CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
2406.08587
0
0
Abstract
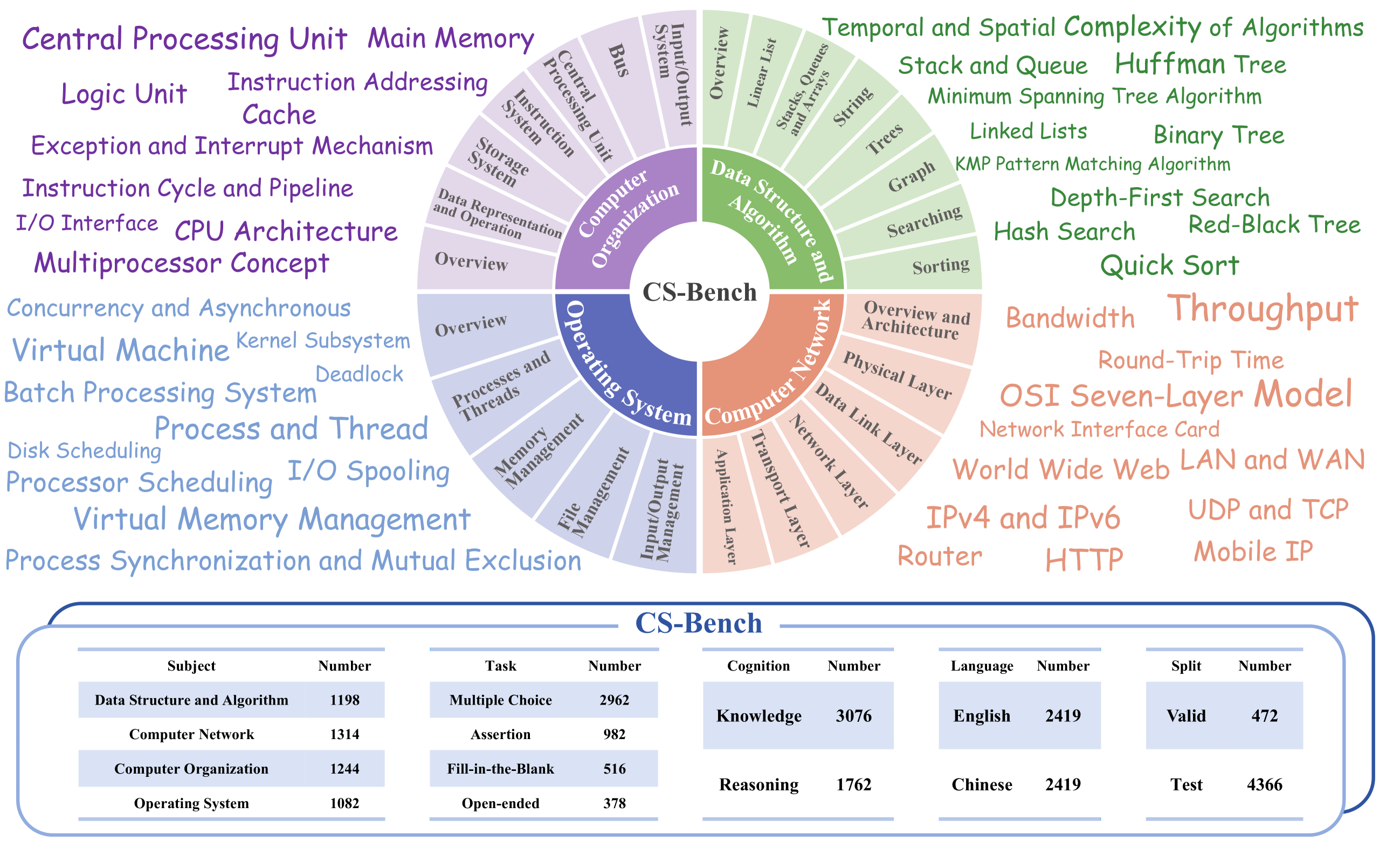
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Create account to get full access
Overview
- CS-Bench is a comprehensive benchmark designed to evaluate the capabilities of large language models (LLMs) in the computer science domain.
- It covers a wide range of topics, including algorithms, data structures, programming, machine learning, and software engineering.
- CS-Bench aims to assess how well LLMs can understand, reason about, and apply computer science concepts, which is crucial for their deployment in real-world applications.
Plain English Explanation
CS-Bench is a tool that helps researchers and developers measure how well large language models (LLMs) understand and apply computer science knowledge. LLMs are AI systems that can generate human-like text, and they're becoming increasingly important in various applications. However, it's not always clear how well they can handle tasks related to computer science, which is a complex and technical field.
