LAB-Bench: Measuring Capabilities of Language Models for Biology Research

0

Sign in to get full access
Overview
- This paper introduces LAB-Bench, a benchmark for evaluating the capabilities of language models in the context of biology research.
- LAB-Bench consists of a suite of tasks that assess a model's ability to understand and reason about biological concepts, perform common research tasks, and engage in open-ended scientific inquiry.
- The paper describes the design and implementation of LAB-Bench, as well as the results of evaluating several large language models on the benchmark.
Plain English Explanation
LAB-Bench is a tool that helps researchers understand how well language models, like the ones used in chatbots and virtual assistants, can handle tasks related to biology research. The benchmark includes a variety of tests that measure the model's knowledge of biological concepts, its ability to perform common research activities, and its capacity for open-ended scientific reasoning.
The goal is to provide a standardized way to assess the capabilities of these models, which are increasingly being used in scientific fields. By evaluating how well the models perform on LAB-Bench, researchers can better understand the strengths and limitations of the technology and how it might be applied in biology research.
Technical Explanation
The paper introduces the LAB-Bench benchmark, which is designed to measure the capabilities of large language models in the context of biology research. LAB-Bench consists of a suite of tasks that assess the model's understanding of biological concepts, its ability to perform common research activities, and its capacity for open-ended scientific inquiry.
The benchmark includes tasks such as [link to ScienceBench paper], [link to CS-Bench paper], [link to CityBench paper], [link to CLIBench paper], and [link to Evaluating Large Language Models with Human Feedback paper]. These tasks cover a wide range of skills, from answering factual questions about biology to designing experiments and interpreting research findings.
The authors evaluated several large language models on the LAB-Bench tasks, including GPT-3, BERT, and ERNIE. The results provide insights into the current strengths and limitations of these models in the domain of biology research, and highlight areas where further development and research may be needed.
Critical Analysis
The LAB-Bench benchmark represents an important step in evaluating the capabilities of language models for use in scientific research. By providing a standardized set of tasks and metrics, the authors have created a valuable tool for researchers to assess the performance of these models and identify areas for improvement.
However, the paper acknowledges several limitations of the benchmark. For example, the tasks may not capture all the relevant skills and knowledge required for successful biology research, and the evaluation may not fully reflect the real-world challenges and complexities of scientific work. Additionally, the performance of the language models on LAB-Bench may not directly translate to their effectiveness in actual research settings.
Further research and experimentation will be needed to fully understand the potential and limitations of language models in the context of biology research. Continued development and testing of LAB-Bench, as well as the exploration of complementary evaluation approaches, could help address these challenges and provide a more comprehensive understanding of the capabilities of these models.
Conclusion
The LAB-Bench benchmark represents an important step in evaluating the potential of large language models for use in biology research. By providing a standardized set of tasks and metrics, the benchmark offers a valuable tool for assessing the current strengths and limitations of these models in the domain of scientific inquiry.
The results of the evaluation presented in the paper offer insights into the current state of language model capabilities, as well as areas for further development and research. As these technologies continue to evolve, tools like LAB-Bench will be instrumental in ensuring that they are effectively leveraged to support and advance scientific discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D. White, Samuel G. Rodriques
There is widespread optimism that frontier Large Language Models (LLMs) and LLM-augmented systems have the potential to rapidly accelerate scientific discovery across disciplines. Today, many benchmarks exist to measure LLM knowledge and reasoning on textbook-style science questions, but few if any benchmarks are designed to evaluate language model performance on practical tasks required for scientific research, such as literature search, protocol planning, and data analysis. As a step toward building such benchmarks, we introduce the Language Agent Biology Benchmark (LAB-Bench), a broad dataset of over 2,400 multiple choice questions for evaluating AI systems on a range of practical biology research capabilities, including recall and reasoning over literature, interpretation of figures, access and navigation of databases, and comprehension and manipulation of DNA and protein sequences. Importantly, in contrast to previous scientific benchmarks, we expect that an AI system that can achieve consistently high scores on the more difficult LAB-Bench tasks would serve as a useful assistant for researchers in areas such as literature search and molecular cloning. As an initial assessment of the emergent scientific task capabilities of frontier language models, we measure performance of several against our benchmark and report results compared to human expert biology researchers. We will continue to update and expand LAB-Bench over time, and expect it to serve as a useful tool in the development of automated research systems going forward. A public subset of LAB-Bench is available for use at the following URL: https://huggingface.co/datasets/futurehouse/lab-bench
Read more7/18/2024
💬
0
BattleAgentBench: A Benchmark for Evaluating Cooperation and Competition Capabilities of Language Models in Multi-Agent Systems
Wei Wang, Dan Zhang, Tao Feng, Boyan Wang, Jie Tang
Large Language Models (LLMs) are becoming increasingly powerful and capable of handling complex tasks, e.g., building single agents and multi-agent systems. Compared to single agents, multi-agent systems have higher requirements for the collaboration capabilities of language models. Many benchmarks are proposed to evaluate their collaborative abilities. However, these benchmarks lack fine-grained evaluations of LLM collaborative capabilities. Additionally, multi-agent collaborative and competitive scenarios are ignored in existing works. To address these two problems, we propose a benchmark, called BattleAgentBench, which defines seven sub-stages of three varying difficulty levels and conducts a fine-grained evaluation of language models in terms of single-agent scenario navigation capabilities, paired-agent task execution abilities, and multi-agent collaboration and competition capabilities. We conducted extensive evaluations on leading four closed-source and seven open-source models. Experimental results indicate that API-based models perform excellently on simple tasks but open-source small models struggle with simple tasks. Regarding difficult tasks that require collaborative and competitive abilities, although API-based models have demonstrated some collaborative capabilities, there is still enormous room for improvement.
