LAB: Large-Scale Alignment for ChatBots
2403.01081
0
0

Abstract
This work introduces LAB (Large-scale Alignment for chatBots), a novel methodology designed to overcome the scalability challenges in the instruction-tuning phase of large language model (LLM) training. Leveraging a taxonomy-guided synthetic data generation process and a multi-phase tuning framework, LAB significantly reduces reliance on expensive human annotations and proprietary models like GPT-4. We demonstrate that LAB-trained models can achieve competitive performance across several benchmarks compared to models trained with traditional human-annotated or GPT-4 generated synthetic data. Thus offering a scalable, cost-effective solution for enhancing LLM capabilities and instruction-following behaviors without the drawbacks of catastrophic forgetting, marking a step forward in the efficient training of LLMs for a wide range of applications.
Create account to get full access
Overview
- Presents a large-scale alignment methodology for chatbots, called LAB (Large-scale Alignment for Bots)
- Aims to create chatbots that are more aligned with human values and preferences
- Focuses on aligning the language model behind the chatbot, rather than just the task-specific fine-tuning
Plain English Explanation
The paper describes a new approach called LAB (Large-scale Alignment for Bots) that can be used to create chatbots that are better aligned with human values and preferences. The key idea is to focus on aligning the underlying language model that powers the chatbot, rather than just fine-tuning the model for specific tasks.
By aligning the language model itself, the chatbot can learn to communicate in a way that is more consistent with human values, even when having open-ended conversations. This is important because as chatbots become more advanced, it's crucial that they behave in a way that is beneficial and aligned with what humans want, rather than potentially harmful or misaligned.
The paper builds on recent advances in Sambalingo: Teaching Large Language Models New Languages, AnnOLLM: Making Large Language Models to be Aligned, and other related research in the field of AI alignment.
Technical Explanation
The LAB methodology involves several key steps:
- Pretraining: The language model is first pretrained on a large corpus of text data, similar to how models like GPT-3 are trained.
- Alignment: The model is then further trained using an alignment process that incentivizes the model to behave in ways that are more aligned with human values and preferences. This might involve techniques like ChatGLM: RLHF Practices for Aligning Large Language Models or CodeCLM: Aligning Language Models with Tailored Synthetic Data.
- Evaluation: The aligned model is then evaluated on a range of tasks and conversations to assess its degree of alignment with human values.
The paper presents the results of applying the LAB methodology to create an aligned chatbot, and compares its performance to baseline chatbots that have not undergone the alignment process.
Critical Analysis
The paper presents a promising approach for creating more aligned chatbots, but there are a few potential limitations and areas for further research:
- The alignment process can be complex and computationally intensive, which may make it challenging to scale to very large language models.
- The paper does not explore how the aligned chatbot would perform in open-ended, real-world conversations, where unpredictable situations may arise.
- The evaluation metrics used in the paper may not fully capture all aspects of value alignment, and there could be additional ways to assess the chatbot's behavior.
Further research could explore ways to make the alignment process more efficient, as well as develop more comprehensive evaluation frameworks to assess the degree of value alignment in chatbots. Additionally, zero-shot and few-shot studies on instruction-following may provide insights into how to better align chatbots with human preferences.
Conclusion
The LAB methodology presented in this paper represents an important step towards creating chatbots that are more aligned with human values and preferences. By focusing on aligning the underlying language model, rather than just fine-tuning for specific tasks, the researchers have developed a approach that could lead to more beneficial and trustworthy chatbots as the technology continues to advance.
While there are still some challenges to overcome, this research contributes to the growing field of AI alignment and highlights the importance of ensuring that powerful language models are developed in a way that is consistent with human values and priorities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SambaLingo: Teaching Large Language Models New Languages
Zoltan Csaki, Bo Li, Jonathan Li, Qiantong Xu, Pian Pawakapan, Leon Zhang, Yun Du, Hengyu Zhao, Changran Hu, Urmish Thakker
0
0
Despite the widespread availability of LLMs, there remains a substantial gap in their capabilities and availability across diverse languages. One approach to address these issues has been to take an existing pre-trained LLM and continue to train it on new languages. While prior works have experimented with language adaptation, many questions around best practices and methodology have not been covered. In this paper, we present a comprehensive investigation into the adaptation of LLMs to new languages. Our study covers the key components in this process, including vocabulary extension, direct preference optimization and the data scarcity problem for human alignment in low-resource languages. We scale these experiments across 9 languages and 2 parameter scales (7B and 70B). We compare our models against Llama 2, Aya-101, XGLM, BLOOM and existing language experts, outperforming all prior published baselines. Additionally, all evaluation code and checkpoints are made public to facilitate future research.
4/10/2024
🖼️
Aligners: Decoupling LLMs and Alignment
Lilian Ngweta, Mayank Agarwal, Subha Maity, Alex Gittens, Yuekai Sun, Mikhail Yurochkin
0
0
Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We use the same synthetic data to train inspectors, binary miss-alignment classification models to guide a squad of multiple aligners. Our empirical results demonstrate consistent improvements when applying aligner squad to various LLMs, including chat-aligned models, across several instruction-following and red-teaming datasets.