That's where CS-Bench comes in. It's a collection of different tests or "benchmarks" that cover a wide range of computer science topics, such as algorithms, data structures, programming, machine learning, and software engineering. By running LLMs through these tests, researchers can get a better idea of how well the models can understand and apply computer science concepts.
This is important because if LLMs are going to be used in real-world applications that involve computer science, they need to be able to handle these tasks well. For example, if an LLM is going to be used to help write code or analyze software, it needs to have a strong understanding of programming and software engineering principles.
By using CS-Bench, researchers can identify the strengths and weaknesses of different LLMs when it comes to computer science, and then use that information to improve the models or develop new ones that are better suited for these types of tasks.
Technical Explanation
CS-Bench is a comprehensive benchmark designed to evaluate the computer science capabilities of large language models (LLMs). The benchmark covers a wide range of topics, including algorithms, data structures, programming, machine learning, and software engineering.
The benchmark is structured as a set of tasks, each of which tests a specific aspect of computer science knowledge and reasoning. These tasks include answering multiple-choice questions, solving coding problems, and explaining computer science concepts. The tasks are designed to be challenging and to cover a broad range of difficulty levels, from introductory to advanced.
To evaluate the performance of an LLM on CS-Bench, the model is first fine-tuned on a large corpus of computer science literature, including textbooks, research papers, and online resources. The fine-tuned model is then tested on the CS-Bench tasks, and its performance is measured using a variety of metrics, such as accuracy, F1 score, and task completion time.
The researchers who developed CS-Bench have used it to evaluate several state-of-the-art LLMs, including GPT-3, BERT, and T5. Their results show that while these models can perform reasonably well on some computer science tasks, they still struggle with more complex and specialized tasks, such as solving coding problems or explaining advanced concepts.
The researchers argue that the development of LLMs with stronger computer science capabilities is crucial for their successful deployment in real-world applications, such as software engineering, data analysis, and scientific research. By using CS-Bench as a benchmark, they hope to spur further research and development in this direction.
Critical Analysis
The CS-Bench benchmark is a valuable contribution to the field of large language model (LLM) evaluation, as it addresses a critical gap in the assessment of these models' capabilities in the computer science domain. The comprehensive coverage of topics and the inclusion of both conceptual and practical tasks are particularly noteworthy.
However, the researchers acknowledge several limitations of the benchmark. First, the tasks in CS-Bench may not fully capture the nuances and challenges of real-world computer science problems, which often involve complex interdependencies and contextual factors. Additionally, the benchmark may not be able to assess the LLMs' ability to learn and apply new computer science concepts over time, as the tasks are primarily based on fixed datasets.
Another potential limitation is the reliance on fine-tuning the LLMs on a specific corpus of computer science literature. While this approach helps to assess the models' abilities in the target domain, it may not reflect their performance in more open-ended or cross-domain scenarios, where they may need to draw on a broader range of knowledge and reasoning skills.
Furthermore, the researchers' findings that existing state-of-the-art LLMs struggle with more complex and specialized computer science tasks suggest that significant advancements in model architecture, training, and evaluation methodologies may be necessary to achieve true computer science mastery. Addressing these challenges will likely require interdisciplinary collaboration between computer scientists, linguists, and AI researchers.
Conclusion
CS-Bench is a comprehensive benchmark that aims to evaluate the computer science capabilities of large language models (LLMs). By covering a wide range of topics, from algorithms and data structures to machine learning and software engineering, the benchmark provides a robust and holistic assessment of these models' understanding and reasoning abilities in the computer science domain.
The benchmark's development and application have already yielded valuable insights, showing that while existing state-of-the-art LLMs can perform reasonably well on some computer science tasks, they still struggle with more complex and specialized challenges. These findings underscore the need for continued research and development to create LLMs that can truly master computer science concepts and apply them effectively in real-world applications.
As the field of AI continues to evolve, benchmarks like CS-Bench will play a crucial role in guiding the development of more capable and versatile language models, ultimately paving the way for their broader deployment in scientific, engineering, and other knowledge-intensive domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

C$^{3}$Bench: A Comprehensive Classical Chinese Understanding Benchmark for Large Language Models
Jiahuan Cao, Yongxin Shi, Dezhi Peng, Yang Liu, Lianwen Jin
0
0
Classical Chinese Understanding (CCU) holds significant value in preserving and exploration of the outstanding traditional Chinese culture. Recently, researchers have attempted to leverage the potential of Large Language Models (LLMs) for CCU by capitalizing on their remarkable comprehension and semantic capabilities. However, no comprehensive benchmark is available to assess the CCU capabilities of LLMs. To fill this gap, this paper introduces C$^{3}$bench, a Comprehensive Classical Chinese understanding benchmark, which comprises 50,000 text pairs for five primary CCU tasks, including classification, retrieval, named entity recognition, punctuation, and translation. Furthermore, the data in C$^{3}$bench originates from ten different domains, covering most of the categories in classical Chinese. Leveraging the proposed C$^{3}$bench, we extensively evaluate the quantitative performance of 15 representative LLMs on all five CCU tasks. Our results not only establish a public leaderboard of LLMs' CCU capabilities but also gain some findings. Specifically, existing LLMs are struggle with CCU tasks and still inferior to supervised models. Additionally, the results indicate that CCU is a task that requires special attention. We believe this study could provide a standard benchmark, comprehensive baselines, and valuable insights for the future advancement of LLM-based CCU research. The evaluation pipeline and dataset are available at url{https://github.com/SCUT-DLVCLab/C3bench}.