Read more8/29/2024
💬
1
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, Wei Wang
Most of the existing Large Language Model (LLM) benchmarks on scientific problem reasoning focus on problems grounded in high-school subjects and are confined to elementary algebraic operations. To systematically examine the reasoning capabilities required for solving complex scientific problems, we introduce an expansive benchmark suite SciBench for LLMs. SciBench contains a carefully curated dataset featuring a range of collegiate-level scientific problems from mathematics, chemistry, and physics domains. Based on the dataset, we conduct an in-depth benchmarking study of representative open-source and proprietary LLMs with various prompting strategies. The results reveal that the current LLMs fall short of delivering satisfactory performance, with the best overall score of merely 43.22%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms the others and some strategies that demonstrate improvements in certain problem-solving skills could result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.
Read more7/1/2024
0
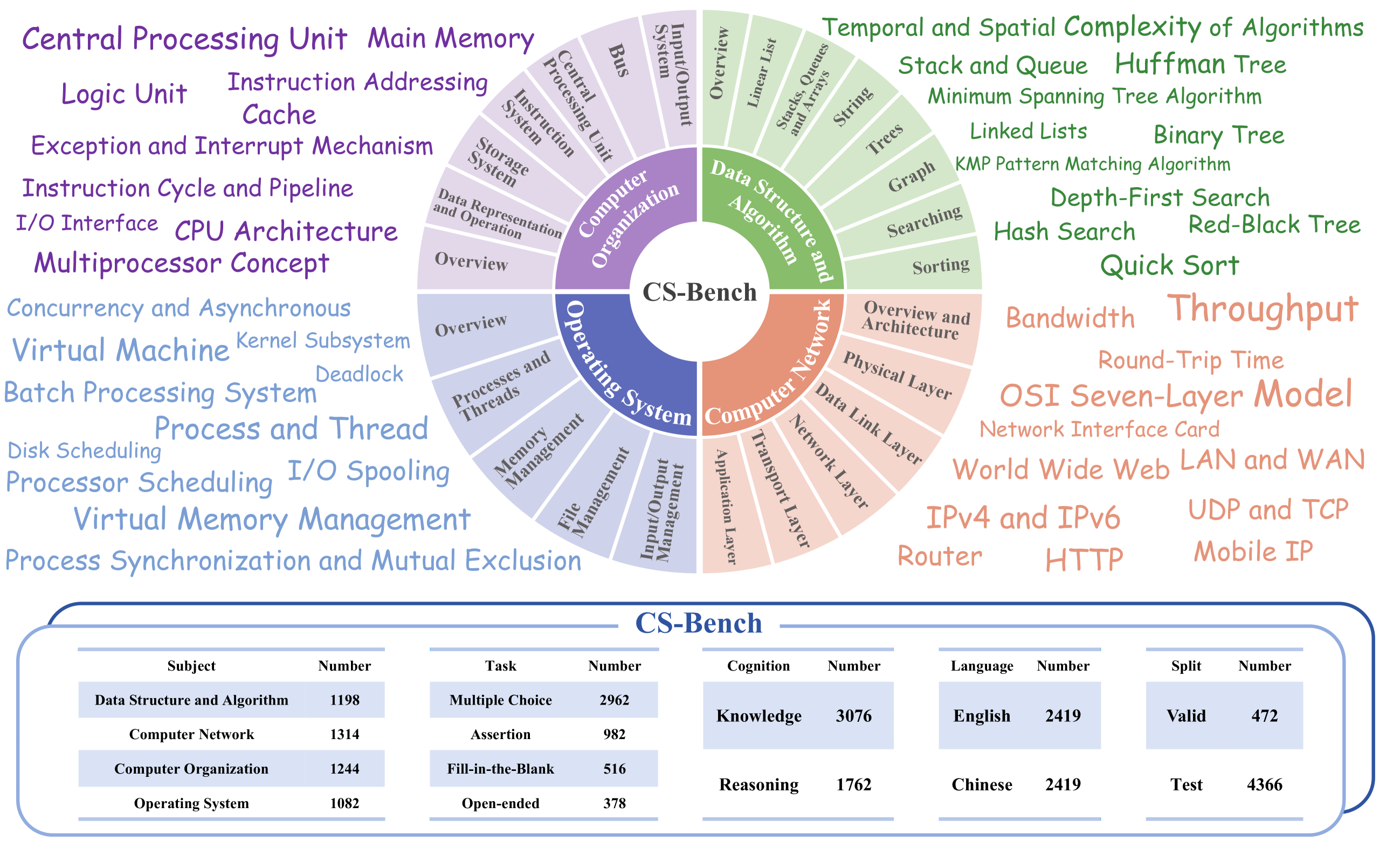
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024