6/18/2024
🏋️
Hybrid Alignment Training for Large Language Models
Chenglong Wang, Hang Zhou, Kaiyan Chang, Bei Li, Yongyu Mu, Tong Xiao, Tongran Liu, Jingbo Zhu
0
0
Alignment training is crucial for enabling large language models (LLMs) to cater to human intentions and preferences. It is typically performed based on two stages with different objectives: instruction-following alignment and human-preference alignment. However, aligning LLMs with these objectives in sequence suffers from an inherent problem: the objectives may conflict, and the LLMs cannot guarantee to simultaneously align with the instructions and human preferences well. To response to these, in this work, we propose a Hybrid Alignment Training (Hbat) approach, based on alternating alignment and modified elastic weight consolidation methods. The basic idea is to alternate between different objectives during alignment training, so that better collaboration can be achieved between the two alignment tasks.We experiment with Hbat on summarization and dialogue tasks. Experimental results show that the proposed textsc{Hbat} can significantly outperform all baselines. Notably, Hbat yields consistent performance gains over the traditional two-stage alignment training when using both proximal policy optimization and direct preference optimization.
6/24/2024
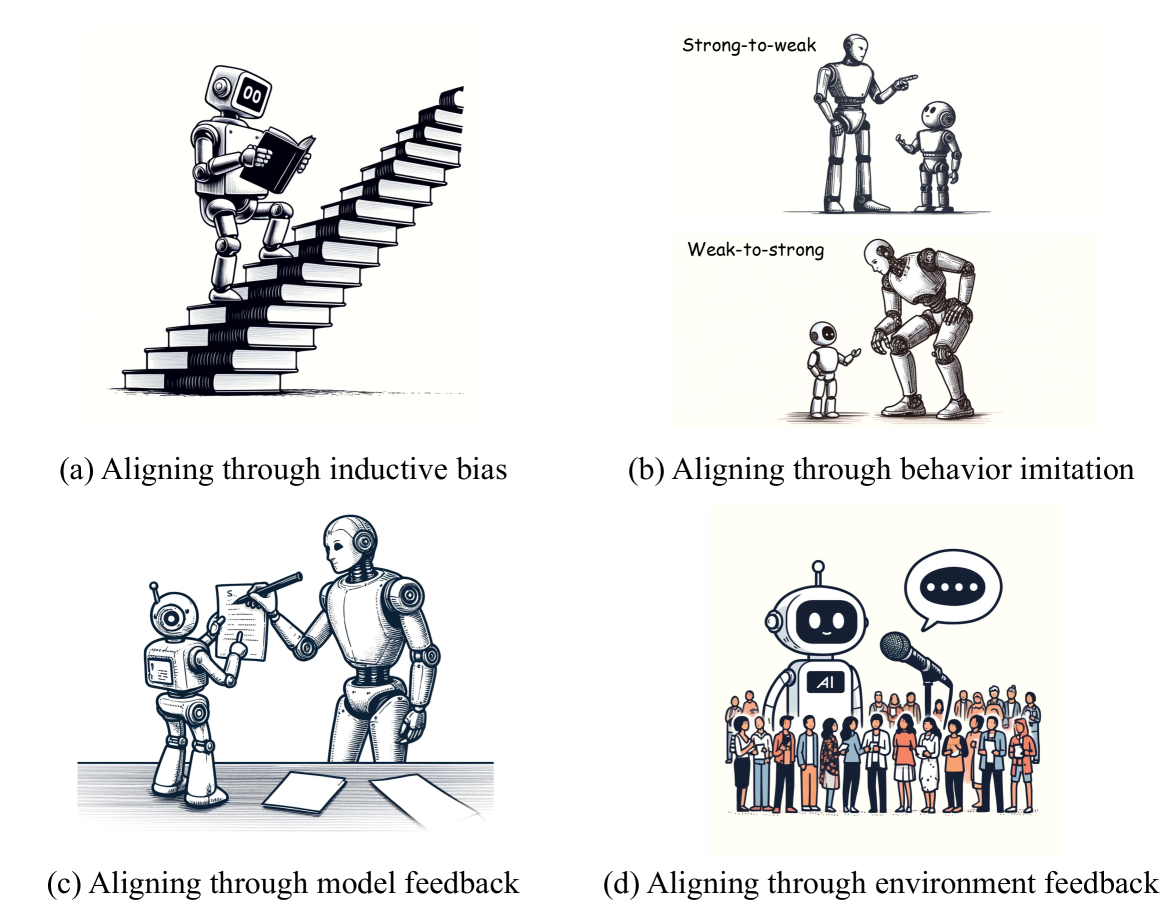
Towards Scalable Automated Alignment of LLMs: A Survey
Boxi Cao, Keming Lu, Xinyu Lu, Jiawei Chen, Mengjie Ren, Hao Xiang, Peilin Liu, Yaojie Lu, Ben He, Xianpei Han, Le Sun, Hongyu Lin, Bowen Yu
0
0
Alignment is the most critical step in building large language models (LLMs) that meet human needs. With the rapid development of LLMs gradually surpassing human capabilities, traditional alignment methods based on human-annotation are increasingly unable to meet the scalability demands. Therefore, there is an urgent need to explore new sources of automated alignment signals and technical approaches. In this paper, we systematically review the recently emerging methods of automated alignment, attempting to explore how to achieve effective, scalable, automated alignment once the capabilities of LLMs exceed those of humans. Specifically, we categorize existing automated alignment methods into 4 major categories based on the sources of alignment signals and discuss the current status and potential development of each category. Additionally, we explore the underlying mechanisms that enable automated alignment and discuss the essential factors that make automated alignment technologies feasible and effective from the fundamental role of alignment.
6/4/2024