5/31/2024

CityBench: Evaluating the Capabilities of Large Language Model as World Model
Jie Feng, Jun Zhang, Junbo Yan, Xin Zhang, Tianjian Ouyang, Tianhui Liu, Yuwei Du, Siqi Guo, Yong Li
0
0
Large language models (LLMs) with powerful generalization ability has been widely used in many domains. A systematic and reliable evaluation of LLMs is a crucial step in their development and applications, especially for specific professional fields. In the urban domain, there have been some early explorations about the usability of LLMs, but a systematic and scalable evaluation benchmark is still lacking. The challenge in constructing a systematic evaluation benchmark for the urban domain lies in the diversity of data and scenarios, as well as the complex and dynamic nature of cities. In this paper, we propose CityBench, an interactive simulator based evaluation platform, as the first systematic evaluation benchmark for the capability of LLMs for urban domain. First, we build CitySim to integrate the multi-source data and simulate fine-grained urban dynamics. Based on CitySim, we design 7 tasks in 2 categories of perception-understanding and decision-making group to evaluate the capability of LLMs as city-scale world model for urban domain. Due to the flexibility and ease-of-use of CitySim, our evaluation platform CityBench can be easily extended to any city in the world. We evaluate 13 well-known LLMs including open source LLMs and commercial LLMs in 13 cities around the world. Extensive experiments demonstrate the scalability and effectiveness of proposed CityBench and shed lights for the future development of LLMs in urban domain. The dataset, benchmark and source codes are openly accessible to the research community via https://github.com/tsinghua-fib-lab/CityBench
6/21/2024

MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
Hongwei Liu, Zilong Zheng, Yuxuan Qiao, Haodong Duan, Zhiwei Fei, Fengzhe Zhou, Wenwei Zhang, Songyang Zhang, Dahua Lin, Kai Chen
0
0
Recent advancements in large language models (LLMs) have showcased significant improvements in mathematics. However, traditional math benchmarks like GSM8k offer a unidimensional perspective, falling short in providing a holistic assessment of the LLMs' math capabilities. To address this gap, we introduce MathBench, a new benchmark that rigorously assesses the mathematical capabilities of large language models. MathBench spans a wide range of mathematical disciplines, offering a detailed evaluation of both theoretical understanding and practical problem-solving skills. The benchmark progresses through five distinct stages, from basic arithmetic to college mathematics, and is structured to evaluate models at various depths of knowledge. Each stage includes theoretical questions and application problems, allowing us to measure a model's mathematical proficiency and its ability to apply concepts in practical scenarios. MathBench aims to enhance the evaluation of LLMs' mathematical abilities, providing a nuanced view of their knowledge understanding levels and problem solving skills in a bilingual context. The project is released at https://github.com/open-compass/MathBench .
5/21/2024

FoundaBench: Evaluating Chinese Fundamental Knowledge Capabilities of Large Language Models
Wei Li, Ren Ma, Jiang Wu, Chenya Gu, Jiahui Peng, Jinyang Len, Songyang Zhang, Hang Yan, Dahua Lin, Conghui He
0
0
In the burgeoning field of large language models (LLMs), the assessment of fundamental knowledge remains a critical challenge, particularly for models tailored to Chinese language and culture. This paper introduces FoundaBench, a pioneering benchmark designed to rigorously evaluate the fundamental knowledge capabilities of Chinese LLMs. FoundaBench encompasses a diverse array of 3354 multiple-choice questions across common sense and K-12 educational subjects, meticulously curated to reflect the breadth and depth of everyday and academic knowledge. We present an extensive evaluation of 12 state-of-the-art LLMs using FoundaBench, employing both traditional assessment methods and our CircularEval protocol to mitigate potential biases in model responses. Our results highlight the superior performance of models pre-trained on Chinese corpora, and reveal a significant disparity between models' reasoning and memory recall capabilities. The insights gleaned from FoundaBench evaluations set a new standard for understanding the fundamental knowledge of LLMs, providing a robust framework for future advancements in the field.
4/30/2024