access to the expert's policy cannot guarantee transferability in the more practical scenario where we have access only to demonstrations of the expert. Instead of a binary rank condition, we propose principal angles as a more refined measure of similarity and dissimilarity between transition laws. Based on this, we then establish two key results: 1) a sufficient condition for transferability to any transition laws when learning from at least two experts with sufficiently different transition laws, and 2) a sufficient condition for transferability to local changes in the transition law when learning from a single expert. Furthermore, we also provide a probably approximately correct (PAC) algorithm and an end-to-end analysis for learning transferable rewards from demonstrations of multiple experts.
Read more6/5/2024